Red Hat Patents a Runtime-Built Alpha Network for Rule Engines
Rule engines typically lock in their decision-making structures at startup — Red Hat's new patent lets that structure build and reshape itself on the fly, based on the actual data flowing through it.
What Red Hat's dynamic rule network actually does
Imagine a massive sorting machine at a warehouse. Normally, you have to design every conveyor belt and gate before the first package arrives. If the packages turn out to be different shapes than expected, you're stuck with a layout that doesn't fit.
Red Hat's patent covers a rule engine — software that evaluates business logic like "if a customer has overdue payments AND a credit score below X, flag the account" — where the filtering structure builds itself based on the data it actually sees, instead of being pre-wired at startup. The system watches data objects flow in and constructs the necessary decision pathways in memory on demand.
The practical upside: a rule engine no longer has to pre-allocate structure for every possible condition up front. Rules can adapt to the real shape of incoming data, which matters a lot in enterprise environments where the rule sets are large, complex, and constantly changing.
How the alpha network builds itself from live data objects
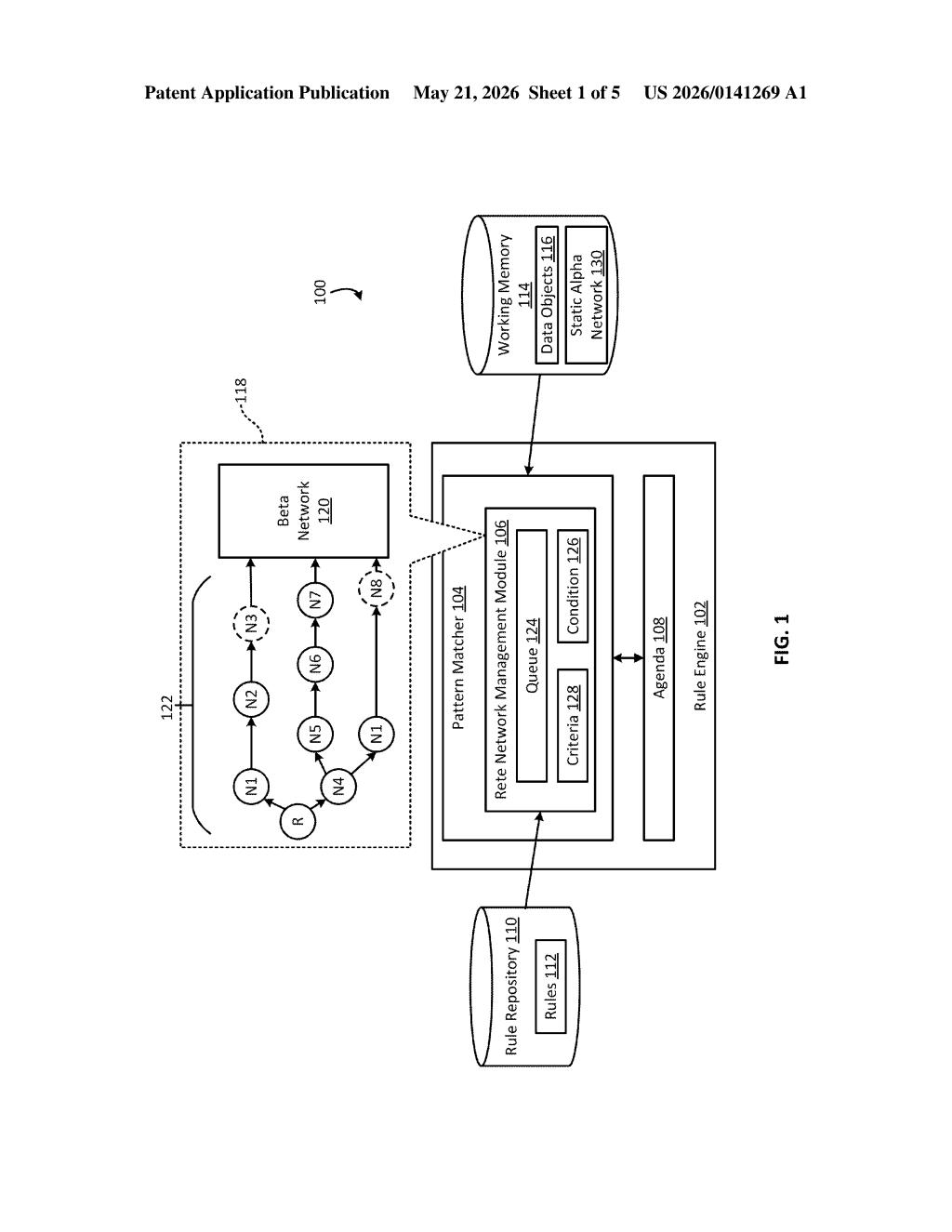
The patent targets the Rete algorithm — a classical pattern-matching algorithm (invented in the 1970s, still widely used in enterprise rule engines like Drools) that evaluates rules efficiently by breaking them into a network of nodes. That network has two halves: an alpha network (filters individual facts against single-condition constraints, like "is this object a Customer?") and a beta network (joins multiple filtered facts together to check compound conditions).
Traditionally, the entire alpha network is compiled and fixed at rule-load time. This patent describes building the alpha network dynamically in memory during execution — specifically, letting the network nodes materialize as data objects actually propagate through them rather than pre-building every possible path.
- Data objects enter the rule engine's Working Memory
- Alpha nodes are constructed on-demand as matching objects propagate
- The resulting network is then used to route facts onward to the beta network for join evaluation
- The network can be further modified as new data arrives or rules change
The key claim is that alpha node construction is driven by data propagation itself — the structure emerges from use rather than being declared up front.
What this means for enterprise rule engine performance
For teams running large-scale rule engines — think insurance underwriting platforms, fraud detection pipelines, or ERP business logic — startup time and memory footprint can be real bottlenecks. A static alpha network has to account for every possible rule condition at load time, even ones that rarely trigger. A lazily-constructed network means you only pay for the structure you actually use.
This is particularly relevant for Red Hat's Drools ecosystem, one of the most widely deployed open-source rule engines in enterprise Java. If this technique ships there, large rule sets could become faster to initialize and more memory-efficient at scale — which translates directly into cheaper cloud compute for the organizations running them.
This is a focused, unsexy infrastructure improvement — exactly the kind of thing that Drools contributors and enterprise architects care about deeply and nobody else notices. The dynamic construction approach is a real engineering tradeoff worth making for large rule sets, and the fact that two of Drools' core architects (Mark Proctor is essentially the creator of Drools) are the inventors suggests this isn't speculative — it's probably already in progress.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.