Microsoft Patents a Two-LLM Pipeline for Clustering Large Text Datasets
Sorting thousands of customer comments, support tickets, or survey responses into meaningful topics is tedious work — and Microsoft just patented a way to hand it off to two language models working in parallel.
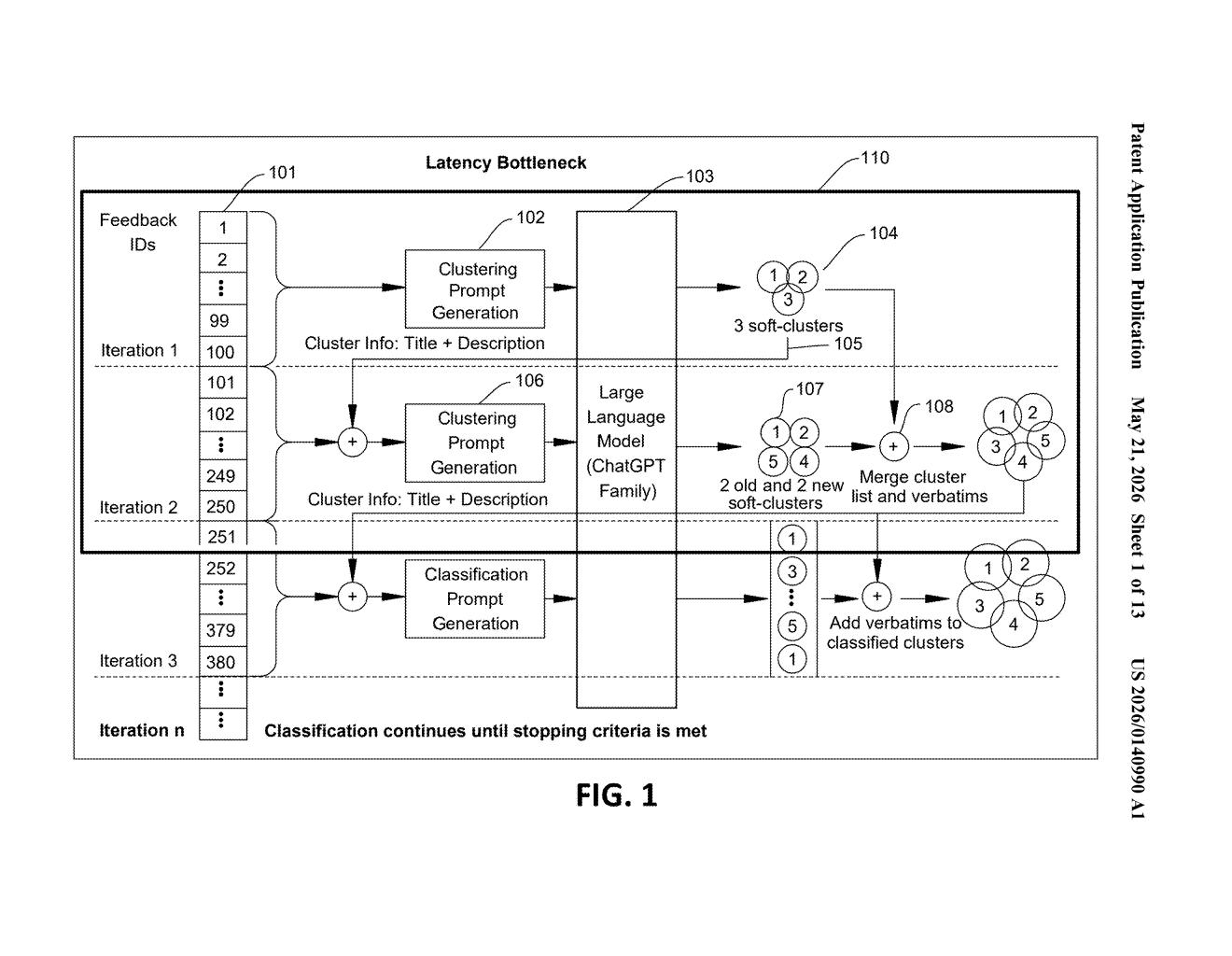
What Microsoft's 3-phase text clustering actually does
Imagine your company collects 50,000 customer feedback responses and needs to group them by theme — billing complaints, feature requests, login issues, and so on. Doing that by hand is a nightmare. Even asking a single AI to do it all at once hits limits on how much text it can process at one time.
Microsoft's approach splits the job into three phases. First, it chops the dataset into smaller chunks and sends each chunk to a language model simultaneously, asking each one to identify the themes it sees. Second, all those draft themes get merged and de-duplicated into one clean master list. Third, a second language model goes back through every item in the original dataset and assigns each one to a theme from that master list.
The result is a structured output telling you exactly which piece of text belongs to which topic — at a scale that would be impractical to do in a single AI call.
How the two LLMs divide, merge, and classify at scale
The patent describes a three-phase pipeline for large-scale text classification using two distinct language models.
Phase 1 — Parallel theme discovery: The dataset is divided into partitions (chunks), and a first language model receives all partitions via concurrent calls — meaning they're processed simultaneously, not sequentially. Each call returns a list of themes found in its partition.
Phase 2 — Theme consolidation: The themes from all partitions are merged. This step handles overlap and redundancy — two partitions might both surface a "pricing" theme, and the consolidation step collapses those into a single canonical theme. The output is a unified set of themes that represents the whole dataset.
Phase 3 — Parallel classification: A second language model receives the master theme list and processes every individual item in the dataset — again in parallel — assigning each text statement to the appropriate theme.
Using two separate LLMs (one for discovery, one for classification) is a deliberate architectural choice: it lets each model be optimized for its specific task, and the parallel execution at both phases makes the system practical for datasets too large for a single sequential LLM call.
What this means for enterprise data analysis tools
For any enterprise tool that needs to make sense of large volumes of unstructured text — think customer surveys, support tickets, employee feedback, or product reviews — this kind of automated clustering is a core workflow. Microsoft's products like Dynamics 365, Azure AI, and Viva are natural homes for this kind of capability, and the parallel architecture means it could scale to very large datasets without becoming prohibitively slow or expensive.
The two-model design is also interesting from a cost angle: you could use a cheaper, faster model for the bulk classification phase (Phase 3) and reserve a more capable model for the nuanced theme-discovery work. That's a practical engineering tradeoff that would matter a lot at enterprise scale.
This is a solid, practical patent for a real workflow problem — not a moonshot. The three-phase parallel architecture is a sensible engineering solution to the context-window and throughput limits of current LLMs, and it's the kind of thing that would ship quietly inside an existing Microsoft analytics product rather than get its own press release. Worth watching if you follow enterprise AI tooling.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.