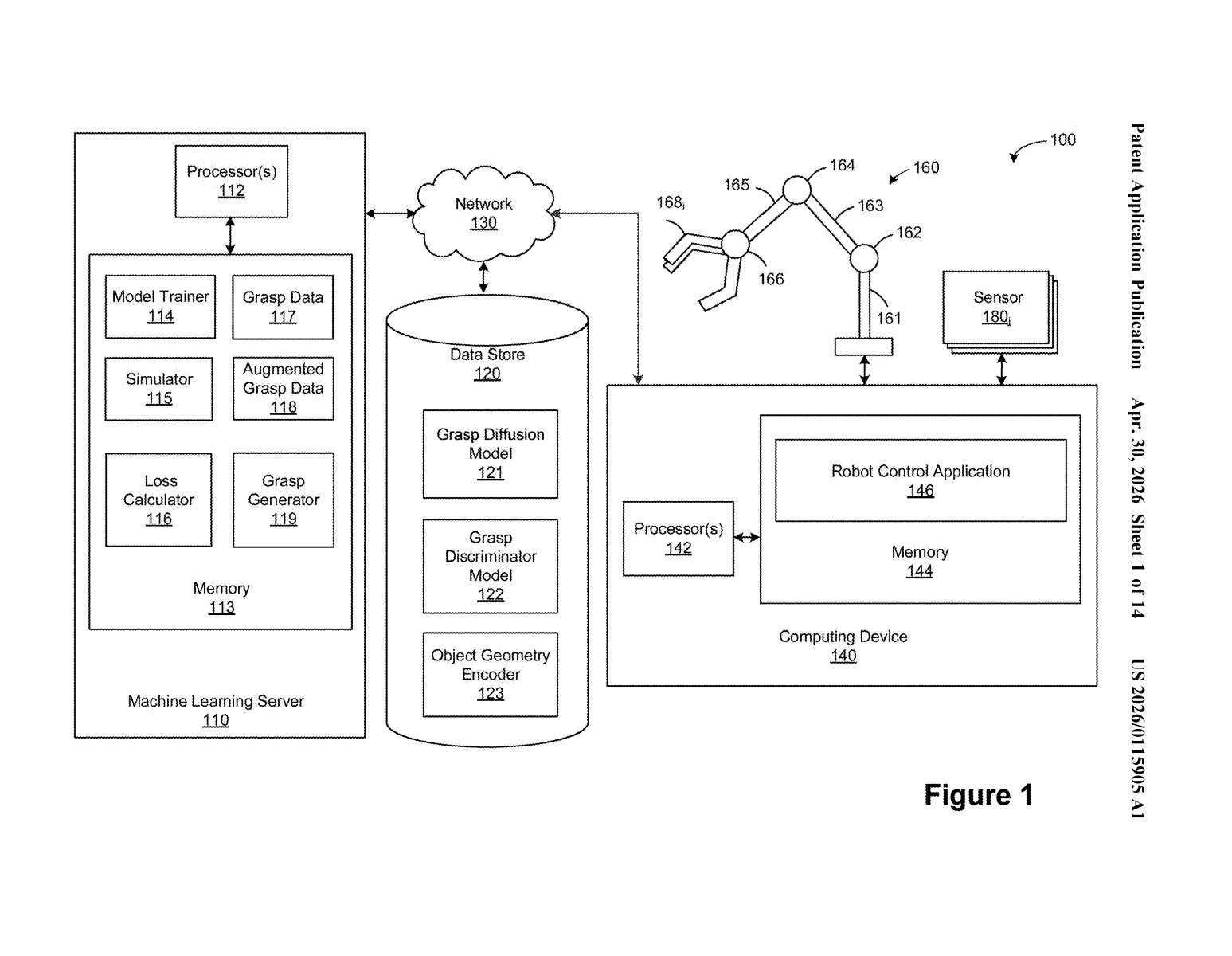
Nvidia Patents a Diffusion AI System for Teaching Robots to Grab Objects
Getting a robot to reliably pick up an object sounds simple — it's one of the hardest unsolved problems in robotics. Nvidia is now patenting a system that uses generative AI, the same family of tech behind image generators, to teach robots smarter grasping strategies.
How Nvidia's diffusion model teaches robot hands to grip
Imagine you're trying to teach someone to pick up a coffee mug they've never seen before. You'd show them a bunch of examples, let them practice, and tell them which tries worked and which didn't. Nvidia's patent applies that same loop — but with AI — to robot arms.
The system starts with a diffusion model (the same kind of AI that powers image generators like Stable Diffusion) trained on examples of good robot grasps. That model then invents new grasping positions it hasn't seen before — effectively brainstorming. A simulator then tests each invented grasp and labels it as a success or failure.
Those labeled results feed a second AI model, which learns to read sensor data from a camera or depth sensor and output a grasp plan — a step-by-step guide for the robot arm to actually pick something up. It's a self-improving loop: the more the system generates and tests, the smarter the final model gets.
Inside Nvidia's two-stage grasp training pipeline
The patent describes a two-stage training pipeline for robot grasping. Stage one trains a diffusion model (a generative AI that learns by gradually adding and then removing noise from data — the same core idea behind image generators) on a dataset of known good robot grasp poses. Once trained, that diffusion model acts as a data augmentation engine: it synthesizes entirely new candidate grasp poses that weren't in the original training set.
Stage two takes those generated poses and runs them through a physics simulator. The simulator acts as a cheap, scalable oracle — it tests each candidate grasp and produces a binary label: did the robot successfully hold the object, or not? This is crucial because collecting real-world grasp success data is expensive and slow.
The labeled synthetic grasps — both successful and failed — are then used to train a second machine learning model. This final model is the one that actually runs on the robot: it takes live sensor data (point clouds from depth cameras, for example) and outputs a grasp plan telling the robot arm exactly how and where to grip.
- Diffusion model generates novel candidate grasp poses
- Simulator labels each pose as successful or failed
- A second ML model learns from those labeled examples
- The trained model runs inference on live sensor data to plan real grasps
What this means for factory robots and AI manipulation
Robot manipulation — getting arms to reliably pick up arbitrary objects — has been a stubborn bottleneck for warehouse automation, surgical robotics, and home assistant robots. The usual problem is data: you need thousands of labeled examples of successful grasps, which are expensive to collect physically. By using a diffusion model to generate synthetic grasp poses and a simulator to label them automatically, Nvidia's approach dramatically reduces dependence on real-world data collection.
This fits squarely into Nvidia's broader push into physical AI through its Isaac robotics platform. If this pipeline generalizes well to novel objects — things the robot has never seen — it could meaningfully close the gap between controlled lab demos and real-world robot deployability. That's a gap the entire industry is racing to close right now.
This is genuinely interesting foundational work, not a incremental tweak. Using a diffusion model as a synthetic data generator — rather than directly as the grasp predictor — is a clever architectural choice that sidesteps the notoriously hard problem of getting diffusion models to produce reliably actionable outputs. The two-stage design, where generation and execution planning are separated, is the kind of practical engineering decision that tends to actually ship.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.