Qualcomm Patents a System That Skips Its Own ML Model to Save Power
What if your phone's AI could decide, mid-task, that it doesn't actually need to run the full neural network? Qualcomm is patenting exactly that — a lightweight simulator that stands in for the real model whenever the real model would be overkill.
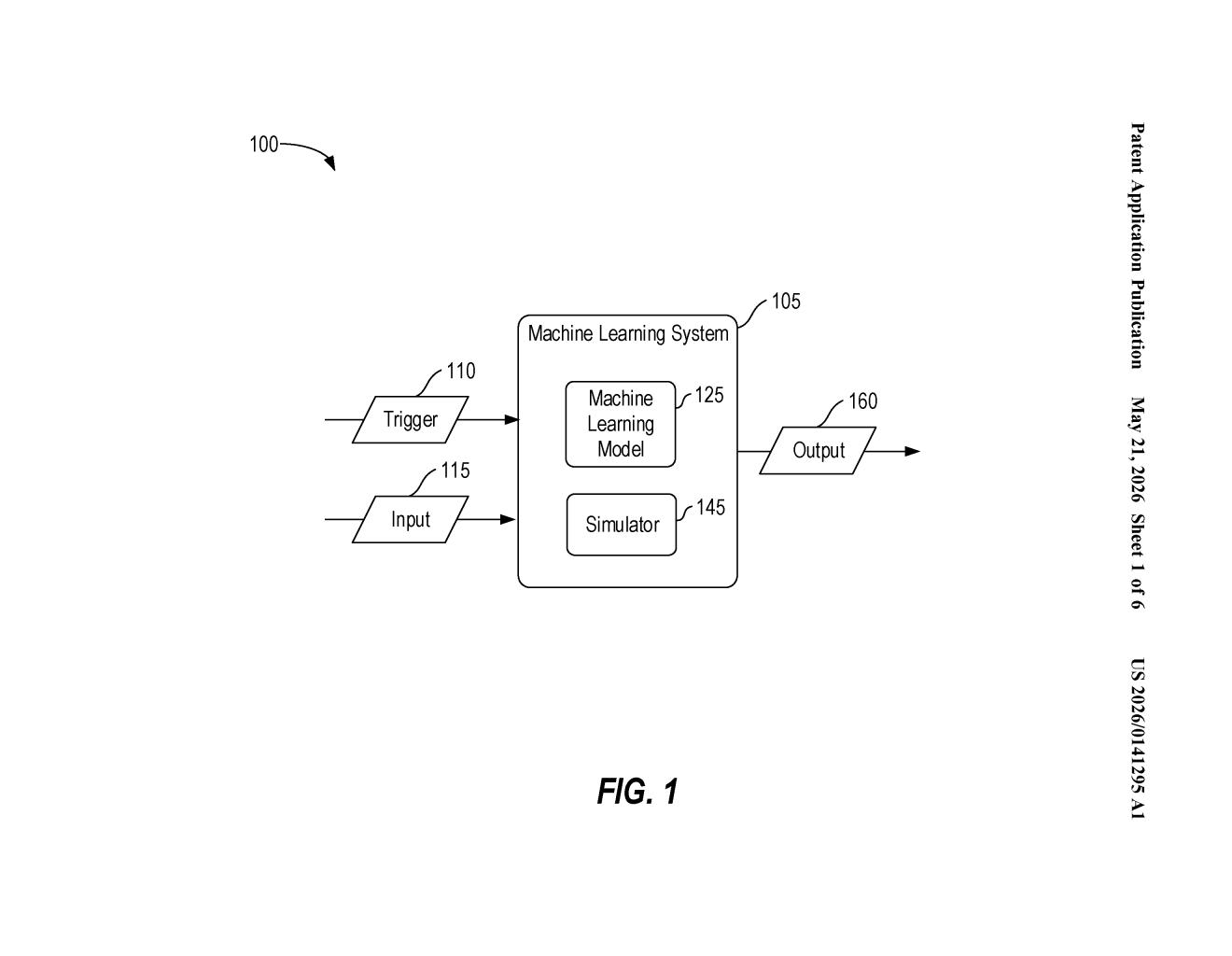
What Qualcomm's selective ML execution actually does
Imagine your phone uses an AI model to filter noise from your microphone during a call. Most of the time, the audio is pretty similar from one moment to the next — running a full neural network on every single audio chunk is expensive and drains your battery fast.
Qualcomm's idea is to run the full ML model once, then immediately spin up a much cheaper simulator to imitate what the model would have done next. If the simulator's output closely matches the real model's output — meaning the error between them is small — the system skips running the full model for the next batch of data and just uses the simulator instead.
When the two start to diverge (the error grows), the system knows things have changed enough to bring the full model back. It's a bit like cruise control: you let the car hold a steady speed on its own until road conditions change enough that you need to take over. The result is dramatically lower compute usage without losing meaningful accuracy.
How the simulator decides when to skip the full model
The patent describes a three-step loop that governs whether a full ML model actually needs to run on each new chunk of input data.
- Step 1 — Run the real model: The ML model processes the first batch of input data and produces a model output. This is the expensive step — think a full forward pass through a neural network.
- Step 2 — Run the simulator: A lightweight model simulator (a simpler approximation of the ML model) takes that same model output and generates its own prediction of what the next output should look like.
- Step 3 — Measure the error: The system computes the gap between what the simulator predicted and what the real model actually produced. If the error is below a threshold, the real model is skipped for the next input batch and the simulator carries the load. If the error is above the threshold, the real model is invoked again.
The key insight is that many real-world data streams — audio, sensor readings, video — change slowly and predictably most of the time. A cheap simulator can track those gradual shifts without needing the full model's horsepower. The full model is reserved for moments of genuine change or uncertainty, which keeps compute and power consumption low on average.
The claim is device-agnostic, but Qualcomm's core market is mobile and edge silicon (Snapdragon SoCs), where power budgets are tight and ML inference is increasingly always-on.
What this means for on-device AI on Snapdragon chips
For Qualcomm, whose Snapdragon chips power a huge share of Android phones and increasingly run always-on AI features, inference efficiency is a direct competitive lever. If your chip can deliver the same AI output quality while burning less power, that's a genuine battery-life and thermal win — things real users notice.
This approach is also architecture-friendly: it doesn't require a smaller model or quantization tricks (which can hurt accuracy). Instead, it's a dynamic scheduling layer on top of whatever model is already there. That means it could, in principle, be applied to many existing ML pipelines — noise suppression, keyword detection, camera scene analysis — without retraining anything.
This is unglamorous but genuinely useful engineering. The idea of using a cheap proxy to decide when to invoke an expensive model is well-established in systems design — Qualcomm is applying it specifically to ML inference scheduling on edge hardware. It's not a flashy AI capability play; it's the kind of power-efficiency patent that quietly ends up in shipping silicon. Worth paying attention to if you follow on-device AI.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.