Adobe Patents a System for Blending Real Images and Text Into One AI-Generated Scene
You have a photo of a vintage lamp and a text description of an antique typewriter — Adobe's new patent lets an AI combine both into a single, coherent generated image without you ever having to draw the typewriter yourself.
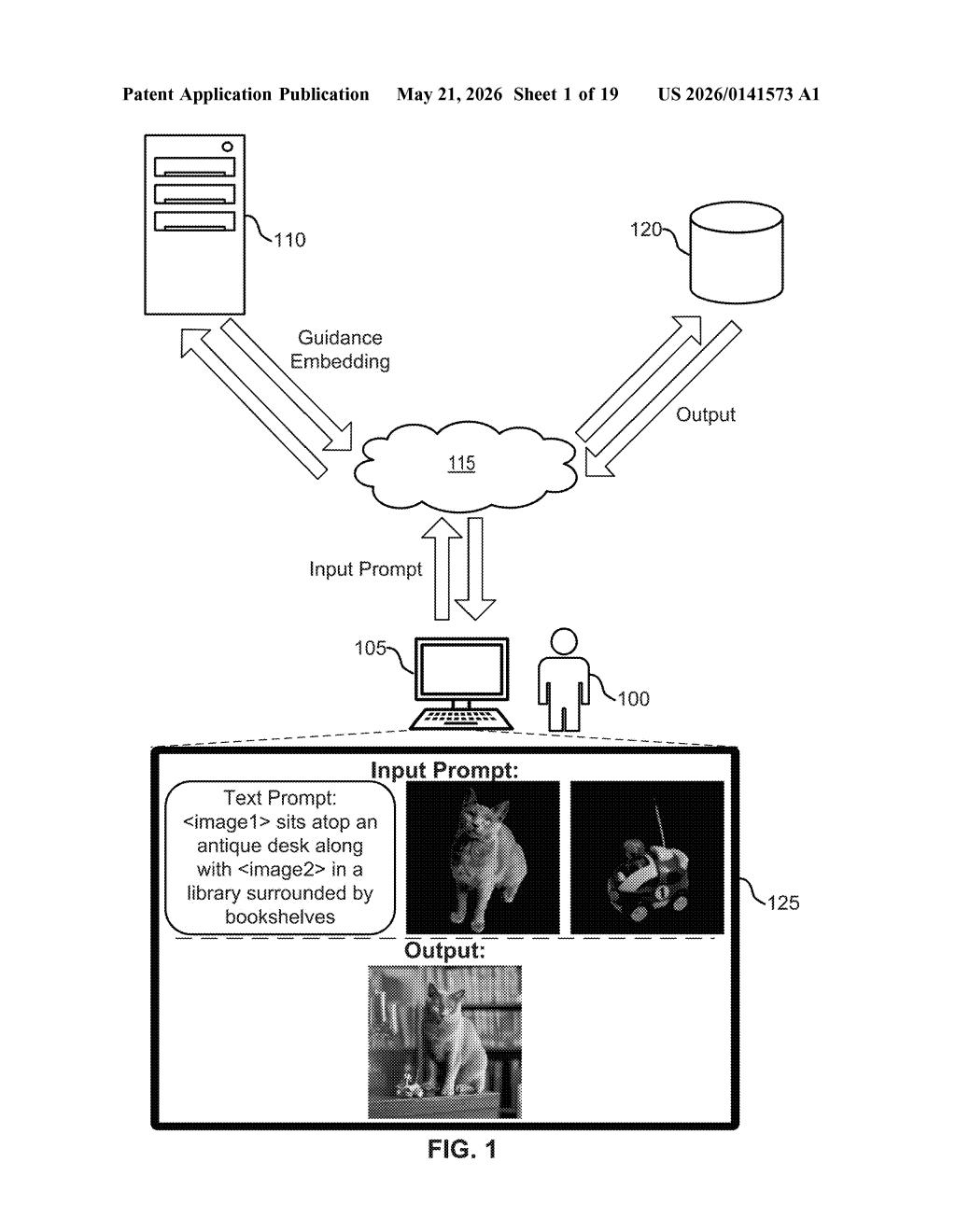
What Adobe's multi-concept image blending actually does
Imagine you want to generate an image of two specific things together — one you have a photo of, and one you can only describe in words. Today's AI image tools generally want you to work in one mode at a time: either describe everything in text, or use a reference image. That handoff is clunky.
Adobe's patent describes a system that takes a real photo (say, a picture of your cat) and a text prompt (say, "a velvet armchair") and fuses them into a single AI-generated scene where both appear together. The system translates both inputs into a shared mathematical representation before passing that to an image generator.
The example in the patent is pretty vivid: a prompt like "<image1> sits atop an antique desk along with <image2> in a library." You supply one real photo for each placeholder, and the system places them both in the scene. It's the kind of workflow Adobe's Firefly users have been asking for.
How the mapping encoder bridges two embedding spaces
The patent describes a three-stage pipeline built around the idea that images and text need to live in the same conceptual space before you can generate something coherent from both.
Stage 1 — Multimodal embedding: The system ingests both the input image and the text prompt and produces a multimodal embedding (think of it as a single numeric "fingerprint" that captures both the visual concept from the photo and the linguistic concept from the text, compressed into one vector space).
Stage 2 — Guidance embedding via mapping encoder: A dedicated mapping encoder then translates that multimodal embedding into a guidance embedding — a different, separate vector space tuned specifically for steering an image diffusion model. This two-space design is the core architectural claim: the multimodal LLM's native embedding space and the diffusion model's conditioning space are not the same, and the mapping encoder bridges them.
Stage 3 — Image generation: The guidance embedding is fed into a standard image diffusion model (a class of AI that generates images by progressively denoising random pixels — the same family as Stable Diffusion or Firefly) to produce the final synthetic image containing both concepts.
The "multi-concept adaptor" framing in the title refers to the system's ability to handle multiple distinct visual and textual concepts simultaneously, rather than collapsing them into one blurry average.
What this means for Adobe's generative AI pipeline
For Adobe, this is plumbing for a more natural Firefly workflow. Right now, compositing two specific reference objects into one AI-generated scene typically requires manual masking, multiple generation passes, or heavyweight inpainting tricks. A native multi-concept pipeline would let Firefly handle that in one shot — which is a real competitive pressure point against Midjourney's reference-image features and Google's Imagen 3 compositing work.
For you as a designer or photographer, the practical upside is clear: you could drop in a product photo you already have, describe the lifestyle context you want around it, and get a coherent composite without Photoshop surgery. Whether Adobe ships this as a discrete Firefly feature or bakes it into Express or Creative Cloud workflows, the underlying patent covers the mapping-encoder architecture that makes it possible.
This is solid, focused AI infrastructure work — not a splashy consumer feature, but the kind of embedding-space translation patent that becomes quietly essential once Adobe's generative tools mature. The two-space design (multimodal LLM space → diffusion guidance space via a learned encoder) is a real engineering problem, and claiming that bridge explicitly is smart IP strategy. Worth watching as Firefly's reference-image capabilities expand.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.