Google Patent Covers Training AI Models While Keeping Private Data Truly Private
Training an AI on sensitive data, like medical records or financial transactions, usually means the raw answers used to teach it are exposed somewhere. Google's new patent describes a way to scramble those answers before training even begins, so the model learns without anyone seeing the real data.
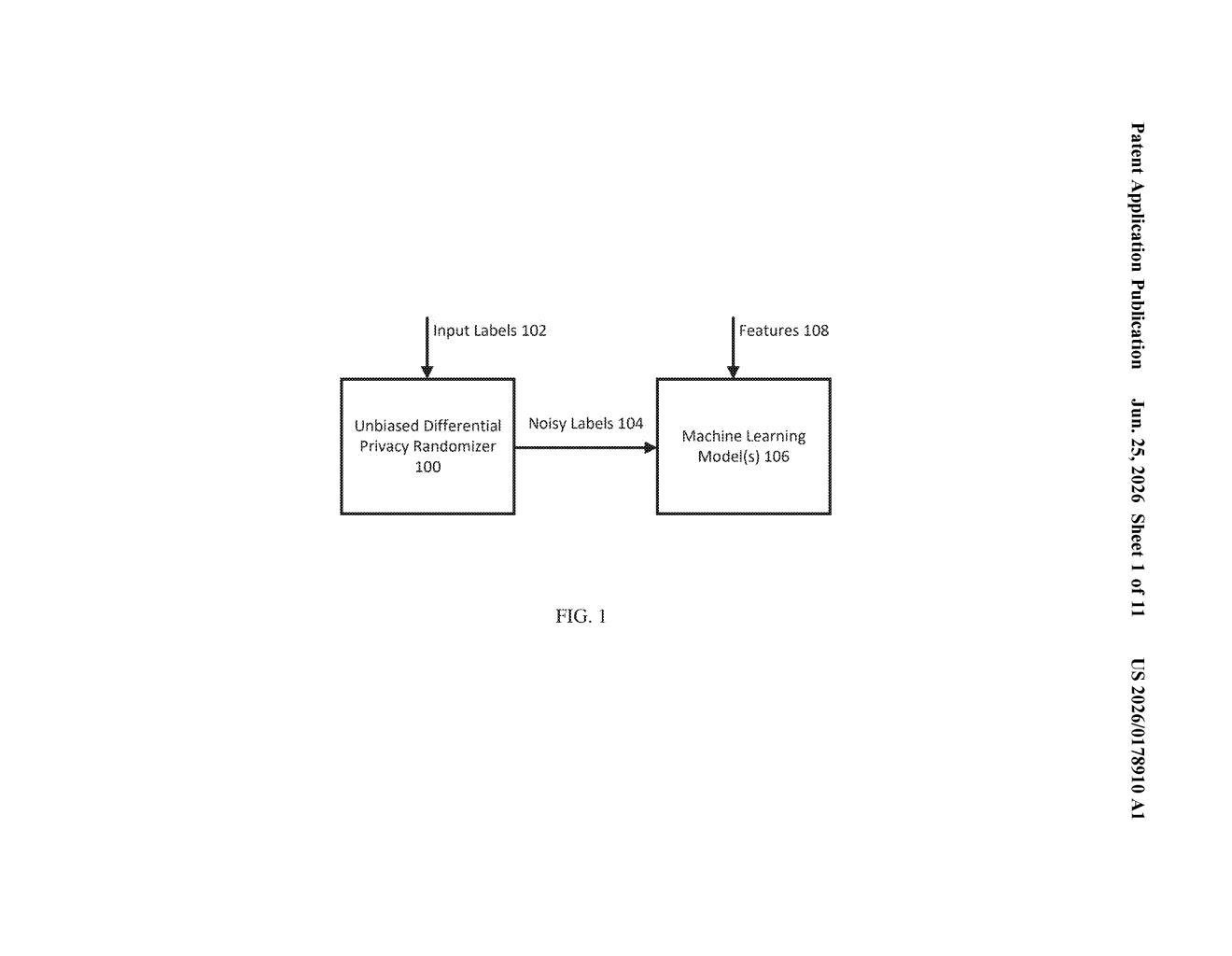
How Google hides sensitive labels while still training AI
Imagine a hospital wants to train an AI to predict patient outcomes, but sharing the actual diagnoses with engineers would violate privacy laws. The core problem: AI needs real answers to learn from, but those answers are exactly what you can't share.
Google's patent describes a system that deliberately scrambles the answers, called labels, before they're used to train the AI. The scrambling isn't random noise thrown in carelessly. It's calculated to stay as close to the true answers as possible, so the AI still learns useful patterns even though nobody ever sees the original data.
The key insight is managing the trade-off between how much you scramble (for privacy) and how much accuracy you lose (for usefulness). Google's method uses a statistical estimate of what the answers probably look like to tune that trade-off automatically, keeping the model honest without giving away the secrets.
How the randomizer balances noise, bias, and accuracy
The patent describes a training pipeline built around a concept called label differential privacy (a mathematical guarantee that you can't reverse-engineer any individual's real answer from the model's output).
Here's how it works step by step:
- The system first builds a prior distribution (a private statistical guess about what range and shape the labels tend to take, without looking at any one person's label directly).
- Using that prior, it generates a differential privacy randomizer, a translation table that maps each real label to a scrambled version, calibrated so the scrambling satisfies formal privacy guarantees.
- The randomizer is designed to be unbiased, meaning the scrambled labels don't systematically pull the model in the wrong direction, which is a known failure mode of simpler noise-adding approaches.
- The model is then trained on these randomized labels instead of the originals.
The unbiased constraint is the technically interesting part. Earlier approaches added noise that made predictions consistently too high or too low, which compounds over millions of training steps. Google's method uses an objective function (a mathematical goal the randomizer optimizes against) that corrects for this drift while still meeting the privacy budget.
What this means for AI trained on health or financial data
Any company that wants to train AI on regulated data, think patient records, credit scores, or salary information, faces a real compliance wall. Differential privacy is one of the few frameworks that offers a mathematically provable privacy guarantee, not just a policy promise. A better-calibrated randomizer means you can train a more accurate model without loosening those guarantees, which is a real engineering problem with no easy solution today.
For you as a user, this kind of research is what would let a health app train a personalized AI on your data without a human at Google (or anywhere else) ever seeing your actual health numbers. It's infrastructure work, but it's the kind that makes genuinely sensitive AI applications possible.
This is serious academic-grade privacy research dressed up as a patent, and it matters more than most AI filings. The unbiased randomizer framing addresses a real, documented limitation of current differential privacy methods for regression tasks. Whether Google ships this as a product feature or keeps it as a research building block, the underlying idea is worth watching.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.