AMD Patents a System That Auto-Compresses Data When AI Chips Share Too Much at Once
When dozens of AI chips need to share data simultaneously, mismatched data sizes can stall the whole operation. Xilinx's new patent describes a system that automatically squeezes data down to fit, then restores it on the other side.
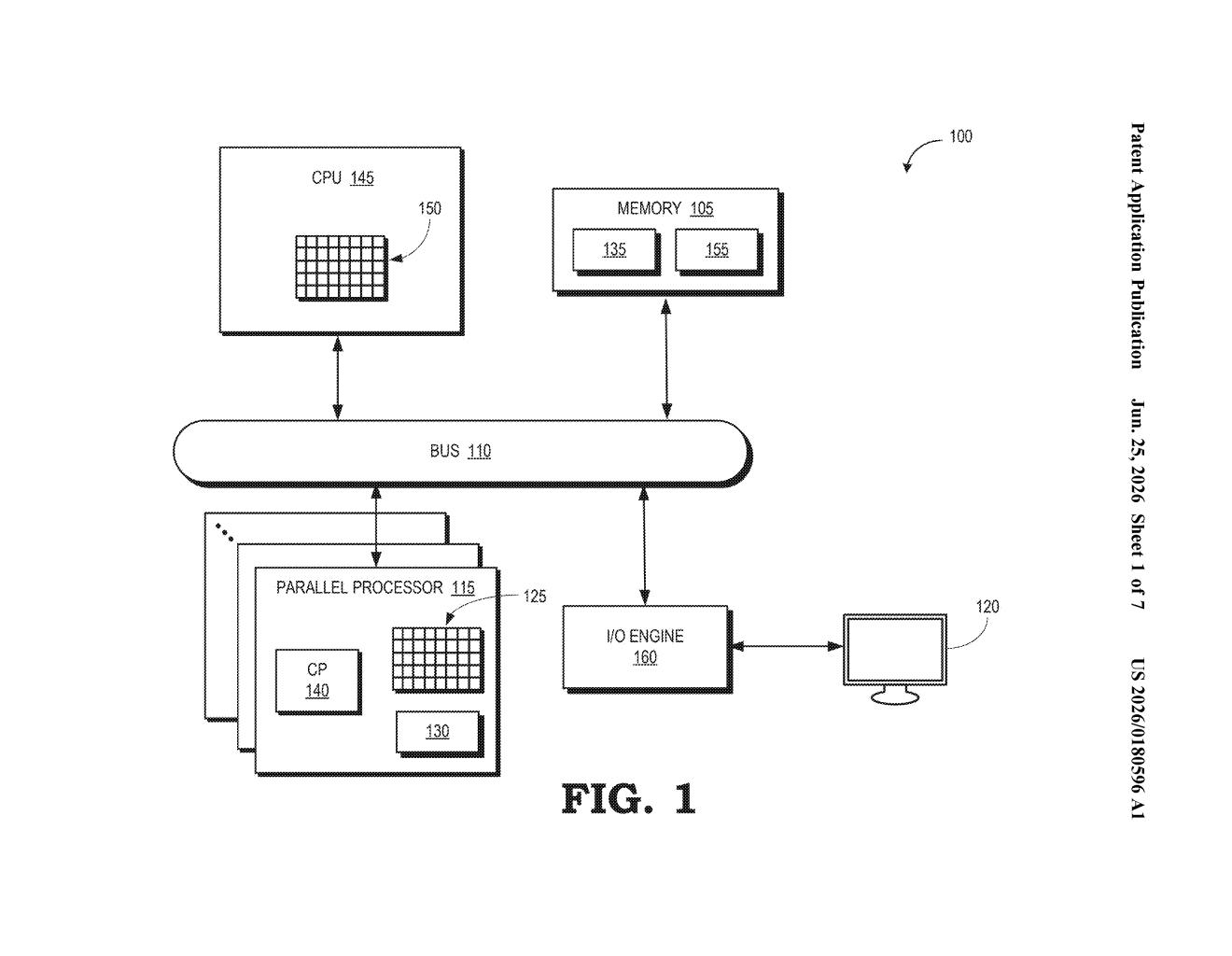
What Xilinx's auto-shrink buffer trick actually does
Imagine you're moving furniture and you have a truck with a fixed cargo space. Some loads fit perfectly, but others are too big. Instead of renting a bigger truck every time, you compress the load, drive it over, and reassemble on the other end. That's essentially what this patent describes for AI hardware.
When multiple chips in a system need to exchange data at the same time (a process called a collective operation, common in AI training), each chip has a fixed-size memory slot to work with. If the data being sent is larger than that slot, something has to give. This system automatically compresses or reduces the precision of the data to fit, runs the shared operation, then converts everything back to the original format.
The result is that chips don't have to wait around or crash out when data sizes vary, which is a common headache in real AI workloads where input sizes are rarely perfectly predictable.
How the quantization step fits variable data into fixed buffers
The patent describes a method for handling what engineers call collective operations (coordinated data exchanges across many processors simultaneously, like broadcasting weights during AI model training) when the data being exchanged is variable in length rather than fixed.
Each processor in the group is assigned a fixed-size buffer (a reserved memory slot of a set capacity). When incoming data is larger than that buffer, the system automatically applies one of two strategies:
- Quantization: reducing numerical precision (for example, representing a number with 8 bits instead of 32, trading some accuracy for smaller size)
- Compression: encoding the data more efficiently to reduce its footprint without necessarily changing its precision
After the collective operation completes across all processors, the system reverses the process, dequantizing or decompressing the results back into their original variable-length format.
The key design choice is that this compression is selective and dynamic: it only kicks in when data actually exceeds the buffer size, so there's no unnecessary quality loss when the data fits as-is. This makes the system adaptive to real workload conditions rather than always compressing or always failing on oversized inputs.
What this means for large-scale AI chip coordination
In AI training, especially for large models spread across many chips, collective operations are among the most time-sensitive steps. If data sizes are unpredictable (which they often are in real-world workloads), systems either over-provision memory (expensive) or stall when data overflows (slow). This patent describes a way to handle that variability automatically, which could reduce both memory waste and processing delays in multi-chip AI accelerator setups.
Xilinx, now part of AMD, makes FPGAs (programmable chips widely used in data centers and AI inference hardware). A mechanism like this would be a natural fit for FPGA-based AI accelerators, where efficient data movement between processing elements is a constant engineering challenge. If this approach makes it into production silicon or firmware, it could improve throughput in AI workloads without requiring software-side workarounds.
This is a narrow but practical piece of systems engineering aimed squarely at a real bottleneck in multi-chip AI workloads. It's not flashy, but the problem it solves (variable-length data overflowing fixed communication buffers) is a genuine friction point in production AI infrastructure. Whether it ends up in AMD/Xilinx products or stays on the shelf, it reflects the kind of low-level optimization work that actually determines whether AI hardware runs efficiently at scale.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.