Google Patents the Math That Teaches AI to Understand Words
This is a patent on word embeddings — the foundational idea that lets AI treat language as math. If you've ever used Google Search, Google Translate, or any modern AI chatbot, you've already benefited from exactly this technique.
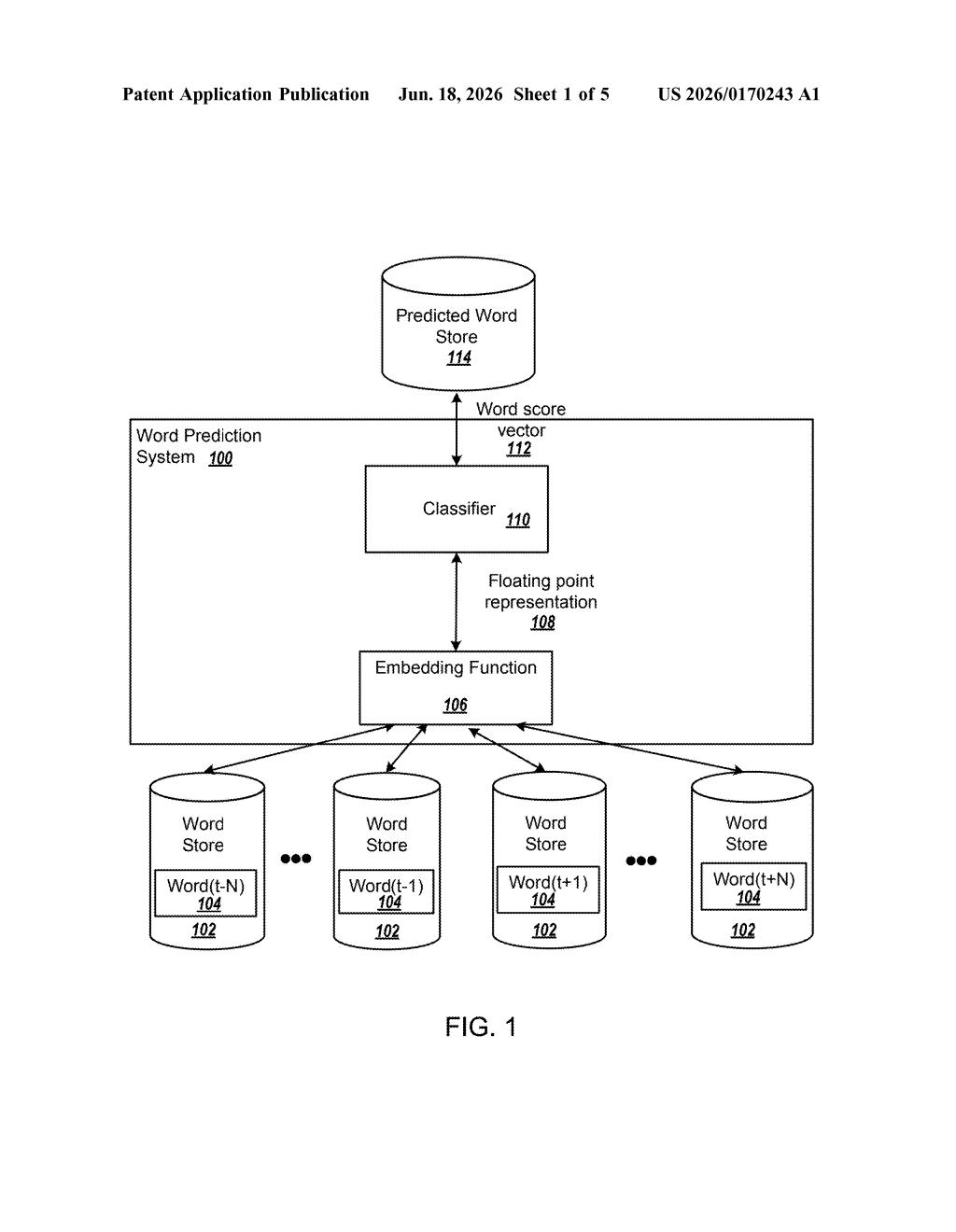
How Google turns words into numbers AI can reason with
Imagine teaching a computer that the word "king" is more similar to "queen" than it is to "banana." Computers don't naturally understand meaning — they only work with numbers. So researchers figured out how to convert every word in a language into a long list of numbers in a way that captures meaning, context, and relationships.
Google's patent covers a method for doing exactly that. You feed a system large amounts of text, train it to predict which words tend to appear near each other, and out comes a numeric "fingerprint" for every word — one that places related words closer together in a mathematical space. The word for doctor ends up near nurse, and far away from bicycle.
This technique — known publicly as Word2Vec — was published by these same Google inventors back in 2013 and became one of the most influential ideas in modern AI. The patent application is a formal legal filing around that work, listing Tomas Mikolov, Kai Chen, Greg Corrado, and Jeff Dean as inventors.
Inside Google's word-embedding training process
The patent describes a system for generating word embeddings — numeric vectors (think: long lists of numbers) that represent words in a high-dimensional mathematical space (a space with hundreds or thousands of dimensions, rather than the three we live in).
The training process works like this:
- Feed the system large sequences of text as training data.
- Train a classifier (a model that learns to predict surrounding words) alongside an embedding function (the component that converts each word into numbers).
- Once training is done, run every word in the vocabulary through the embedding function to produce its numeric representation.
- Store those representations so they can be looked up and used downstream in other AI tasks.
The key insight is that words appearing in similar contexts end up with similar numeric fingerprints. "Paris" and "Rome" land near each other; "Paris" and "wrench" do not. This means arithmetic on the numbers reflects real-world meaning — the classic example being that king − man + woman ≈ queen in the mathematical space.
The first independent claim in this filing is listed as canceled, which typically indicates the patent has been narrowed or restructured during examination.
What word embeddings mean for every AI product today
Word embeddings are the foundation of almost every language AI product built in the last decade. Before Word2Vec, getting computers to handle language required enormous hand-crafted rule systems. After it, you could feed raw text into a neural network and get something that understood meaning automatically. Every large language model today — including the ones powering ChatGPT, Google Gemini, and others — builds on this basic idea of representing words (and now tokens) as vectors in a high-dimensional space.
For you as a user, this is the invisible infrastructure behind search engines that understand your intent, translation tools that handle nuance, and AI assistants that don't just match keywords but grasp what you're actually asking. A patent grant here wouldn't change how the technology is used day-to-day, but it would give Google a formal legal claim over a core AI building block that the entire industry relies on.
This is less a "new invention" filing and more a formal legal claim around one of the most widely known and cited techniques in AI history — Word2Vec was published openly in 2013. The first independent claim being canceled is a significant red flag for patentability, and given how extensively this work has been publicly documented and built upon, it faces serious prior-art headwinds. Worth watching from a legal strategy angle, but not a sign of anything new technically.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.