Xilinx Patents a Method to Make AI Models Smaller Without Losing Accuracy
Trimming an AI model once tends to leave it brittle and inaccurate. Xilinx thinks the fix is to trim it, fatten it back up, and then trim it again.
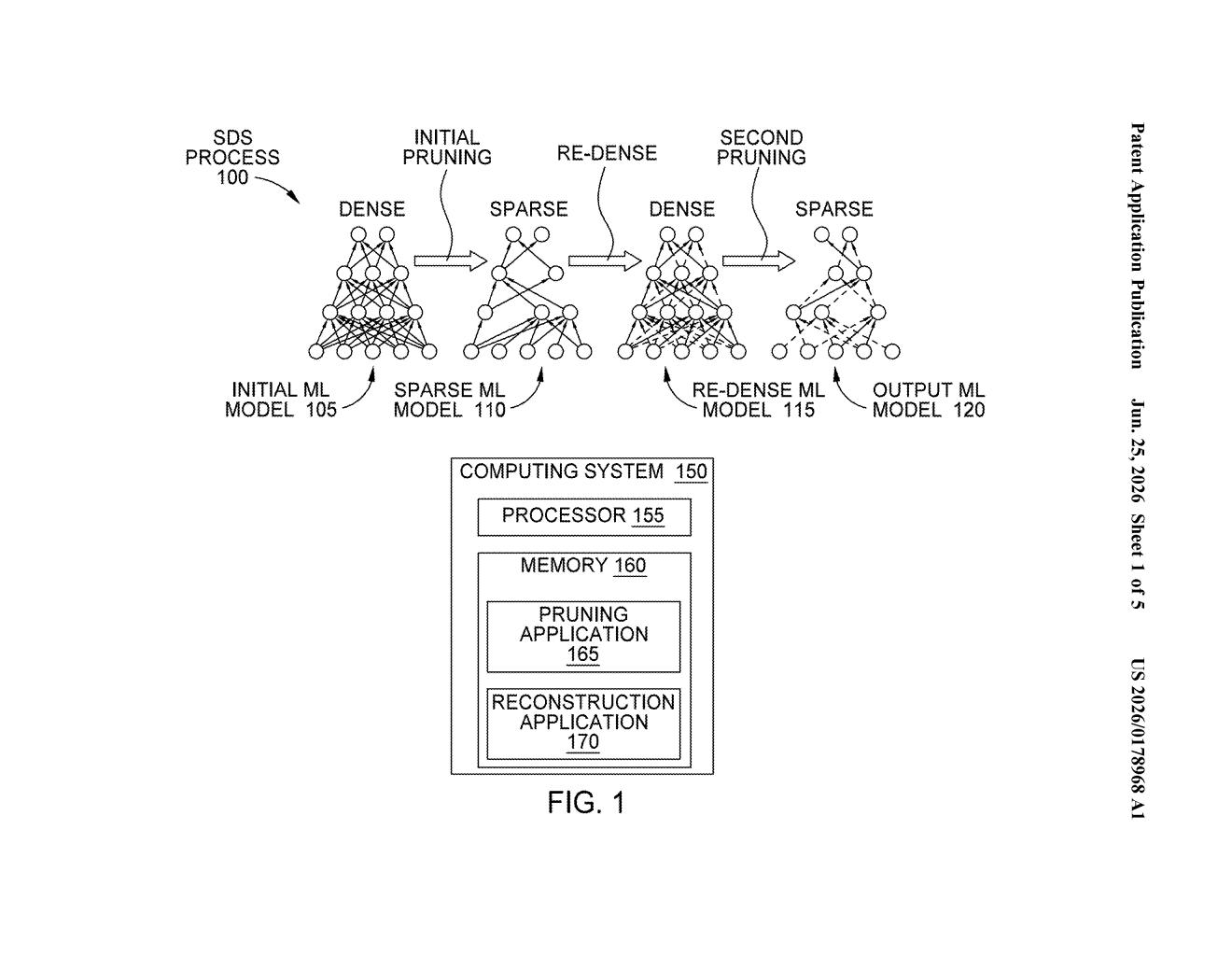
How Xilinx's triple-step AI compression actually works
Imagine you're sculpting a block of clay. If you cut away too much too fast, you end up with cracks and uneven patches. But if you add a little clay back before making your final cuts, you get a much cleaner result. That's essentially what Xilinx is patenting here.
AI language models (the kind that power chatbots and text tools) are enormous, and running them on real hardware requires cutting them down to a manageable size. The standard approach is to just remove the least-important parts in one go, but that tends to hurt accuracy. Xilinx's method does it in three steps: cut, rebuild, then cut again.
That middle rebuild step is the key idea. It lets the model reorganize itself into a shape that's easier to compress cleanly the second time around. The result, according to the patent, is a leaner model that's more accurate than one that was simply trimmed once.
Inside the sparse-dense-sparse pruning cycle
The patent describes a process Xilinx calls Sparse-Dense-Sparse (SDS). It's a three-phase pipeline for compressing machine learning models, particularly large language models.
- First pruning: The system removes weights (the numerical values that define how a neural network behaves) that appear least important, producing a sparse model, one with lots of zeroes where values used to be.
- Reconstruction: The sparse model is then rebuilt into a re-dense model. This step applies data and weight regularization (a technique that nudges the model's internal values toward a smoother, more uniform distribution), making the model more amenable to a second round of cuts.
- Second pruning: The re-dense model is pruned again, producing a final sparse model with lower perplexity (a measure of how confused the model is, lower is better) than a model pruned in one shot.
The core claim is that the reconstruction step makes the model pruning-friendly: by reshuffling the weight distribution before the second cut, the final compressed model retains more of its original accuracy.
What this means for running AI on Xilinx chips
Deploying large AI models on dedicated hardware accelerators (like the FPGAs and AI chips Xilinx makes) requires aggressive compression. A model that's been poorly compressed performs worse; one that's been well compressed can run efficiently without much accuracy loss. This patent is Xilinx staking out a specific, structured method for doing that compression better.
For you as an end user, this kind of work is invisible but consequential. It's the difference between an AI feature that runs locally on a device and one that has to phone home to a server. If Xilinx's method ships in tooling for chip developers, it could make capable AI models fit on smaller, cheaper, lower-power hardware.
This is solid, unglamorous engineering work on a real problem. Model compression is genuinely hard, and the prune-rebuild-prune insight is intuitive enough to be believable as an improvement. It's not a headline-grabbing AI patent, but it's the kind of foundational tooling that matters a lot to anyone deploying models on constrained hardware.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.