Nvidia Patents a System That Makes Fake Objects Look Lit From the Same Sky as the Real Scene
Getting a computer-generated car or pedestrian to look like it genuinely belongs in a real photograph is harder than it sounds — shadows, highlights, and reflected light all have to match. Nvidia's new patent describes a system that figures out where the light is coming from in a real scene and then applies that same lighting to any virtual object dropped into it.
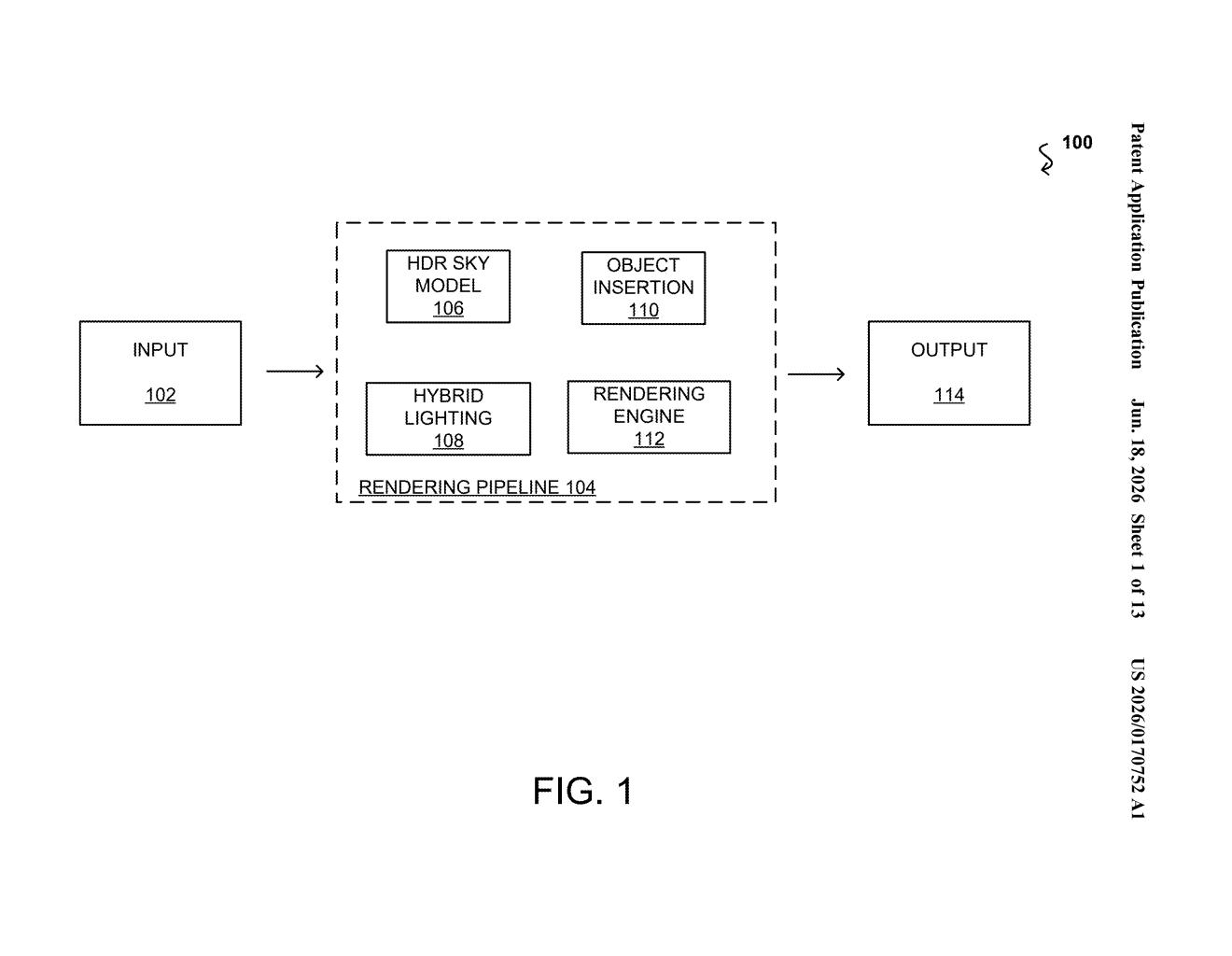
How Nvidia fakes lighting to make virtual objects look real
Imagine you want to train a self-driving car's AI using photos of real streets, but you need thousands of examples showing pedestrians in unusual situations — ones a camera crew could never safely film. The solution is to paste in virtual, computer-generated pedestrians. The problem? Those fake figures look fake because the light hitting them doesn't match the light in the rest of the photo.
Nvidia's patent describes a way to fix that. It uses neural networks to read a real photo and build a detailed map of how light behaves in that scene — accounting for the sun or sky in the background and the more subtle, local reflections bouncing off nearby buildings, cars, or walls. That map is then applied to any virtual object you want to insert, so shadows fall in the right direction and surfaces catch the right color of light.
The result is synthetic training images that look much closer to the real thing — which matters a lot when the AI you're training needs to recognize objects across all kinds of lighting conditions.
How the hybrid sky-and-scene lighting model is built
The system builds what Nvidia calls a hybrid lighting representation — essentially two layers of lighting information combined into one model. The first layer captures the sky: the sun's position, cloud cover, and the broad directional light that falls over an entire scene. The second layer is a volumetric lighting representation — a three-dimensional map (think of it like an invisible grid of light values hanging over the scene) that captures how local objects like buildings, cars, and pavement reflect and absorb light in ways that vary from spot to spot.
One or more neural networks analyze the input image to compute both layers simultaneously. Once the hybrid model is ready, a light transport simulation algorithm (a method that mathematically traces how light rays travel and bounce through a scene, similar to how ray-tracing works in video games) uses it to render a virtual object with physically accurate shading and shadows.
The rendered virtual object is then composited back into the original image to produce an augmented image — a photo that looks like it always contained that object. The whole pipeline is described as differentiable, meaning the neural networks can be trained end-to-end by comparing the output to real data and adjusting to improve accuracy over time.
The explicit target use case, per the patent, is synthetic data generation — producing large volumes of realistic-looking labeled images to train other AI models without requiring expensive real-world photography.
What this means for AI training data and autonomous vehicles
Training AI for autonomous driving, robotics, or surveillance requires enormous amounts of labeled image data covering rare or dangerous scenarios. Generating that data synthetically is far cheaper and safer — but only if the synthetic images are convincing enough that an AI trained on them can still recognize objects in the real world. Poor lighting realism is one of the main ways synthetic data fails that test. A system that accurately reconstructs real-world lighting from a single photo closes a meaningful gap.
For Nvidia, which sells both the GPUs used to train AI models and the Omniverse platform for synthetic data generation, this kind of technology sits at the center of its business strategy. If your synthetic training pipeline produces images that look real enough, customers need fewer expensive real-world data collection runs — and they need more of Nvidia's compute to generate the synthetic scenes instead.
This is genuinely useful foundational work for the synthetic data pipeline that autonomous vehicle and robotics companies depend on. Lighting mismatch is a well-known failure mode for sim-to-real AI transfer, and a neural-network-based approach that handles both global sky illumination and local volumetric effects in one pass is a meaningful step forward. It's not flashy consumer technology, but it's the kind of infrastructure patent that quietly makes a lot of downstream products more reliable.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.