Microsoft Files Patent for AI-Generated URLs That Help Search Engines Find Hidden Content
Most search engines can only find pages they've already seen. Microsoft is patenting a system that asks an AI to guess what relevant URLs *should* exist — then goes and checks if they do.
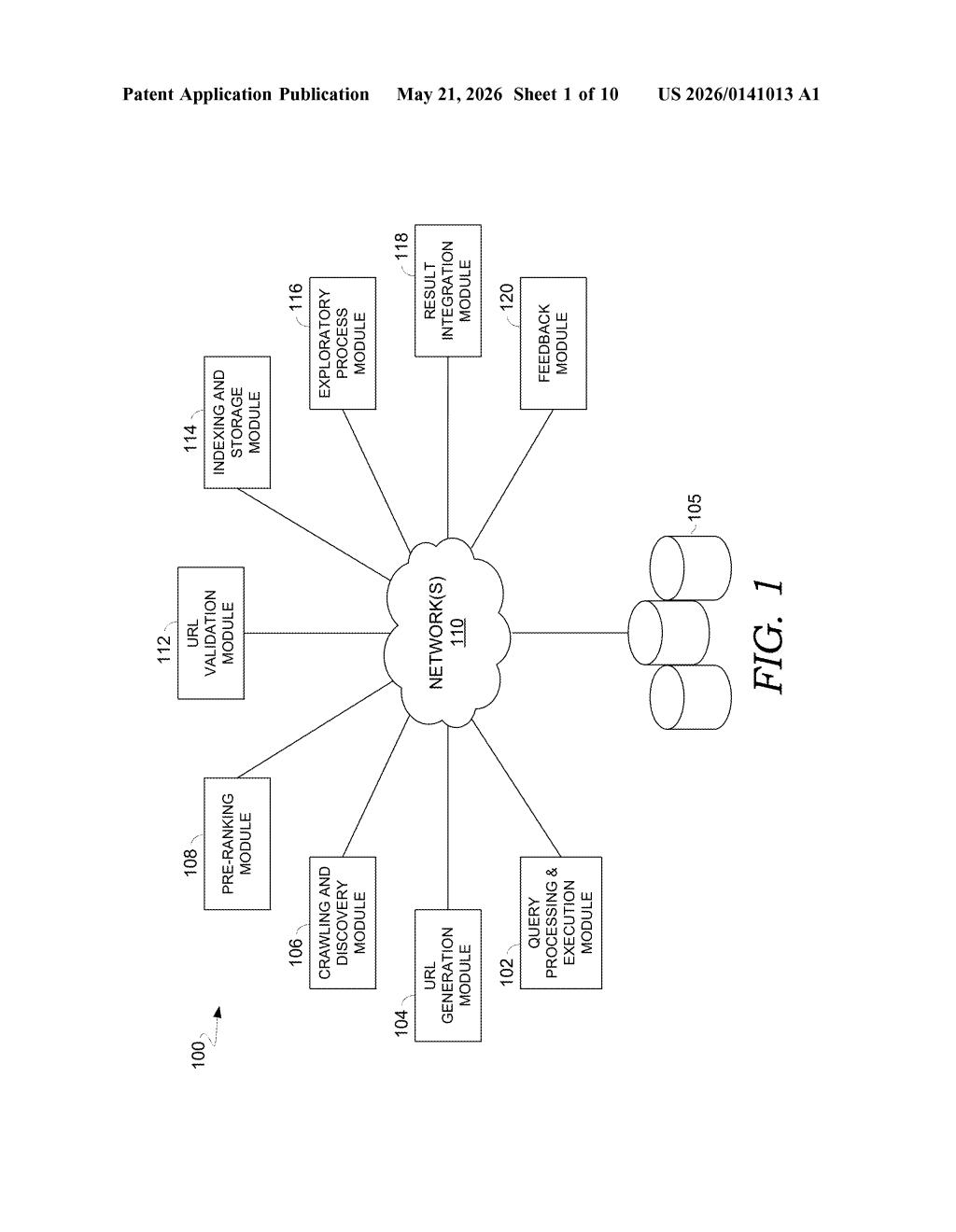
What Microsoft's real-time URL generation actually does
Imagine you search for today's match results from a sports team, but the search engine's index hasn't crawled that page yet. Normally, you'd get stale results or nothing useful. Microsoft's patent describes a way around that problem.
Instead of only searching pages it already knows about, the system feeds your query into a large language model — the same kind of AI behind ChatGPT — and asks it to generate plausible URLs where that content might live. It then visits those URLs to see if they're real, pulls the content, and serves it to you, often adding it to the index for future searches.
There's also a second mode: starting from those AI-generated URLs as "seeds" and following all the outgoing links on the page, crawling deeper into new territory the search engine has never visited. It's a bit like giving your GPS the ability to invent new roads and then check whether they actually exist.
How the LLM generates, validates, and indexes new URLs
The patent describes a two-stage pipeline layered on top of a traditional search index.
Stage 1 — URL generation: When a query arrives, the system can optionally route it to an LLM inference endpoint alongside contextual signals (location, hashtags, grounding data). The model's job is to hallucinate plausible URLs — essentially predicting what a relevant page's address would be — based on patterns it learned during training. Those candidates are then fetched and validated in real time.
Stage 2 — Outlink crawling: Once a generated (or pre-existing "seed") URL is validated, the system can extract all the outgoing links from that page, de-duplicate them, and feed them into an asynchronous crawl queue. New content discovered this way gets indexed immediately and can satisfy the original query before the crawl is even complete.
- Hashtag-to-seed matching maps social signals to candidate URLs
- Query-to-seed prompting directs the LLM to generate domain-specific guesses
- A results coordinator merges LLM-sourced content with traditional index results
The system is explicitly designed to run in real time — the fetching, indexing, and serving all happen within the lifecycle of a single search query, not as a background crawl job.
What this means for Bing and the future of web search
Search engines have always been retrospective — they find what they've already indexed, which can be hours or days behind the live web. This patent pushes Bing toward a model where the index is continuously extended at query time, making freshness a function of AI inference speed rather than crawl schedules. For breaking news, live scores, or any fast-moving content vertical, that's a meaningful shift.
It also signals how Microsoft sees LLMs fitting into search infrastructure — not just as answer-generators sitting on top of an index, but as active participants in building that index. If this works reliably, it could reduce the structural advantage that large, frequently-crawled indexes currently hold over newer or more focused search tools.
This is a genuinely interesting architectural bet. Using an LLM to predict URLs rather than just summarize content is a clever inversion — the model's memorization of URL patterns during training becomes a live discovery tool. The obvious risk is hallucinated URLs that don't exist or lead somewhere harmful, and the patent is light on how that's mitigated at scale. Still, it's worth watching as a signal of where Microsoft thinks Bing's index freshness problem gets solved.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.