Microsoft Patents a Cost-Cutting Routing System for AI Coding Assistants
Running every developer keystroke through a massive cloud LLM is expensive. Microsoft's new patent describes a routing layer that quietly decides when a cheaper local model will do just as well — and only escalates to the big model when it has to.
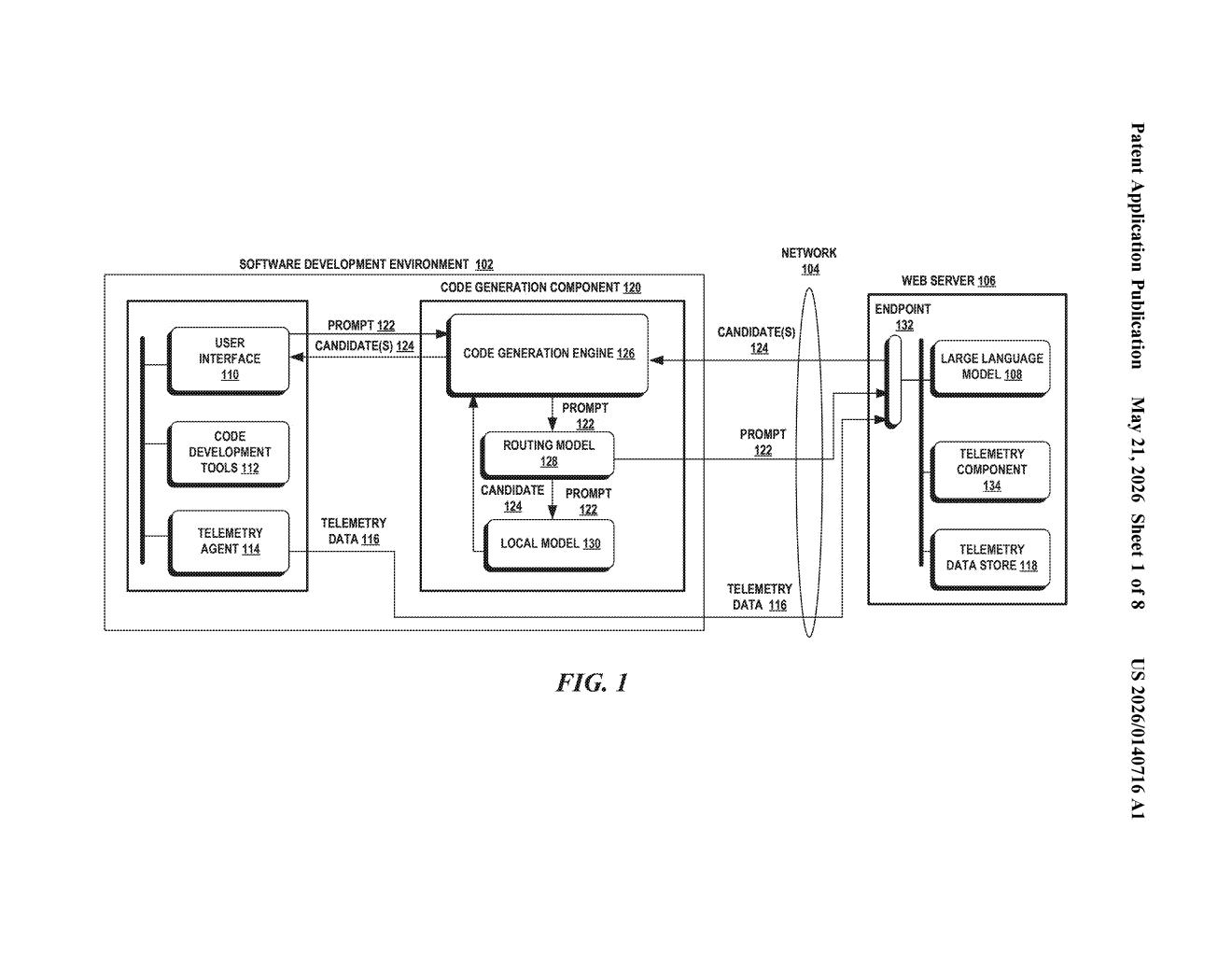
How Microsoft's coding assistant picks cheap vs. powerful AI
Imagine you ask your AI coding assistant to autocomplete a for-loop. A system that routes every request — no matter how simple — to a giant cloud model is like calling a head chef every time you need toast. It works, but it wastes enormous resources.
Microsoft's patent describes a middleman called a routing model. Before your coding prompt ever reaches a large language model in the cloud, this lightweight router asks a question: "Would the big model's answer even be accepted by the user? And could the smaller, local model produce something nearly identical?" If the answer is yes, your prompt goes to the local model instead — faster and cheaper.
The clever part is how the router learns. It's trained on the history of what developers actually accepted or rejected from the coding assistant. Over time, it builds an intuition for which prompts really need the heavy-duty model and which ones don't.
How the routing model decides which model gets your prompt
The system has three main moving parts:
- The routing model — a small, trained classifier that sits in front of the LLM. It evaluates an incoming coding prompt and predicts two things: (1) is the big LLM likely to generate something the user will accept, and (2) would a local model produce a sufficiently similar result? Think of it as a triage nurse deciding whether you need the ER or just a bandage.
- The large language model (LLM) — the cloud-hosted, high-capability model (think GPT-4-class). It handles complex, novel, or ambiguous requests where the local model would fall short.
- The local model — a smaller, lower-cost model running closer to the user or on cheaper infrastructure. It handles routine, predictable coding tasks.
The routing decision is deterministic — meaning once the router makes its call, the prompt goes to exactly one destination, not both. This is important: there's no latency tax from hedging.
Critically, the routing model is trained on historical acceptance data — real records of which LLM outputs developers accepted or rejected in the coding assistant. This grounds the router in actual user behavior rather than abstract quality metrics.
What this means for GitHub Copilot's cloud bill — and yours
The cost of running a coding assistant at scale is dominated by LLM inference — every token generated in the cloud has a price. A routing layer that can offload even 30-40% of prompts to a local model could represent significant savings, which matters a lot if you're Microsoft operating GitHub Copilot at enterprise scale.
For you as a developer or an enterprise buyer, the downstream effect is potentially lower subscription costs or higher usage limits for the same price. There's also a latency angle: local model responses can be faster, meaning the assistant feels snappier for the simple completions you trigger dozens of times per hour.
This is unglamorous but genuinely important infrastructure work. The idea of routing between models based on predicted acceptance — rather than just complexity heuristics — is a meaningful design choice that grounds the system in actual user behavior. If Microsoft ships this in Copilot, it's the kind of optimization that quietly keeps the product economically viable at massive scale without degrading the experience developers notice.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.