Nvidia Patents an AI Pipeline for Generating Animatable 3D Characters
Creating a fully rigged, animatable 3D character today takes a team of artists days or weeks. Nvidia is filing patents on a system that could compress that down to a single AI inference pass.
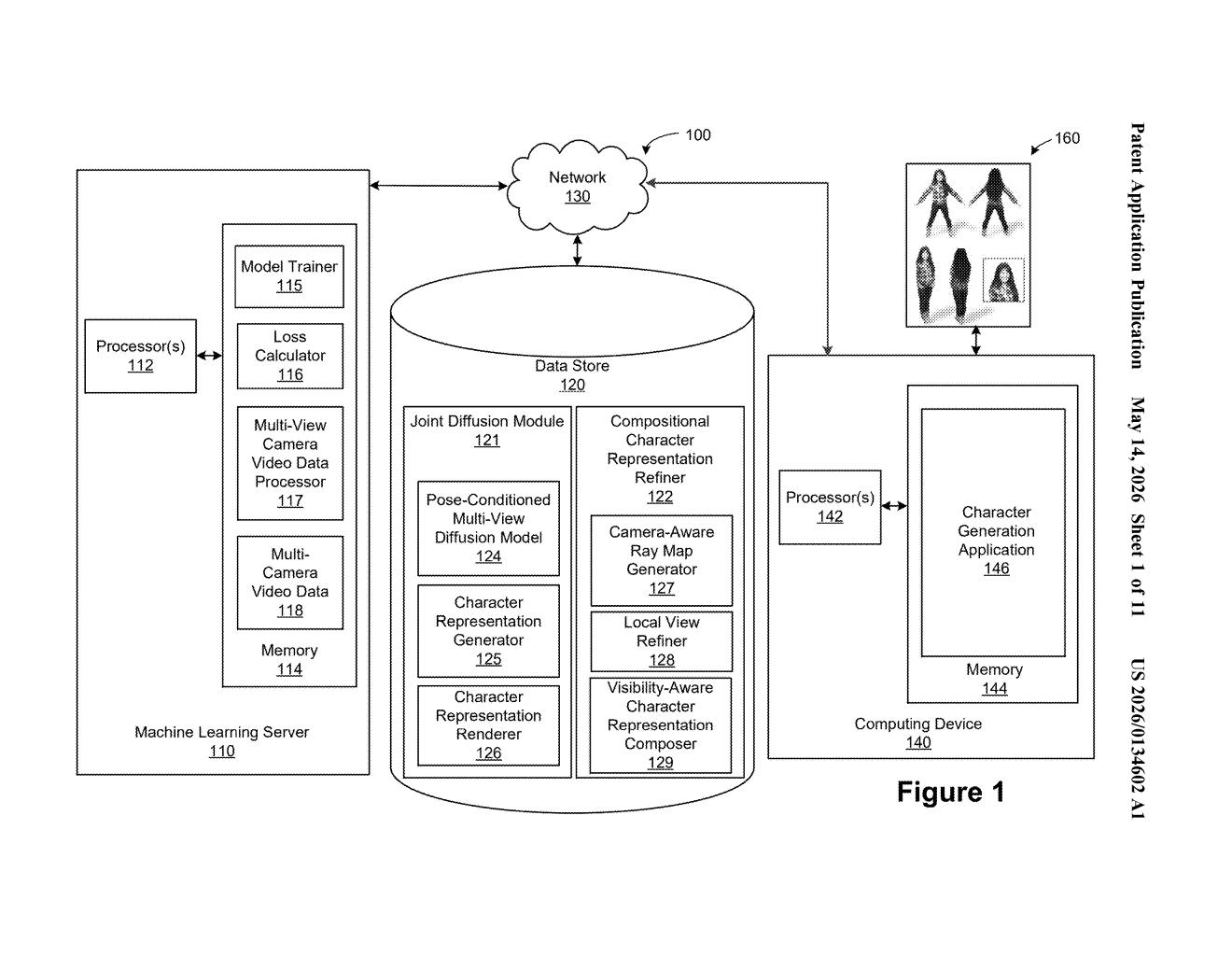
How Nvidia turns images into animatable 3D people
Imagine you want to drop a realistic human character into a video game or a virtual world. Normally, that means a 3D modeler sculpts the body, a rigger sets up the skeleton, and animators painstakingly attach everything together. It's expensive and slow.
Nvidia's patent describes a system where a diffusion model — the same kind of AI behind image generators like Stable Diffusion — looks at image data and gradually builds up a full 3D representation of a character that you can actually animate. It doesn't just produce a flat picture or a static mesh; the output is something a game engine or animation tool could move around.
The clever part is how the system uses multiple passes of refinement: a rough global shape first, then a more precise one, guided at each step by where the virtual camera is pointing. The result is a character model ready to be posed, walked, or acted — without a human artist doing the heavy lifting.
Inside Nvidia's multi-view diffusion-to-3D character pipeline
The patent describes a pipeline with several distinct stages, all tied together by a joint diffusion process.
First, a trained diffusion model generates what the patent calls predicted target image latents — compressed, abstract representations of what the character should look like from a given camera angle — along with a diffusion timestep (think of the timestep as a dial that tracks how "noisy" or incomplete the current image guess still is).
Next, a separate machine learning model takes those latents and the timestep together and produces a coarse global character representation — a rough 3D shape that describes the character's overall form at that moment in the diffusion process. A camera-aware ray map generator helps the model understand spatial geometry by encoding where each pixel maps to in 3D space relative to the camera.
That coarse representation is then refined into a second, higher-quality global representation, which is finally decoded into the animatable output — a character model that can be driven by a skeleton or pose parameters. The whole process is designed to be compositional: different body parts or views can be reasoned about jointly, keeping the final character geometrically consistent from every angle.
What this means for game development and digital humans
For game studios, VFX houses, and anyone building virtual humans, the bottleneck has never been compute — it's been artist time. A system that can output a rigged, animatable 3D character directly from a diffusion model could dramatically lower the cost of populating virtual worlds with unique characters rather than recycled assets.
Nvidia is also positioning itself squarely in the digital human and generative 3D space, where competitors like Adobe (Firefly 3D), Stability AI, and various game-engine toolchains are racing to own the workflow. A patent on the core diffusion-to-animatable-mesh pipeline — especially one that's camera-aware and multi-view consistent — could give Nvidia leverage in tools built on top of Omniverse or offered through its AI Foundry services.
This is one of the more technically substantive generative-3D patents to come out of Nvidia's research arm. The multi-view consistency problem — making sure a generated character looks right from every angle, not just the one it was trained on — is the hard unsolved piece of AI character generation, and this patent addresses it directly. If the system works as described, it's the kind of infrastructure that quietly powers a product announcement rather than becoming one itself.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.