Google Patents an AI Assistant That Talks and Acts at the Same Time
Most AI assistants decide what to say first, then figure out what to do. Google's new patent describes a system that does both at once, using a single neural network that reads the full conversation history and acts on it in real time.
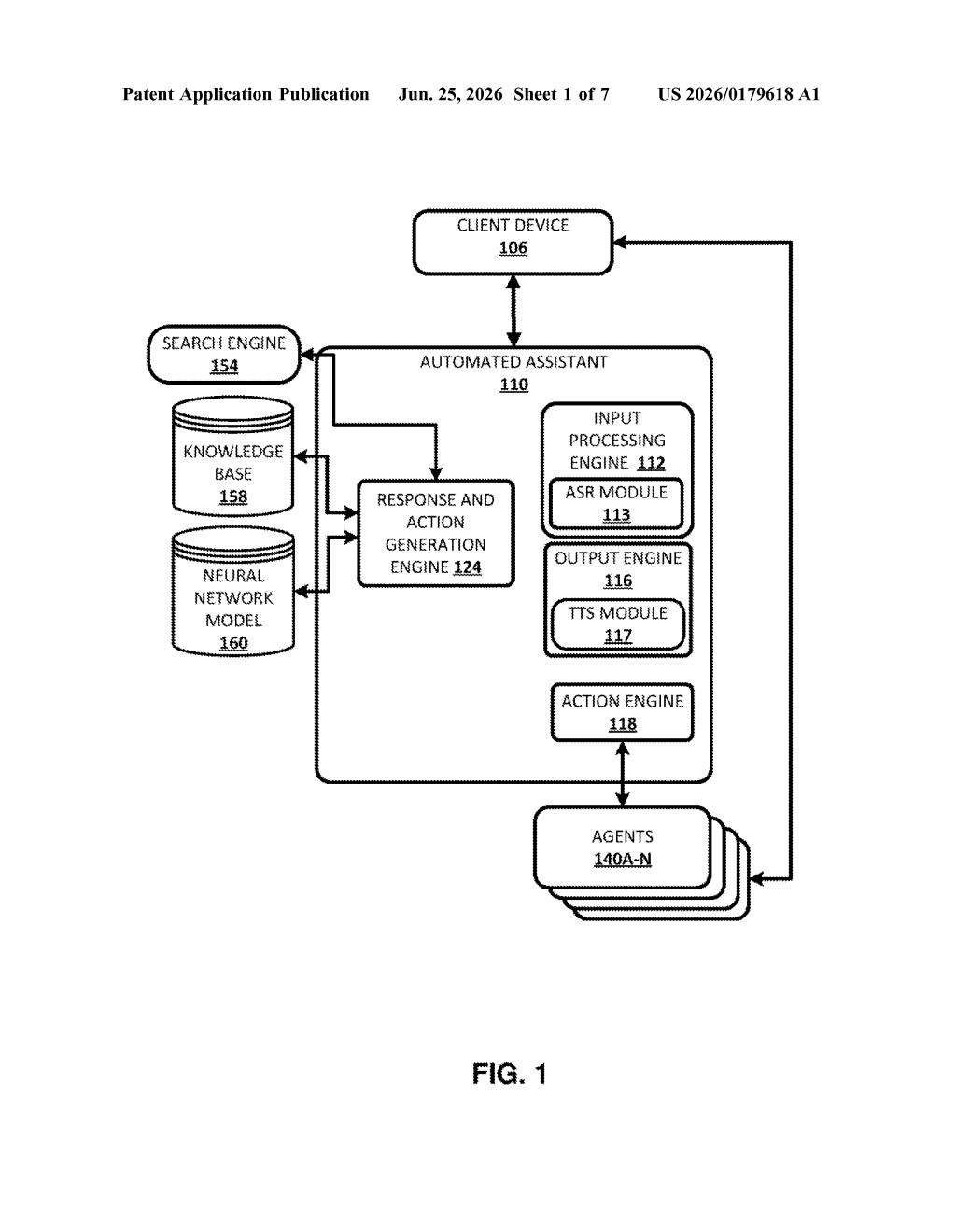
What Google's single-model assistant actually does
Imagine asking your phone's assistant to book a restaurant, play a song, and then confirm the reservation, all in one flowing conversation. Today, most AI assistants handle those steps in separate passes: say something, trigger a tool, say something else. Each step is a bit disconnected.
Google's patent describes an assistant that handles the talking and the doing inside one unified system. Instead of a separate "speech brain" and "action brain," a single model reads the entire conversation so far and decides both what to say next and what action to take, at the same time.
Critically, every action the assistant takes gets written back into the conversation history. So when you follow up with a new question, the assistant already "remembers" what it just did and can build on it. That keeps longer, multi-step conversations coherent rather than having the assistant forget its own previous moves.
How the transformer decoder drives talk and action together
The patent describes a transformer decoder (the same core architecture behind large language models like GPT) that reads a running log of the conversation, including previous messages from both the user and the assistant, plus a set of available "discrete resources" such as APIs, databases, or device controls.
At each turn in the conversation, the model outputs two things jointly:
- A natural language response (the words the assistant says aloud or displays)
- One or more actions (calls to external services, changes to device state, database lookups, etc.)
What makes this different from existing pipelines is the feedback loop. After an action is performed, a record of that action is appended to the dialog history. When the user speaks again, the model's next decision is informed not just by what the user said but by what the assistant already did. This prevents the assistant from repeating steps or losing context mid-task.
The model generates both responses and actions token by token (word fragment by word fragment), meaning the architecture treats an action instruction the same way it treats a word in a sentence. There is no separate planning module; everything comes out of one forward pass through the network.
What this means for Google Assistant's next chapter
For users, the practical benefit is an assistant that stays coherent across long, multi-step tasks without you having to repeat yourself or restart the conversation. If you ask it to find a flight, book it, and then ask "what time does that land?", the assistant already has the booking in its history and doesn't need to re-query anything.
For Google, this approach points toward a tighter integration between Google Assistant (or Gemini-based successors) and the services it connects to, all controlled through one model rather than a patchwork of specialized modules. Fewer moving parts typically means faster responses and fewer failure points, which is the kind of reliability improvement that makes an assistant feel genuinely useful rather than just clever in demos.
This is a meaningful architectural patent, not a flashy one. The idea of collapsing "speech" and "action" into a single model with a persistent action log is a real design choice that addresses a real frustration with today's assistants. Whether Google ships exactly this approach or uses it as a building block, it signals a clear direction: Gemini-era assistants that treat your whole conversation, including what they already did, as the context for every next move.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.