Nvidia Patents an Unsupervised AI That Finds Network Topology Anomalies
What if your network could spot its own wiring mistakes — without anyone telling it what a mistake looks like? That's the core idea behind Nvidia's latest networking patent, which uses a graph-based AI model trained on part of a network to predict what the rest of it *should* look like.
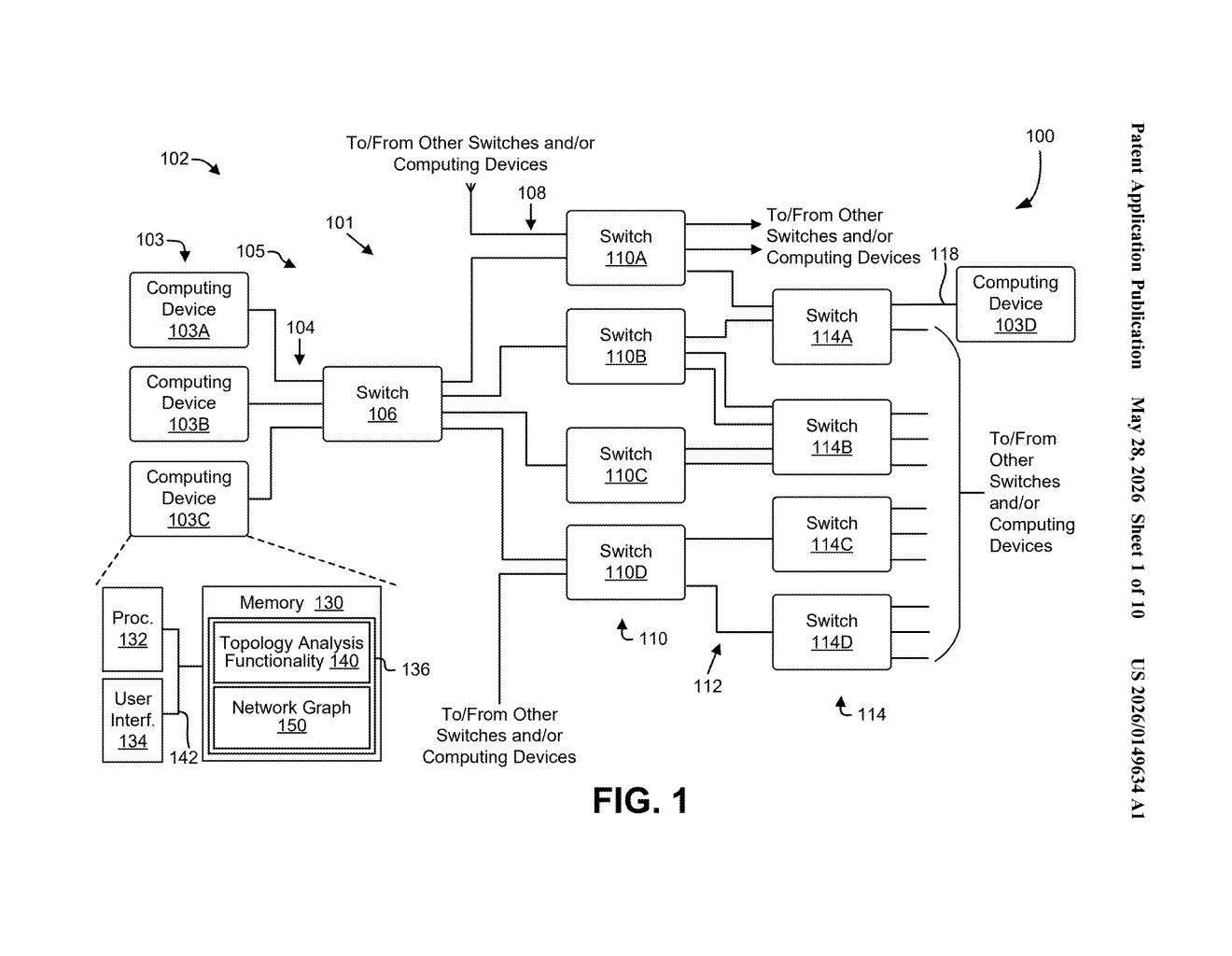
How Nvidia's self-training network anomaly detector works
Imagine you're managing a massive datacenter with thousands of switches and computing nodes, all connected in a specific pattern. A single misconfigured cable or a missing link could cause mysterious slowdowns or failures — and finding it manually is like searching for a needle in a haystack.
Nvidia's patent describes a system that learns the normal wiring pattern of your network by studying most of it, then uses that knowledge to predict how the remaining section should be connected. Anything that doesn't match the prediction gets flagged as a potential anomaly.
The clever part is that it's unsupervised — you don't have to label any faults ahead of time or tell the system what a bad connection looks like. It figures out normal on its own, which is a big deal when you're dealing with constantly evolving, large-scale network topologies like those inside Nvidia's own InfiniBand-based AI supercomputing clusters.
How the graph model predicts and flags missing links
The patent describes a graph-based link prediction approach to anomaly detection. The network is represented as a graph, where nodes are switches and computing devices, and edges are the physical or logical connections between them.
The system works in three steps:
- Partition: The full network graph is divided into multiple subsets — think of them as sections of the datacenter floor.
- Train: All subsets except one are used to train a prediction model. The model learns what kinds of connections are expected between node pairs, based on the structural patterns in the training data.
- Predict and compare: The trained model is then applied to the held-out subset, generating predictions about which connections should exist there. Discrepancies between predicted and actual connections surface as anomalies.
This is essentially a self-supervised link prediction task (common in graph neural network research), repurposed for infrastructure monitoring. The model doesn't need pre-labeled examples of failures — it learns topology norms from the healthy majority and uses those norms as a baseline. The patent is specifically oriented toward large-scale switched networks, consistent with Nvidia's InfiniBand and Ethernet datacenter fabrics.
What this means for AI datacenter reliability at scale
For Nvidia, whose H100 and upcoming Blackwell GPU clusters depend on ultra-low-latency, high-bandwidth interconnects, a single misconfigured switch port can degrade an entire training run. Automated topology anomaly detection at this scale — without requiring labeled fault data — is a meaningful operational capability, not just a research exercise.
More broadly, as AI infrastructure grows more complex and distributed, the tools to manage it have to keep pace. This patent positions Nvidia not just as a chip vendor but as a player in the network observability space — the kind of tooling that hyperscalers and enterprise AI operators need when running thousands of GPUs in tightly coupled clusters.
This is solid, practical engineering work aimed squarely at Nvidia's own infrastructure problem: keeping massive GPU clusters reliably wired at scale. It's not flashy AI research — it's the unglamorous plumbing that makes exascale computing actually work. If this ends up in Nvidia's networking management stack, it's the kind of quiet capability that saves operators real money and real headaches.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.