Salesforce Patents a Way to Train AI on Fictional People and Their Fake Friends
Salesforce has patented a way to teach AI about human relationships and personal traits — by inventing an entirely fictional social network first, then training on the fake conversations those fictional people have.
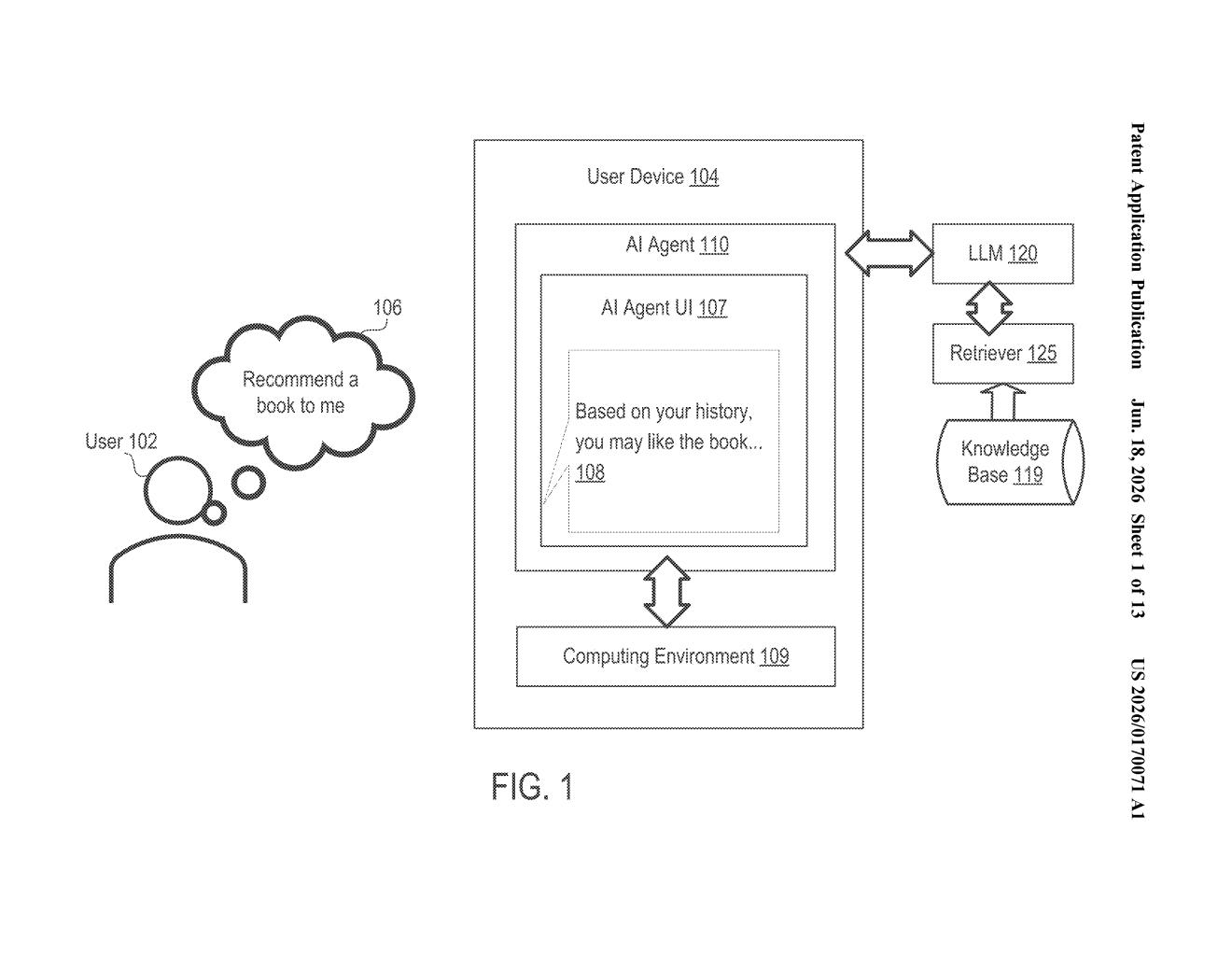
How Salesforce's synthetic personas teach an AI to know you
Imagine teaching a new customer service rep how to personalize their responses — but instead of shadowing real customers (with all the privacy headaches that involves), you hand them a stack of made-up case files. Each file has a fictional person, their traits, their friends, and some sample conversations. The rep learns the patterns. Then they're ready for real customers.
That's essentially what Salesforce is building here. An AI is used to generate a cast of fictional characters — complete with relationships, personality traits, and simulated chat logs between them. Another AI model then trains on those fake conversations, learning to match questions like "who prefers email contact?" to the right kind of profile.
When a real user asks a question, the system pulls from its training to deliver a personalized answer — without ever having trained on anyone's actual private data. It's a way to get the benefit of personal context without the privacy risk that comes with using real people's information.
How the social graph, profiles, and fake conversations connect
The patent describes a training pipeline built around retrieval-augmented generation (RAG) — a technique where an AI doesn't just rely on what it memorized during training, but actively looks up relevant documents before answering a question (think of it as open-book rather than closed-book).
The twist here is where those documents come from. Rather than using real user data, Salesforce's system has a large language model construct a synthetic social graph — a web of fictional personas (represented as nodes) and their relationships (represented as edges, like connections on a social network). Each persona gets a randomly assigned profile: age, communication preferences, job, interests, and so on.
The same LLM then writes synthetic documents — fake chat conversations between these fictional characters — that naturally reflect their assigned traits. A persona flagged as a night-owl might chat at odd hours; one marked as detail-oriented might write longer messages. These documents are labeled with the relevant characteristics and assembled into a training dataset.
A retrieval model trains on that labeled dataset, learning to surface the right documents when asked questions about specific traits. Finally, an AI agent uses the trained retrieval model to answer real user queries — pulling from the synthetic document pool to construct personalized responses:
- Generate fictional personas and their social connections
- Assign random but internally consistent traits to each persona
- Write simulated conversations that reflect those traits
- Label and package the conversations into a training dataset
- Train a retrieval model to match queries to relevant documents
- Deploy an AI agent that uses the retrieval model to answer real questions
What this means for AI-powered CRM and customer service
The biggest obstacle to personalizing AI in enterprise software — think Salesforce's CRM tools — is privacy. Training a model on real customer conversations, emails, or support tickets is legally and ethically complicated. Synthetic data sidesteps that entirely: if the training material is entirely made up, there's no real person whose data can be exposed or misused.
For Salesforce, this has obvious applications in its sales, service, and marketing cloud products, where understanding individual customer preferences is the whole point. If an AI agent can learn how to reason about personal context from fictional data, it may be able to apply that reasoning to real users at query time — without ever having ingested their private information during training. That's a meaningful distinction, and one that could matter a lot to enterprise buyers wary of AI data practices.
This is a genuinely interesting approach to a real problem: how do you train a personalization system without training on personal data? The synthetic social graph framing is clever, and it's the kind of foundational infrastructure work that could quietly show up inside Salesforce's AI suite — Agentforce, Einstein, take your pick. It's not a consumer-facing feature patent, but for enterprise AI buyers, it's exactly the kind of privacy-aware architecture that gets procurement teams to say yes.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.