Microsoft Patents Automated Data Lineage Extraction from Database Query Logs
Every time a database query runs, it leaves a trail — and Microsoft wants to automatically turn that trail into a full map of where your data came from and where it went. That's the core idea behind this data provenance patent.
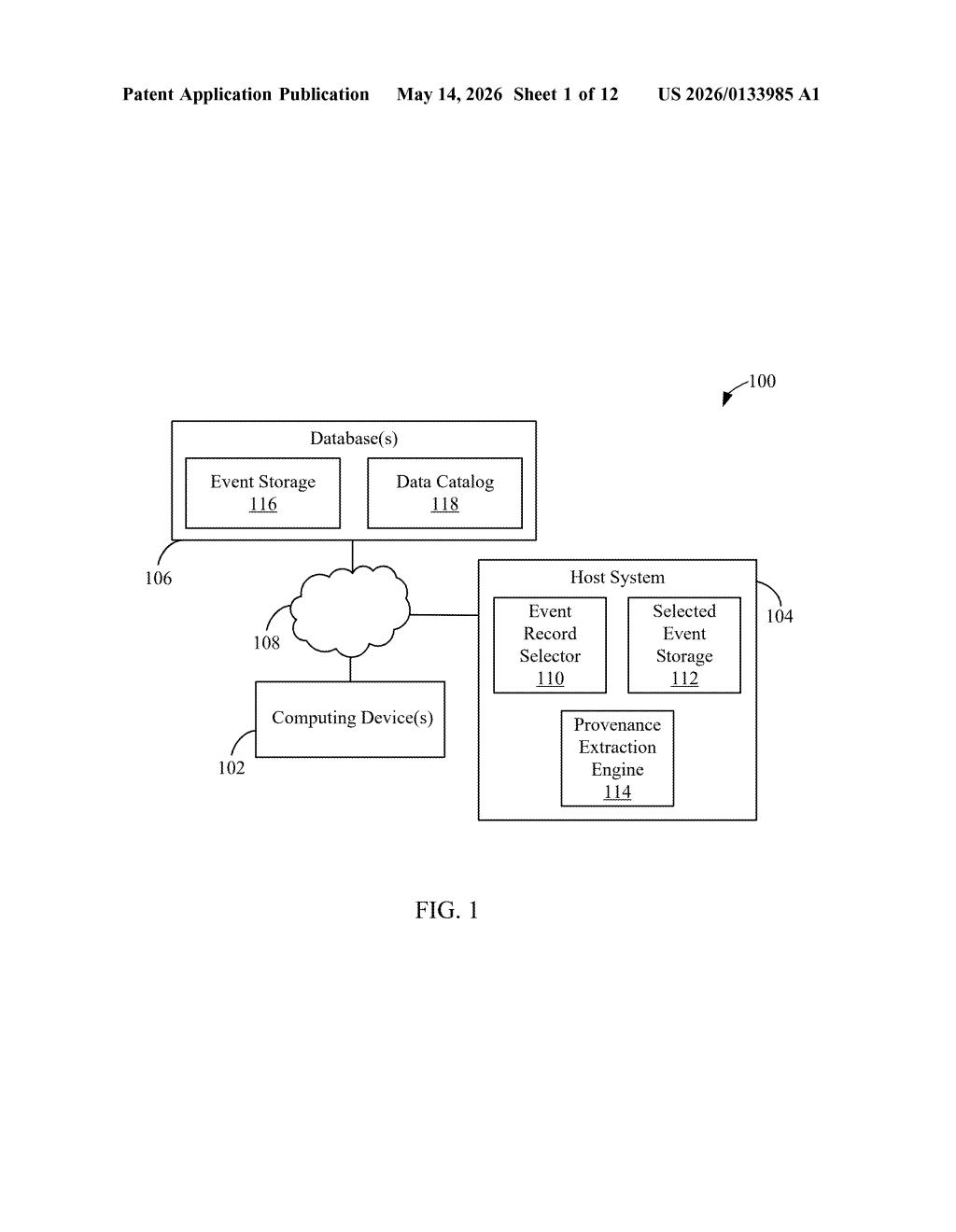
What Microsoft's query-log lineage tracking actually does
Imagine your company's data warehouse runs thousands of queries every day — pulling from tables, joining datasets, writing results elsewhere. When something goes wrong, or a compliance auditor asks "where did this number come from?", someone has to manually trace it back. That's painful and slow.
Microsoft's patent describes a system that watches those query execution logs automatically and builds a data lineage map — a record of which datasets fed into which other datasets, and in what order. Instead of a human detective work, you get an automated picture of your data's family tree.
The system groups related log events into activities, figures out the dependencies between them, and stitches together both the runtime details (what processes ran, when, how) and the lineage details (what data moved where). The result feeds into tools like data catalogs that help organizations understand and govern their data.
How the provenance engine parses logs into lineage graphs
The patent describes a Provenance Extraction Engine that sits on top of database query execution logs and pulls out two distinct types of information.
First, it handles runtime information — the "who did what and when" layer. The engine groups related log events into units called activities, builds a data structure encoding the execution dependencies (think: a dependency graph of query steps), and identifies the processes and relationships involved.
Second, it extracts lineage information — the "where did this data come from" layer. It parses the actual SQL or query text in the logs to identify dataset entities (tables, views, files) and the relationships between them: which dataset was read to produce which other dataset.
These two layers are then mapped together into a unified provenance data model — essentially a structured record that links runtime execution context to data flow. That model is stored and made available to downstream provenance applications like data catalogs or compliance dashboards.
A key detail: the system accepts an input configuration, meaning it can be tuned to target specific logs, query types, or extraction rules — making it flexible enough to work across different database environments.
What this means for enterprise data governance tools
Data lineage is one of the unglamorous but genuinely important problems in enterprise data engineering. Regulations like GDPR and CCPA require organizations to know where personal data lives and how it moves. Data quality teams need lineage to debug bad numbers. And AI/ML pipelines increasingly need provenance to satisfy model auditing requirements. Right now, most of this tracking is either manual or relies on instrumentation baked into specific tools.
Microsoft's approach — reading logs that already exist rather than requiring new instrumentation — is practical and broadly applicable. This fits squarely into Microsoft Purview, the company's data governance product, which already offers lineage features. A patent like this suggests Microsoft is investing in making that lineage extraction more automated, more scalable, and more database-agnostic.
This is unglamorous infrastructure work, but it's exactly the kind of thing that makes enterprise data governance actually usable at scale. The clever angle here is passive extraction from existing logs — no new instrumentation required — which dramatically lowers the adoption barrier. If this lands in Microsoft Purview, it could meaningfully close the gap between what compliance teams need and what data engineers have time to set up.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.