Adobe Patents Technology That Answers Data Searches Without Exposing Real User Information
Adobe is patenting a way to let databases answer statistical questions about users without those databases ever actually storing the real answers. The trick is baking mathematical noise into the data before it's saved.
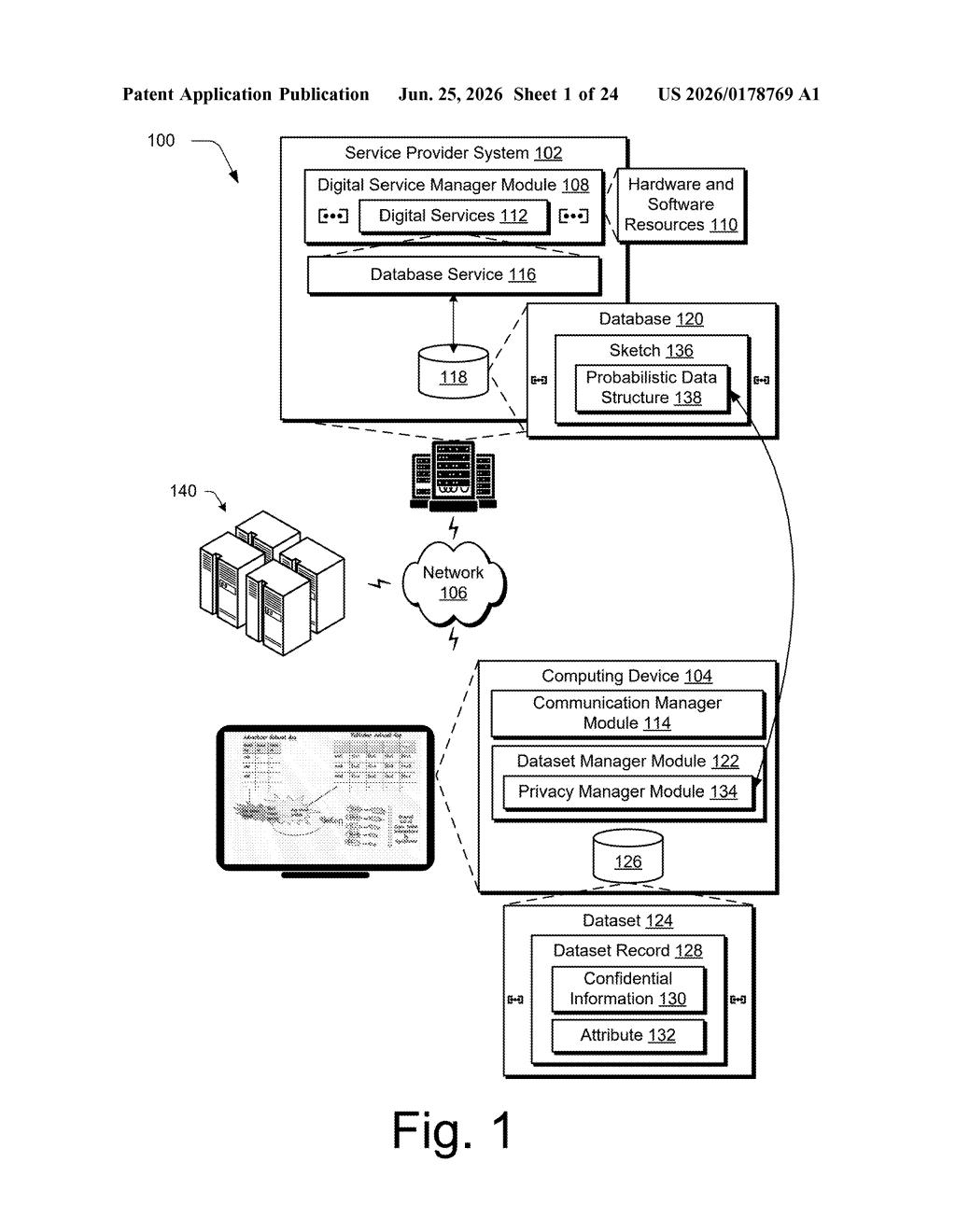
How Adobe hides your data inside noisy database sketches
Imagine your bank wanted to know how many customers spent over $500 last month. One approach: collect everyone's exact transaction history. Another: deliberately blur each person's record a little before storing it, so the overall count is accurate enough to be useful but no individual's real number is readable. Adobe's patent does the second thing.
The system takes an incoming data record (say, something about your behavior in an Adobe app) and generates what the patent calls a sketch: a compact, intentionally imprecise version of your data that has controlled noise baked in. That noisy sketch goes into the database instead of your real record.
When someone runs a query, like "how many users did X?", the database answers using those blurry sketches. The answer is close enough for analytics, but no one can work backwards to find out what you specifically did. It's a well-established privacy concept called differential privacy, and this patent is Adobe's implementation of it inside probabilistic data storage.
How the sketch encodes noise before data ever hits the database
The patent describes a three-step pipeline centered on a concept called differential privacy (a mathematical guarantee that any single person's data can't meaningfully change the output of a query, making it very hard to identify individuals from results).
- Receive a dataset record: A raw data point arrives at a processing device, for example a user interaction event or a behavioral signal.
- Generate a sketch: The system creates a probabilistic data structure (a compressed representation that trades some accuracy for efficiency and, in this case, privacy) by injecting calibrated random noise into the record. The noise is designed so that individual records are obscured but aggregate statistics remain statistically valid.
- Store and query: Only the noisy sketch enters the database. When a query runs, it receives a probabilistic result, meaning an answer that is approximately correct rather than exact, which is the intended behavior.
The approach ties together two separate ideas from computer science: differential privacy, which defines how much noise to add to protect individuals, and probabilistic data structures like Count-Min Sketches or HyperLogLog (memory-efficient summaries used in large-scale analytics). Combining them means privacy is enforced at write time, not just at query time.
What this means for ad-tech and analytics privacy
Adobe sits at the center of digital advertising and creative analytics, running platforms like Adobe Analytics, Audience Manager, and Experience Cloud that process enormous amounts of behavioral data. Any technique that lets Adobe tell clients "yes, your campaign reached X million users" without retaining individually identifiable records has obvious value as privacy regulations tighten globally under frameworks like GDPR and CCPA.
For you as a user, the promise is that even if a database is breached or subpoenaed, the stored records can't be reverse-engineered into your real activity. For Adobe's enterprise customers, it offers a credible way to run analytics without the legal exposure of holding sensitive raw data. The catch, as with all differential privacy schemes, is calibration: too much noise and the analytics become useless; too little and the privacy guarantee weakens.
Differential privacy is a real and important technique, and this patent isn't just theoretical chest-puffing. Adobe processing behavioral data at scale has genuine incentive to build this infrastructure, and baking privacy into storage rather than bolting it on at query time is the right architectural instinct. That said, the patent's independent claim is very broad, and the core idea of combining differential privacy with probabilistic data structures is well-trodden academic ground, which means getting this granted in its current form may be harder than it looks.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.