Nvidia Patents a Compiler-Driven System for Concurrent Task Pipeline Execution
Running software tasks one-at-a-time wastes GPU muscle. Nvidia's new patent describes a compiler-level system that identifies which parts of a program can safely run at the same time — potentially squeezing a lot more work out of the same hardware.
How Nvidia's compiler splits programs to run at the same time
Imagine you're cooking a meal: instead of finishing the pasta before you start the salad, a smart kitchen assistant tells you exactly which steps you can do simultaneously. Nvidia's patent applies that same logic to software running on processors.
The idea is that a compiler — the tool that translates code you write into instructions a chip can execute — gets new smarts to flag which parts of a program can run at the same time, across one or more processors. Instead of tasks lining up in a single-file queue, they can overlap.
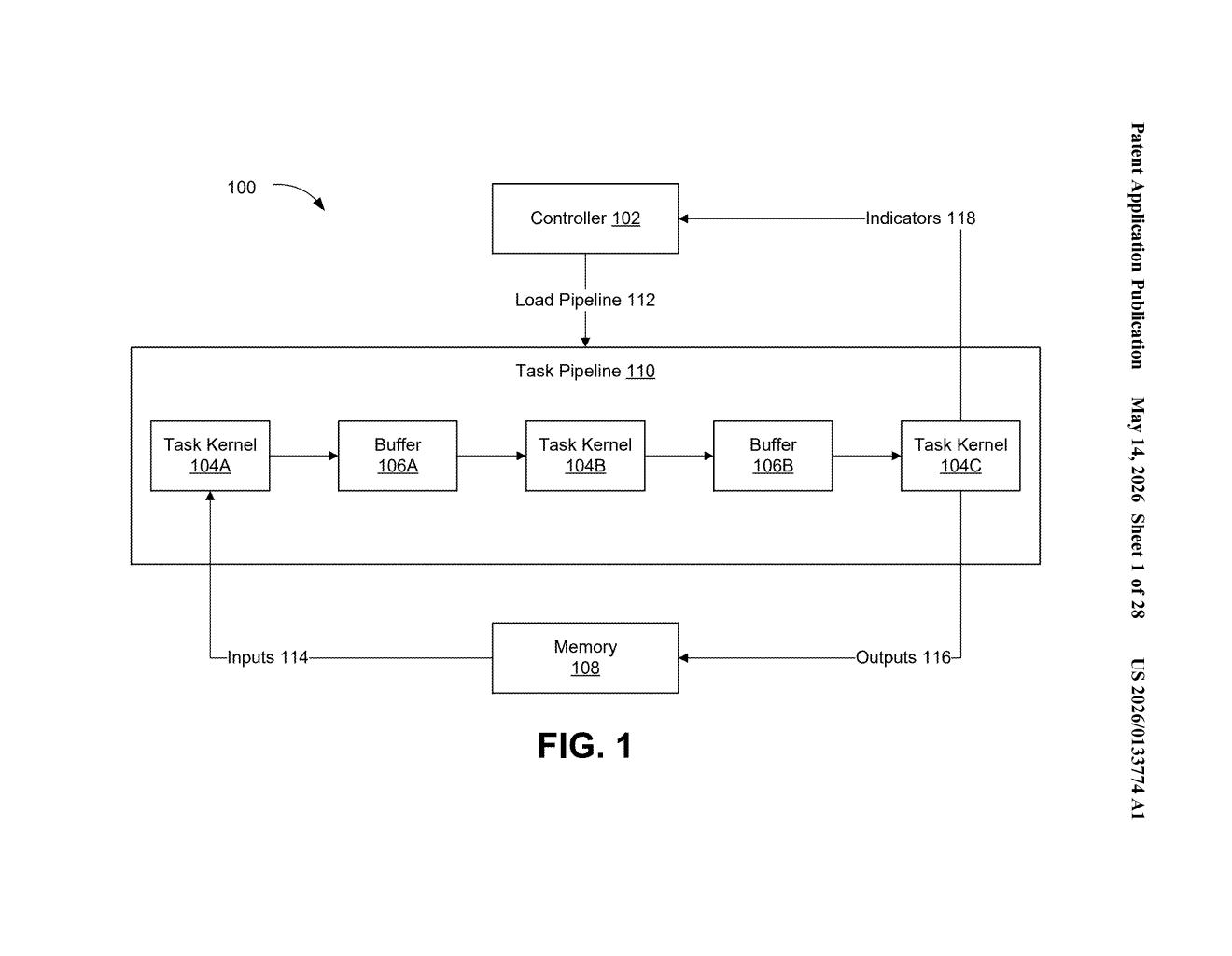
This is particularly aimed at task pipelines: sequences of operations (called kernels) that process data step by step. Rather than waiting for each kernel to finish before the next one starts, Nvidia's approach wants those kernels running concurrently wherever possible, with shared memory buffers coordinating the handoffs.
How the compiler flags pipeline sections for concurrent kernels
The patent describes a hardware-software co-design targeting sequential task pipelines — workflows where data passes through a chain of processing steps, each handled by a separate kernel (a small, self-contained GPU program).
At the core is a compiler mechanism that annotates or indicates portions of one or more software programs as candidates for concurrent execution. The compiler essentially acts as a traffic director, marking which kernels can overlap in time rather than being serialized.
The system references a few key components:
- Task Kernels (e.g., Task Kernel 104A, 104B, 104C) — the individual processing units in a pipeline
- Load Pipeline and Task Pipeline — the structured sequences those kernels belong to
- Buffer/Memory — shared staging areas (Buffer 106B) that let concurrently running kernels exchange data without stepping on each other
The net effect is substantiation of task pipelines — a term the patent uses to mean the process of materializing or instantiating these overlapping execution flows on real hardware. The claim language is broad: it essentially patents the circuit-level capability to have a compiler drive concurrent execution across processors.
What this means for GPU workload efficiency
For GPU-heavy workloads — think deep learning inference, video processing, or scientific simulation — pipeline throughput is often the real bottleneck, not raw compute. If a compiler can automatically identify and schedule concurrent kernel execution, developers get better hardware utilization without rewriting their code.
For you as a developer or researcher running inference pipelines on Nvidia hardware, this kind of compiler intelligence could mean faster end-to-end latency and higher GPU utilization out of the box. It also fits squarely into Nvidia's broader push with CUDA and its compiler toolchain to make parallel programming more automatic and less manual.
The claim language here is conspicuously broad — 'one or more circuits to cause a compiler to indicate portions of software to be performed concurrently' describes something close to a foundational compiler optimization concept. That breadth will likely draw scrutiny during examination. The underlying technical work around pipeline substantiation and kernel concurrency is real and genuinely useful, but the patent as written reads more like a placeholder staking territory than a tightly scoped invention.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.