Google's New Patent Lets Every Stage of Its AI See the Full Picture at Once
Most AI models read information in one direction — layer by layer, like a factory assembly line. Google's new patent describes a system where every stage of that process can see what every other stage is doing, all at once.
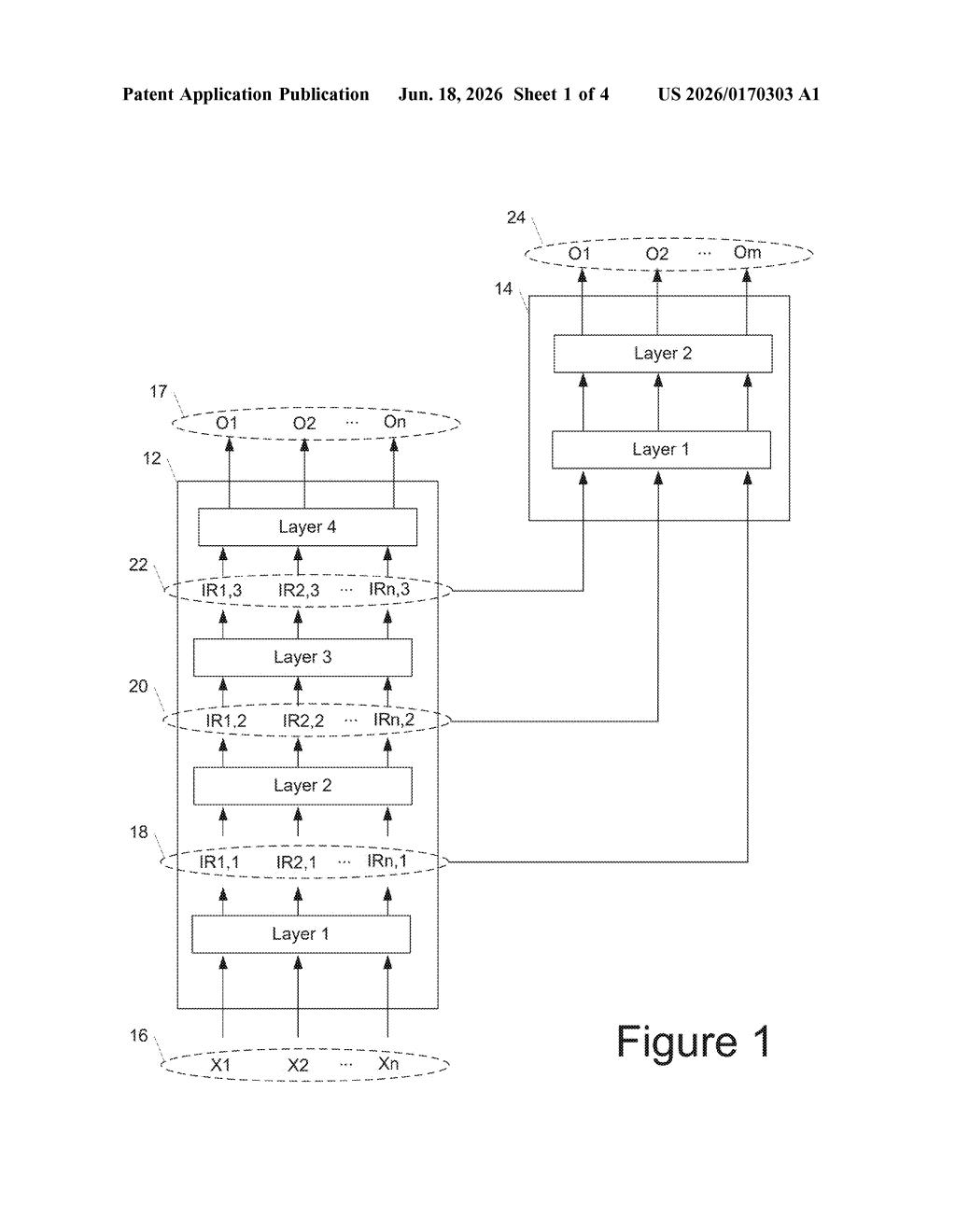
What Google's OMNINET attention model actually does
Imagine you're reading a novel, but you can only see one chapter at a time and you have to forget each chapter before moving on. That's roughly how today's AI language models process information — they pass data through one layer, then the next, without earlier layers talking to later ones.
Google's patent describes a different approach called OMNINET. Instead of that one-way assembly line, a second AI model sits alongside the main one and watches the outputs of every layer at once — early, middle, and late. It's like having a supervisor who can read all the chapters of that novel simultaneously and pull out insights no single chapter would reveal on its own.
The practical goal is a more complete understanding of language, images, or whatever data the AI is processing. By letting information flow across the entire network — not just forward — the system can catch relationships and patterns that a strictly linear model might miss.
How OMNINET taps every layer at once
The patent describes a two-model setup. The first is a standard multi-layer attention model — the kind that powers large language models like Google's own Gemini family. It processes an input (say, a sentence or a document) by passing it through a stack of self-attention layers (layers that weigh which words or tokens matter most relative to each other).
The second model is the omnidirectional model — the novel part. While the main model runs its normal forward pass, this second model collects the intermediate representations (the internal state of the data at each layer, essentially a snapshot of what the network 'thinks' at that point) from two or more of those layers simultaneously.
It then processes all of those snapshots together to produce its own output. The key insight is that later layers in a neural network typically have high-level, abstract understanding, while earlier layers hold low-level, fine-grained detail. Normally those perspectives never meet directly.
- Layer 1 output: fine-grained token-level details
- Middle layer outputs: partial, contextual representations
- Final layer output: high-level semantic understanding
OMNINET feeds all of these into the omnidirectional model at once, so the final answer can draw on every level of abstraction simultaneously.
What this means for the next wave of Google AI
For Google, this matters most in tasks where context is everything — long documents, complex questions, multi-step reasoning. A model that can cross-reference its own early and late processing stages has a structural advantage over one that can only use its final layer's output. That's relevant for search, for Gemini, and for any AI product where getting nuance right matters more than raw speed.
For you as a user, the change would be invisible but consequential: answers that feel less like the AI picked the most statistically likely response and more like it actually understood the full picture. Whether Google ships this architecture into a consumer product or keeps it as research infrastructure is an open question, but the filing signals real investment in rethinking the transformer's fundamental design.
This is serious AI research dressed up as a patent filing. The core idea — letting a companion model consume all intermediate layer states simultaneously — is a clean architectural answer to a real limitation of standard transformers. It won't land on your phone as a feature name, but if Google's researchers can show it consistently improves benchmark scores, it's the kind of building block that quietly ends up in every model they ship.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.