Nvidia Patents a System That Builds Task-Specific AI Models from One Unified Network
What if you could train dozens of specialized AI models and then collapse them all into a single network — pulling out whichever one you need at inference time? That's exactly what this Nvidia patent describes.
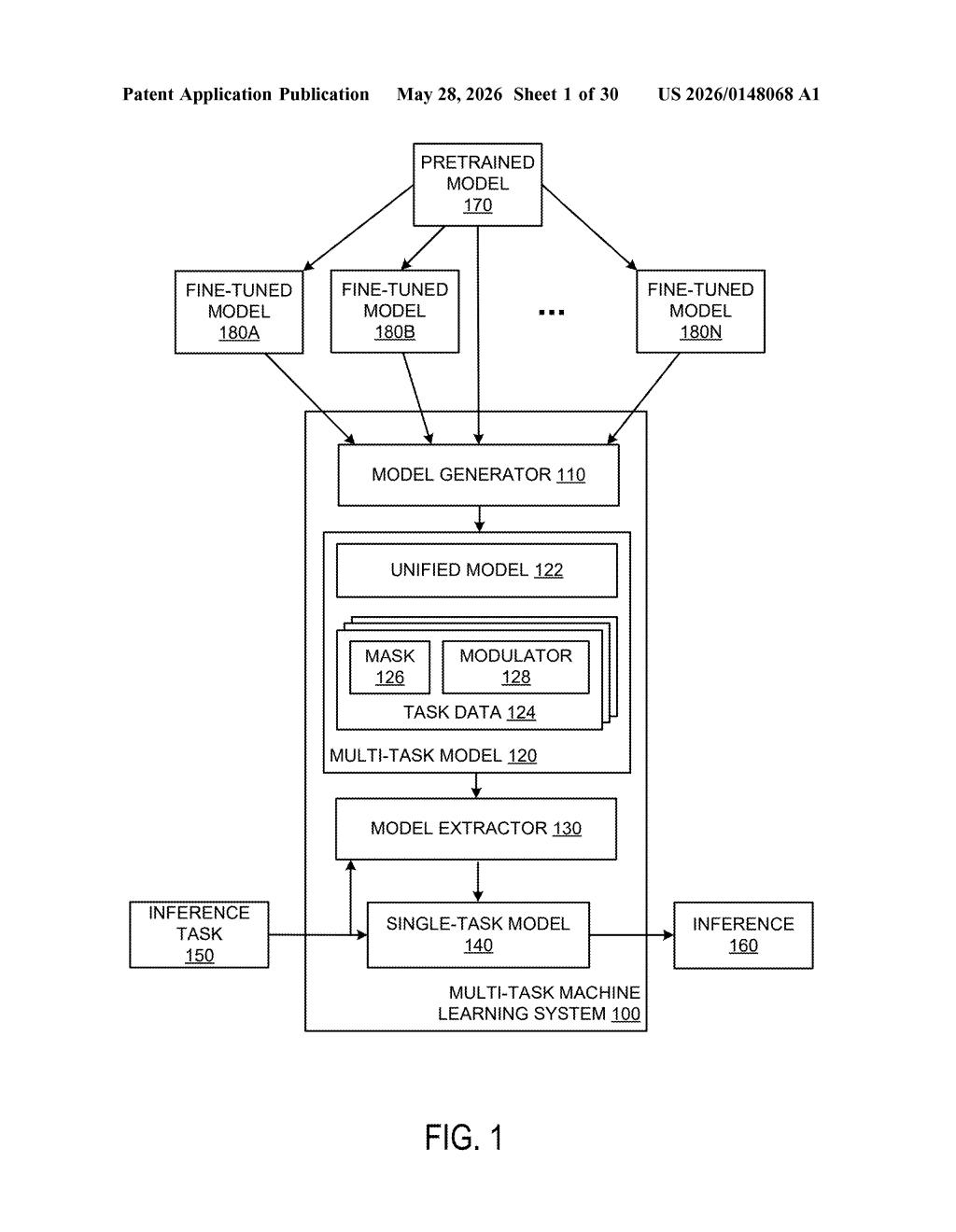
How Nvidia packs many AI models into one unified network
Imagine you run a company that uses AI for three different jobs: detecting defects in photos, transcribing audio, and classifying customer emails. Normally, you'd need three separate AI models sitting in memory, each trained independently. That's expensive and wasteful.
Nvidia's patent describes a way to train all those task-specific models and then compress them into a single unified model. When you actually need to run a task, the system pulls out — or reconstructs — just the right sub-model for that job, on the fly.
The trick is a "modulator" that selectively masks parts of the unified network, hiding the weights that aren't relevant to your current task and exposing only the ones that are. The result is that one model can behave like many, without carrying the full memory and compute cost of running them all separately.
How the modulator masks and extracts task-specific weights
The system starts with a pre-trained base model — think of it as a general-purpose AI foundation, like a large language model or a vision transformer. From there, multiple task-specific versions are created by fine-tuning (a process of continuing to train the model on task-specific data until it specializes).
Instead of keeping all those fine-tuned models around separately, a component called the Model Generator merges them into a single Unified Model. This unified model encodes the knowledge of all the task-specific variants simultaneously.
At inference time — when you actually want to run a prediction — the system uses a Modulator and a Model Extractor to reconstruct the appropriate single-task model. The core mechanism is selective masking: the processor's circuits identify which portions of the neural network are relevant to the requested task and suppress (mask) the rest, effectively carving out a lean, task-specific model from the larger unified structure.
- Pre-trained model: the shared starting point
- Fine-tuned models: task-specific variants derived from it
- Unified model: a compressed merger of all fine-tuned variants
- Modulator + Extractor: the on-demand reconstruction pipeline
What this means for deploying AI at scale on Nvidia hardware
Running multiple specialized AI models simultaneously is one of the biggest cost pressures in modern inference infrastructure. If Nvidia can make a single unified model stand in for many task-specific ones — with minimal accuracy loss — that's a meaningful reduction in memory bandwidth, VRAM usage, and chip time, all of which translate directly to dollars in a data center.
For edge deployments (robotics, autonomous vehicles, embedded vision systems), the benefit is even more direct: you get a device that can handle multiple inference tasks without needing the memory footprint of several independent models. This fits neatly into Nvidia's broader push to make inference on its hardware more efficient, and it lines up with the kind of multi-task challenges that show up in autonomous driving and industrial AI — both areas Nvidia has been aggressively targeting.
This is a genuinely clever systems-level idea: instead of treating model compression and multi-task learning as separate problems, Nvidia is combining them into a single unified-then-extract pipeline. The selective masking approach via dedicated processor circuits suggests this is meant to be implemented close to the hardware level, not just as a software framework trick. Worth watching — especially if it surfaces in future Nvidia Inference Microservices (NIM) or Jetson platform updates.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.