Salesforce Patents an LLM Training Loop That Learns From Ambiguous Code Autocomplete Signals
When a developer ignores a code suggestion and just keeps typing, did they really reject it — or were they just faster than the autocomplete? Salesforce's new patent is built around that exact ambiguity.
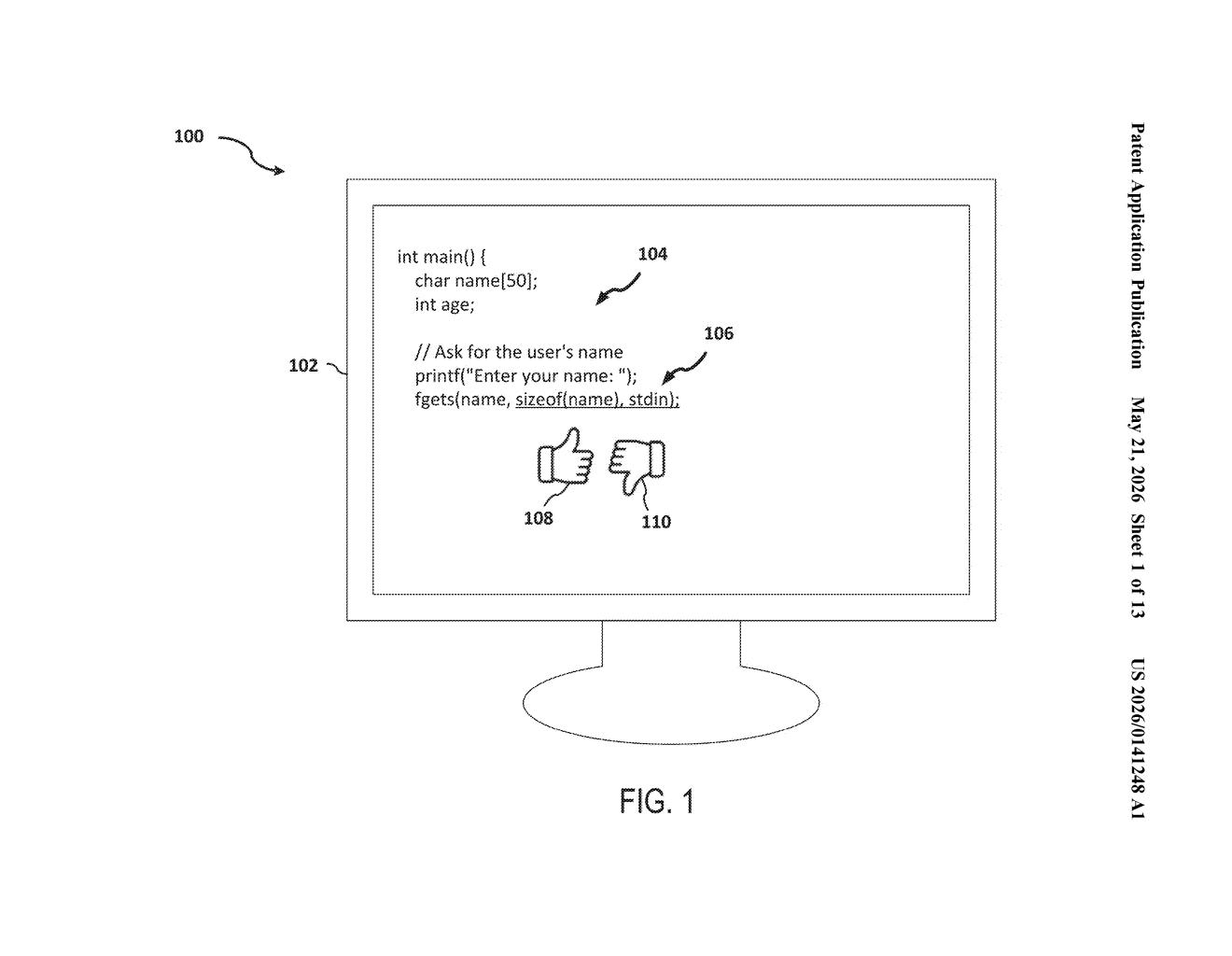
What Salesforce's 'partial rejection' training actually does
Imagine you're using an AI coding assistant and it suggests a line of code. You might click 'accept,' you might hit 'reject,' or you might just keep typing and ignore it entirely. That third option is the tricky one. Did you ignore it because it was wrong, or because you typed faster than you thought? From the model's perspective, it's genuinely unclear.
Salesforce's patent tackles this by treating those silent dismissals as partially observed — meaning the model doesn't blindly assume you rejected the suggestion. Instead, it uses a separate trainable component to estimate how likely you were to accept that specific suggestion, given everything it knew in the moment.
That estimated acceptance likelihood then shapes how much the model learns from your behavior. If the system was fairly confident you'd accept and you still ignored it, that's a stronger signal. If it wasn't sure either way, it adjusts how hard it updates. The goal is to train better code completion models from the messy, ambiguous signals that real users actually generate.
How the threshold model handles noisy acceptance signals
The patent describes a training framework for a neural network language model (LLM) focused on code completion — think GitHub Copilot-style inline suggestions. The core problem it solves is that standard training assumes user feedback is clean and accurate. In practice, it isn't.
The system introduces two jointly trained components:
- The language model itself, which generates a predicted probability for a given code completion being contextually correct.
- A threshold prediction model, which estimates — based on the same context — how high that probability needs to be before a typical user would accept the suggestion. Think of it as modeling user pickiness dynamically rather than assuming a fixed bar.
During training, a loss function (the mathematical signal the model uses to update itself) is computed by comparing the model's predicted acceptance probability against what the user actually did. Crucially, the loss is passed through a loss shaping function — a scaling mechanism that weights the update based on how ambiguous the signal was. An implicit rejection (user kept typing) triggers a softer update than an explicit click-to-reject.
Both the language model and the threshold model are trained together end-to-end, so the system learns not just what good code looks like but also what kinds of suggestions specific users in specific contexts are likely to accept.
What this means for AI coding tools trained on real behavior
AI coding assistants live or die by the quality of their training data, and most of that data comes from exactly this kind of messy, real-world usage. If every ignored suggestion is treated as a hard rejection, the model learns the wrong lessons — your silence isn't always disapproval. This patent offers a more principled way to extract signal from noise, which could mean coding tools that improve faster and more accurately from deployment data.
For Salesforce, whose Einstein and Agentforce platforms increasingly involve AI-assisted development, a better preference-alignment pipeline for code models is a real competitive lever. The technique also fits neatly into the broader industry push to move beyond simple RLHF (reinforcement learning from human feedback) toward methods that handle real-world label imperfection more gracefully.
This is genuinely useful AI infrastructure work, not a product feature — but it addresses a real and underappreciated problem in how coding assistants get trained from deployment feedback. The patent's core insight, that implicit rejections should be treated as probabilistically uncertain rather than definitive, is a sensible and practical improvement over naive binary labeling. If Salesforce is building or improving a code completion product, this framework would be a quiet but meaningful upgrade to how it learns from users.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.