Google Patents a System That Turns Ad Guidelines Into AI Training Data
Writing rules for what an AI is allowed to generate is one thing — turning those rules into usable training data is the hard, unglamorous part. Google's latest patent tackles exactly that.
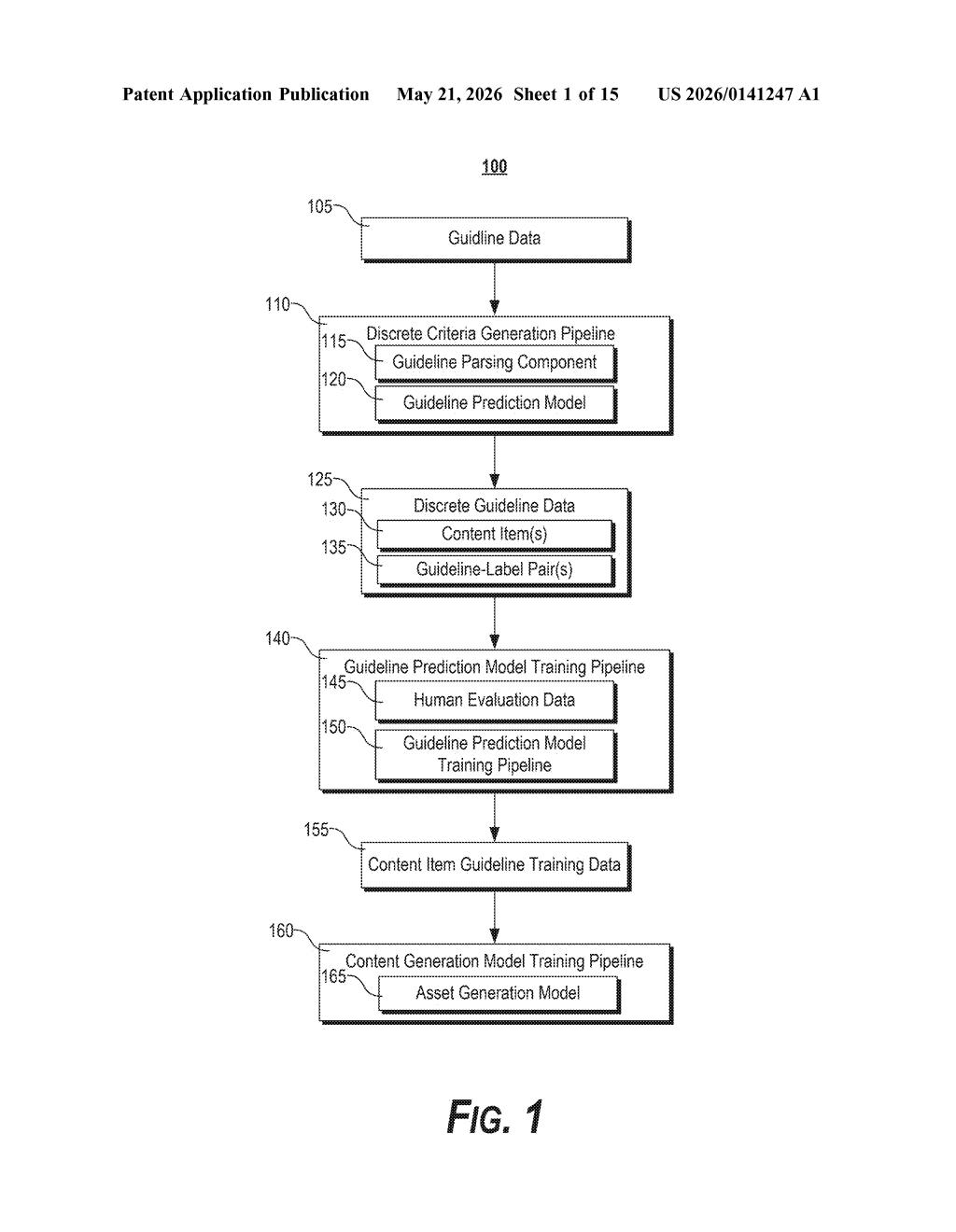
How Google auto-converts ad rules into labeled training sets
Imagine you work on a team that publishes thousands of ads a day, and every ad has to follow a long list of policies: no misleading claims, no certain images, no specific phrases. Normally, humans read those policies and then manually label example ads as 'passes' or 'fails' for each rule. That process is slow, inconsistent, and doesn't scale.
What Google is patenting is a pipeline that automates most of this work. An AI reads your policy document, breaks it into individual checkable rules, then scans an ad — text, image, or video — and stamps each rule with a 'satisfies' or 'violates' label. A human reviewer can then correct any label the AI got wrong.
Those corrected labels get folded back into a training dataset, which is then used to retrain the AI that actually generates ads. The loop closes: better-labeled data produces a better generation model, which produces ads that are more likely to pass the guidelines in the first place.
How the label-guideline feedback loop actually runs
The core of the patent is a human-in-the-loop data labeling pipeline with three distinct stages.
First, a machine-learned model reads guideline data — think a structured policy document — and parses it into a list of discrete, individually checkable criteria. Rather than treating 'our ad policy' as one monolithic blob, the system atomizes it into separate rules that can be evaluated one at a time.
Second, the system takes a piece of content (an ad asset: text copy, an image, or a video clip) and evaluates it against each discrete criterion, producing a label-guideline pair — essentially a row that says 'Rule #7: violates' or 'Rule #12: satisfies.' These pairs are surfaced to a human reviewer via a UI.
Third — and this is the key loop — if a reviewer disagrees with a label and corrects it, that correction is written into the training dataset. The system then uses this continuously updated, human-validated dataset to retrain the asset generation model (the AI that actually creates the ad content). The feedback from human corrections flows directly into making the generative model more policy-aware over time.
What this means for AI-generated ad content at scale
For Google, which runs one of the largest automated advertising systems on the planet, keeping AI-generated ad content aligned with constantly evolving policies is a real operational problem — not a theoretical one. This patent describes infrastructure for making that alignment self-improving: every human correction makes the next generation of ads slightly more compliant.
The broader implication is that this approach could generalize beyond ads to any domain where a company has written policies governing AI output — content moderation rules, brand guidelines, legal compliance checklists. If you're wondering how big platforms plan to keep generative AI output inside the lines at scale, this kind of automated guideline-to-training-data pipeline is a big part of the answer.
This is genuinely useful infrastructure work, not a flashy AI demo. The clever part isn't any single ML technique — it's the closed feedback loop where human label corrections automatically improve the generative model downstream. For anyone building AI systems that have to comply with rules, this is a practical blueprint worth studying.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.