AMD Patents a System That Moves the Most-Used AI Data to Faster Storage Automatically
When an AI recommendation engine has to look up the same data over and over, making it wait each time is a pure waste. AMD's new patent describes a system that notices which data gets requested most often and moves it closer to the front of the line.
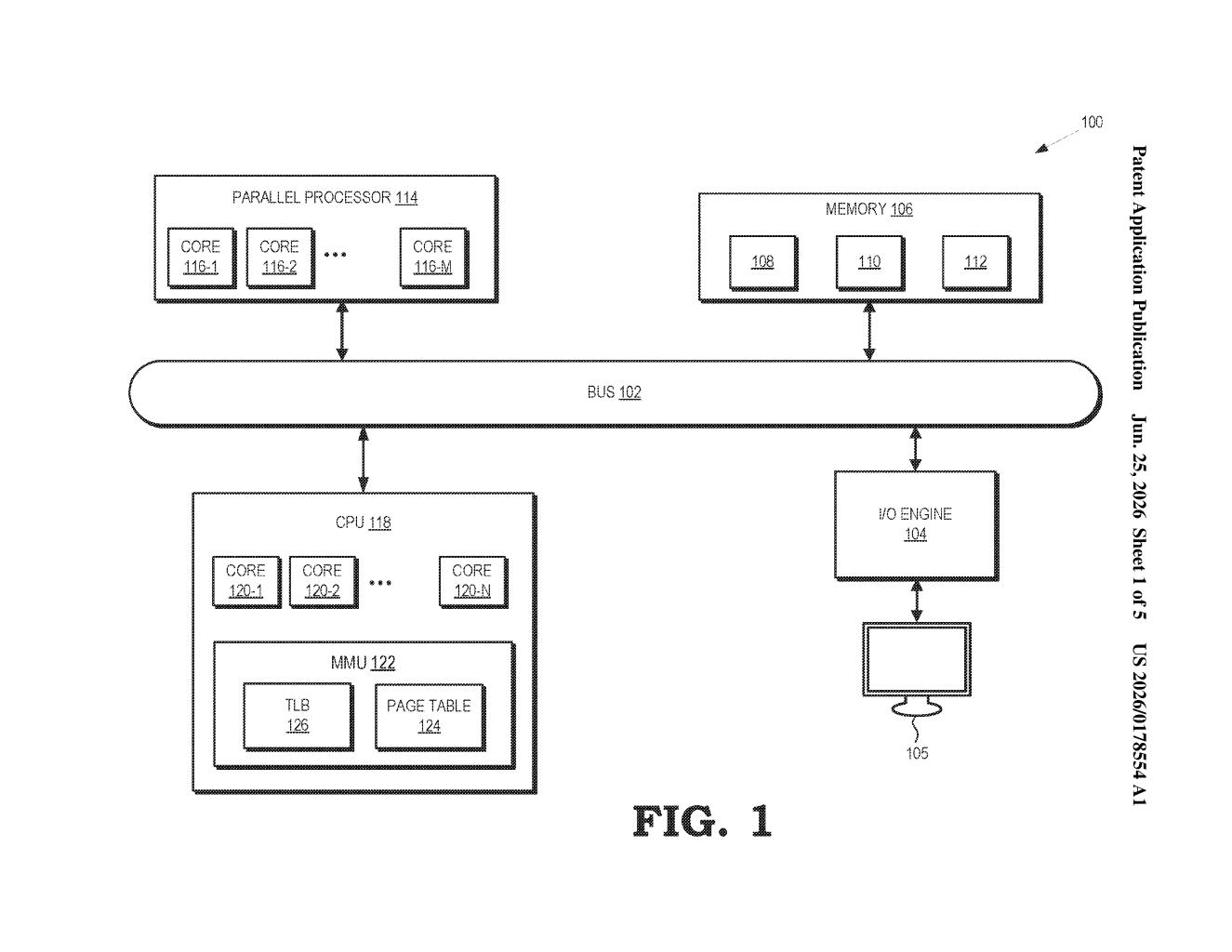
What AMD's popularity-tracking memory system actually does
Imagine a library where certain books get checked out constantly. A smart librarian would eventually move those popular books to a shelf right by the front desk instead of keeping them in the back stacks. AMD's patent applies the same idea to AI systems.
Recommendation engines (the kind that suggest what to watch on Netflix or what to buy on Amazon) rely on large tables of stored data called embedding vectors. Some entries in those tables get requested thousands of times a day; others are rarely touched. AMD's system tracks those access patterns and automatically copies the most-requested entries into a faster, more accessible second table.
A lightweight filter then acts as a traffic director, deciding in real time whether an incoming request should go to the main table or the faster one. The result is that the AI spends less time waiting on data lookups and more time actually generating recommendations for you.
How AMD ranks and routes embedding vectors between tables
The patent describes a two-table storage architecture for embedding vectors (numerical representations of things like users, products, or movies that recommendation models use to make predictions).
The first table holds all the embeddings. As requests come in, the processor updates a set of bits attached to each entry to record how popular that entry is, meaning how frequently or how likely it has been accessed recently. Think of it as a running tally attached to each row in a database.
Based on those popularity scores, a subset of high-demand entries gets copied into a second table, which can sit in faster or more convenient memory. The two tables are not exclusive: the first table remains the source of truth.
To route requests efficiently, the system uses a Bloom filter (a compact, probabilistic data structure that can answer the question "is this item in the fast table?" very quickly, with a small chance of a false positive but never a false negative). The Bloom filter acts as a gatekeeper, sending requests to the fast second table when the data is likely there, and falling back to the main table otherwise.
What this means for AI recommendation engine performance
Recommendation models at scale (think the engines behind ad targeting, content feeds, or product suggestions) are notoriously bottlenecked by memory lookups rather than raw computation. The embeddings they query can run into billions of entries, and fetching the wrong ones from slow storage adds up fast. A system that automatically identifies and promotes the busiest entries could cut those lookup delays without requiring engineers to manually tune what gets cached.
For AMD, this is also a competitive positioning move. As GPU makers compete for AI inference workloads, memory efficiency is a real differentiator. A hardware-level system that handles hot-data promotion automatically could make AMD's chips more attractive for companies running large recommendation pipelines.
This is a practical, unglamorous piece of engineering that solves a real bottleneck. Popularity-based caching is a well-understood concept in databases, but applying it at the hardware level with Bloom filter routing for AI embedding tables is a specific enough approach to matter. It's not a moonshot patent, it's the kind of filing that ends up in a shipping product.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.