Salesforce Patents a User-Directed Pipeline for Building Multimodal AI Training Data
Teaching an AI to understand images is only as good as the training data you feed it — and most pipelines for generating that data are opaque black boxes. Salesforce is patenting a system that makes the whole process transparent and user-configurable.
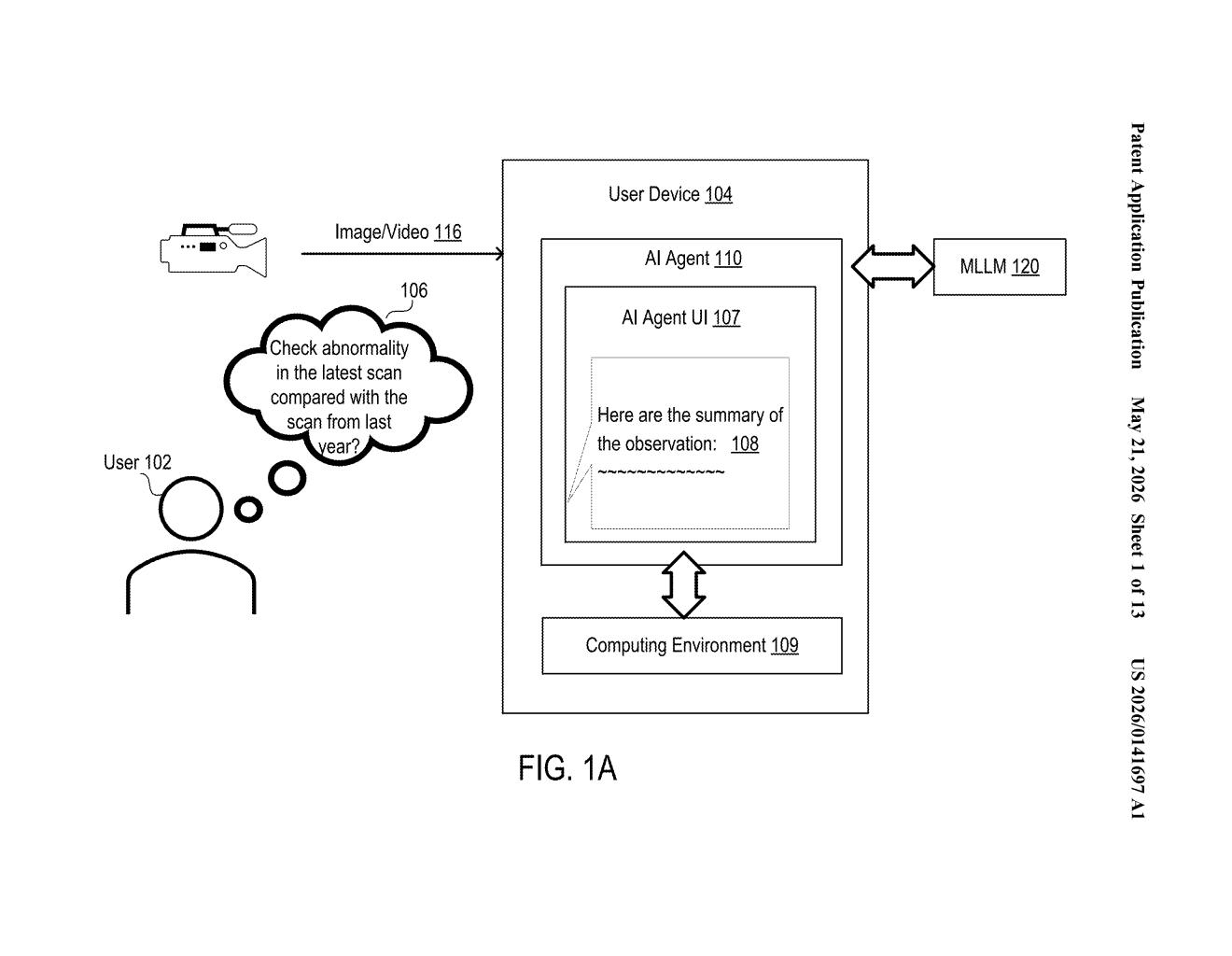
How Salesforce turns images into AI training questions
Imagine you want to teach an AI assistant to look at a photo and answer questions about it — things like 'what objects are in the scene?' or 'what is the red object sitting next to?' To do that, you need thousands of image-and-question pairs as training examples. The problem is that generating those pairs automatically, at scale, often introduces hidden biases or errors that are hard to trace.
Salesforce's approach puts a human in the loop at the start. You pick what kinds of questions you want the system to generate — about objects, their attributes, their relationships, or how they're spatially arranged. The system then analyzes each image, builds a structured map of everything in it (called a scene graph), and uses rule-based code scripts to generate question-answer pairs from that map.
Because the rules are explicit code rather than a neural net making fuzzy guesses, you can audit exactly why any given training pair was generated. The resulting dataset is then used to train a multimodal AI — one that can both see and read.
How scene graphs become structured Q&A training pairs
The patent describes a multimodal training data generation pipeline with three main stages.
First, a set of image recognition models analyzes each image in the training corpus. These specialized models handle distinct tasks:
- Object detection (identifying what things are present)
- Attribute recognition (color, size, texture)
- Relationship detection (spatial or semantic links between objects)
- Segmentation (pixel-level boundaries of each object)
Next, the outputs from those models are compiled into a scene graph — a data structure where each detected object becomes a node and each relationship between objects becomes an edge (think of it like a network diagram of a photo's contents). Scene graphs are a well-established representation in computer vision; the novelty here is using them as the canonical intermediate format before generating training text.
Finally, rule-based code scripts (not a neural net) traverse the scene graph and generate question-answer pairs. Because the logic is deterministic code, the provenance of every training example is fully auditable — you know exactly which rule produced which Q&A pair. A user interface lets practitioners select which annotation types to target, so the resulting dataset can be tuned toward specific downstream tasks. The trained model is then used to build a multimodal AI agent capable of visual content detection across multiple images.
What this means for bias in vision-language AI models
The biggest unsolved problem in training vision-language models isn't model architecture — it's data quality. Most large multimodal datasets (think LAION or similar) are scraped from the web and carry unknown biases baked in at collection time. A pipeline that generates training pairs from explicit rules, rather than crowd-sourced captions or another neural net's guesses, gives Salesforce's enterprise customers something valuable: a paper trail for why the AI behaves the way it does.
For Salesforce, which sells AI tooling to regulated industries like financial services and healthcare, that auditability angle is a real product differentiator. If your AI agent flags a piece of visual content incorrectly, you want to be able to explain exactly what training signal caused that behavior — and this system is designed to let you do exactly that.
This is solid, unglamorous AI infrastructure work — the kind of thing that rarely gets attention but genuinely matters when you're trying to build trustworthy enterprise AI. The scene-graph-to-Q&A approach isn't new to academic research, but Salesforce packaging it as a user-directed, auditable pipeline with a UI for selecting annotation types is a practical enterprise angle worth watching.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.