Qualcomm Patents an AI System That Finds Similar Files by Shrinking Them First
Searching through a large collection of files to find ones that look like yours is slow and expensive. Qualcomm's new patent describes a way to shrink every file down to a tiny AI-generated fingerprint first, then compare fingerprints instead of full files.
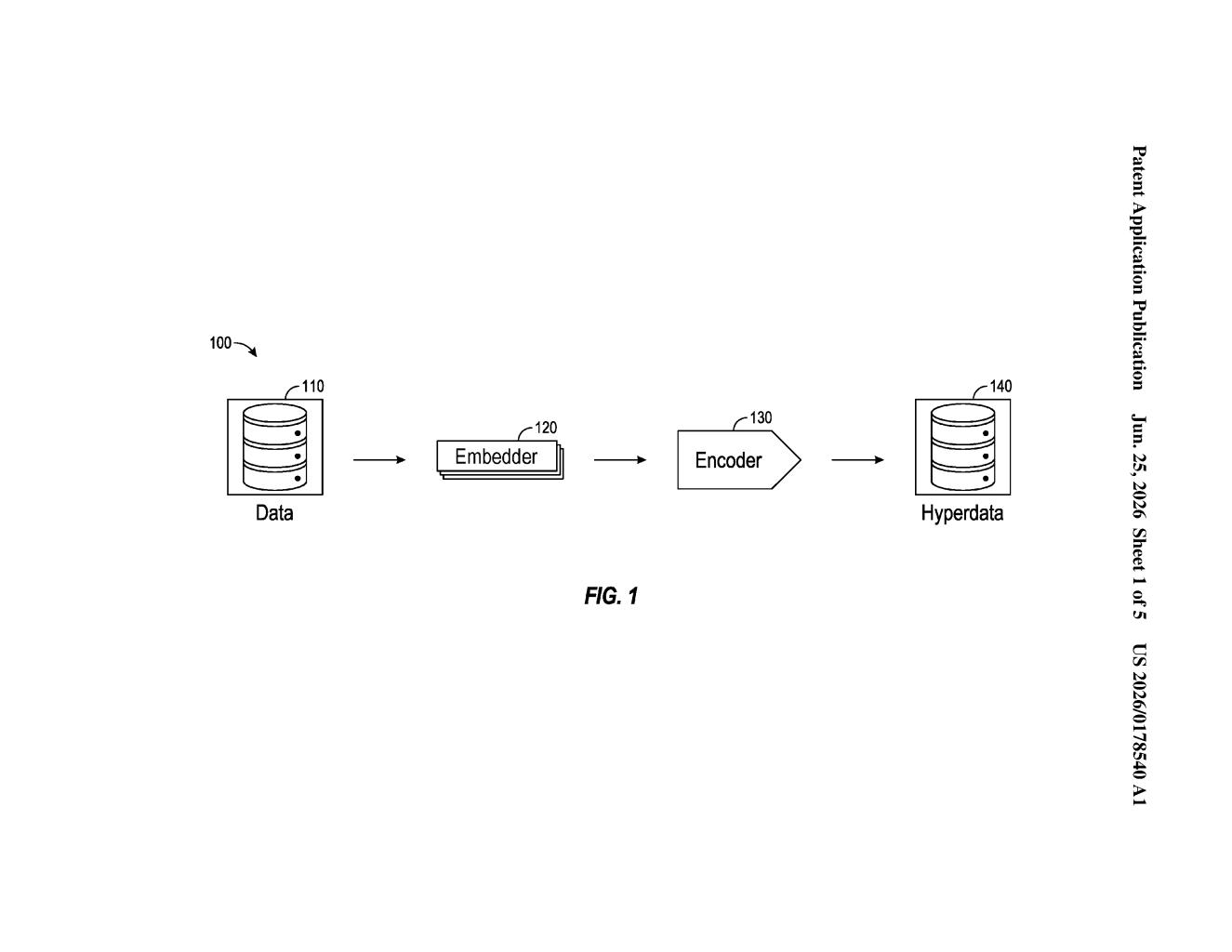
What Qualcomm's AI file-search compression actually does
Imagine you want to find all the photos in a giant album that look similar to one specific photo you have. Checking every single image pixel-by-pixel would take forever. Qualcomm's patent describes a shortcut: an AI model studies your photo and produces a tiny numerical summary of it, a kind of fingerprint. Every other file in the collection already has its own fingerprint stored and ready.
When you send in your search file, the system creates its fingerprint and then compares that small summary against all the stored summaries, not the full files. Because you're comparing tiny compressed versions instead of massive originals, the whole search runs much faster and uses far less computing power.
The system then hands back whichever files have fingerprints closest to yours. The approach works for any kind of structured file, not just images, which means it could apply to audio clips, sensor readings, documents, and more.
How the model compresses files into searchable fingerprints
The patent describes a two-stage pipeline built around machine learning models.
Stage 1: Embedding generation. A first ML model takes an input data file and converts it into an embedding representation (think of this as a compact list of numbers that captures the file's essential characteristics, the way a fingerprint captures a person's identity without storing a full photograph of them).
Stage 2: Compression. That embedding is then compressed further into a short binary or numeric code. Crucially, the patent also describes pre-computing and storing these compressed codes for every file already sitting in the data repository, so the heavy AI work only happens once per stored file.
Search and retrieval. At query time, the system generates a compressed code for the incoming file and runs a fast comparison against all the pre-stored compressed codes. Files whose codes are closest to the query code are returned as results.
The net effect is that the expensive part (running the ML model) is separated from the time-sensitive part (the actual search), keeping search fast even over very large collections.
What this means for on-device AI search on Snapdragon chips
Qualcomm makes the Snapdragon chips that power most Android phones, and the company has been aggressively building on-device AI features into those chips. A fast, low-power similarity search engine would be a natural fit for things like on-device photo search, audio recognition, or document retrieval, where sending data to a cloud server isn't always desirable or possible.
For everyday users, the practical payoff would be faster search results that don't drain your battery or require an internet connection. Whether this ends up in a phone, a laptop chip, or an edge computing device isn't specified in the patent, but the emphasis on compression and efficiency signals Qualcomm is thinking about hardware with limited memory and processing headroom.
This is solid, practical engineering rather than a splashy AI concept. The core idea of pre-compressing file embeddings to separate heavy model inference from fast search time is well-established in the research literature, so the novelty here is likely in the specific compression and retrieval architecture Qualcomm is claiming. It's worth watching because it fits squarely into Qualcomm's broader push to run AI workloads locally on Snapdragon silicon.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.