Nvidia Patents an AI Pipeline That Turns Video Into Animatable 3D Characters
Creating a fully animatable 3D character from video footage typically requires armies of artists and weeks of rigging work. Nvidia's latest patent describes a way to let AI do most of that heavy lifting automatically.
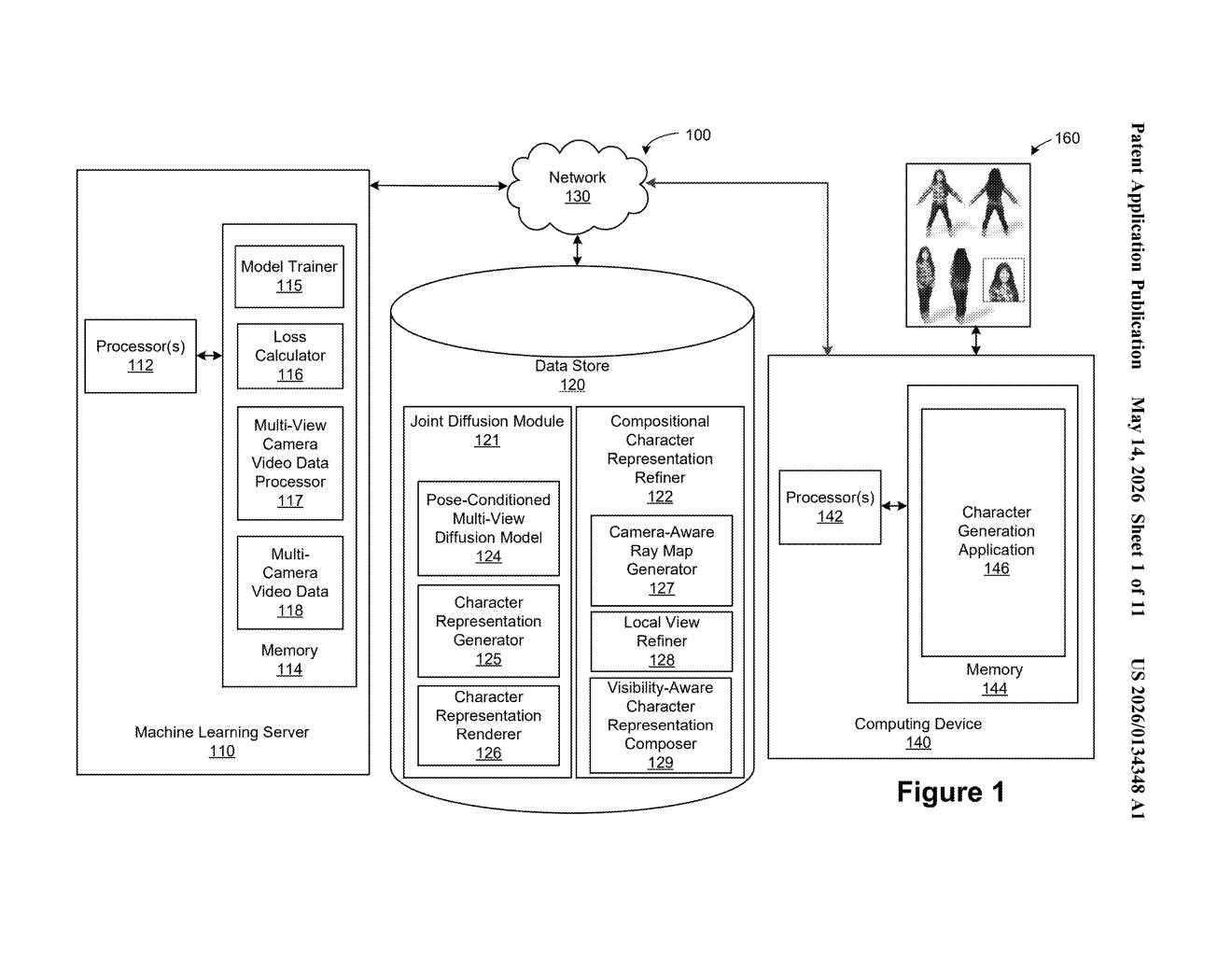
How Nvidia's system builds a 3D character from video
Imagine you want to put a real person — or a fictional one — into a video game or animated film as a fully movable 3D character. Today, that process involves motion capture suits, manual 3D modeling, and a lot of expensive labor. Nvidia is working on a way to skip most of that.
The system described in this patent watches video of a character filmed from multiple camera angles at once. From that footage, it learns two complementary things: a broad, global understanding of what the character looks like overall, and a detailed picture of how the character looks from any specific angle. Together, those two pieces of knowledge let the system reconstruct the character in 3D and make them ready to animate.
The key tool here is a diffusion model — the same family of AI that powers image generators like DALL-E and Stable Diffusion — paired with a machine learning model that builds a compact description of the character. Train it on enough multi-camera footage, and you get a system that can generate animatable 3D versions of new characters it has never seen before.
How the diffusion model and character encoder work together
The patent describes a two-part AI system trained on multi-camera video data — footage of characters captured simultaneously from many angles, the kind of setup common in professional motion capture studios.
During training, the system is shown input views (images of a character from known camera positions) and target views (images of the same character from different angles it needs to predict). A diffusion model (an AI that iteratively refines noisy images into clean ones, similar to how Stable Diffusion works) learns to predict what the character looks like from those unseen angles. Simultaneously, a separate machine learning model — called here a character representation model — learns to produce a global representation, essentially a compact mathematical description capturing the character's overall appearance and structure.
The system is described as compositional, meaning it breaks character appearance into separable parts — likely body, face, clothing — that can be reasoned about independently and then composed back together. A local view refiner and a character representation composer are called out specifically in the patent diagrams, suggesting the system handles fine detail and global structure as distinct stages.
Once trained, the system can generate an animatable representation of a new character — one it wasn't trained on — by applying the learned diffusion model and the global representation model to that new subject's images.
What this means for game studios and virtual production
For game studios, VFX houses, and virtual production teams, the bottleneck in character creation has always been the gap between capturing a real person and getting a rig that animators can actually use. A system that can bootstrap that process from video footage alone — without custom per-character work — could meaningfully compress timelines and costs.
Nvidia is also well-positioned to deploy this kind of technology across its Omniverse platform, which is already aimed at real-time 3D content creation. If this technique matures, you could see it enabling faster digital-human pipelines for everything from gaming NPCs to virtual try-on in e-commerce. The diffusion-model core also means quality could scale with compute — a natural fit for a company that sells the GPUs doing the inference.
This is a genuinely interesting research-to-product pipeline patent from Nvidia, not a vague capability claim. The compositional framing — separating global character understanding from view-specific detail — is a smart architectural choice that addresses a real failure mode in naive multi-view reconstruction systems. Whether it ships as an Omniverse feature or stays a research paper for a while, it's worth tracking.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.