Salesforce Patents an AI That Remixes People and Objects From Your Photos
Salesforce has filed a patent for an AI image generation system that takes a photo and a text description, extracts a specific subject from it, then redraws that subject in an entirely new context — no fine-tuning required.
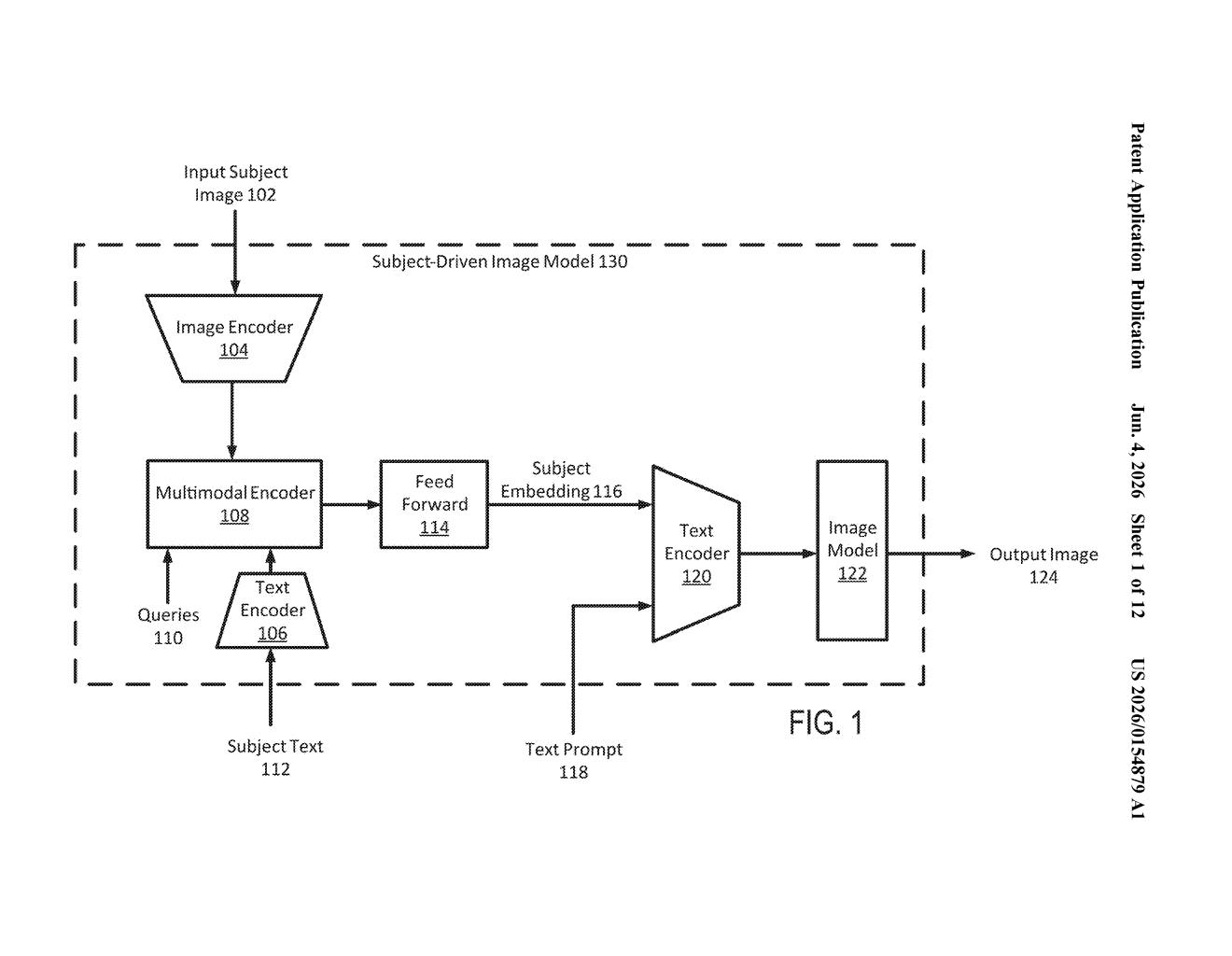
What Salesforce's subject-driven image tool actually does
Imagine you have a photo of a specific coffee mug — maybe a branded one, or a product you're selling. You want to show that same mug sitting on a beach, or in a cozy winter kitchen, without hiring a photographer. Today, most AI image tools would make up a generic mug instead of faithfully reproducing yours.
Salesforce's patent describes a system that solves exactly that problem. You upload your photo, describe the subject in plain text, then write a prompt for the new scene you want. The system figures out the specific identity of that subject — not just "a mug" but your mug — and generates a new image with it placed into the context you described.
The key idea is combining what the AI sees in your photo with what you tell it about the subject. That combination lets the output image stay faithful to the original subject while still responding creatively to your new prompt. Think of it like giving the AI both a photo ID and a set of instructions at the same time.
How the multimodal encoder locks onto your subject
The system works in a pipeline with three distinct encoding stages before any image is generated.
First, an image encoder processes your uploaded photo into an image feature vector — a compact numerical representation of everything the model can see. Separately, a text encoder converts your written description of the subject ("a red ceramic mug with a chipped handle") into a text feature vector.
Those two vectors are then fed into a multimodal encoder — a model that fuses visual and language information together. This produces a single vector representation of the subject that captures both its visual appearance and its described identity. This is the critical step: instead of relying on either the image or the text alone, the system uses both to pin down exactly what the subject is.
Finally, that subject vector is combined with your new text prompt ("the mug sitting on a snowy windowsill at dusk") and passed into a diffusion model — the same class of AI behind tools like Stable Diffusion, which builds images gradually through an iterative denoising process. The subject vector acts as a conditional input, steering the diffusion process to keep your subject recognizable throughout generation.
What this means for Salesforce's AI creative tools
For Salesforce, this kind of technology slots neatly into its commerce and marketing cloud products — the exact tools brands use to generate product imagery at scale. If this makes it into a product, marketing teams could generate dozens of contextual product shots from a single reference photo without a photo studio, just by typing new scene descriptions.
More broadly, subject-driven generation is one of the harder problems in AI imaging — keeping a specific identity consistent while changing everything around it. Most current consumer tools handle it poorly. Salesforce filing in this space signals it sees AI-powered visual content as a genuine competitive battleground for its enterprise customers, not just a demo feature.
This is a well-scoped, practically useful patent in a genuinely hard problem area of AI image generation. The multimodal fusion approach — combining a visual encoder and a text encoder before touching the diffusion model — is a reasonable architectural bet. Whether it produces better subject fidelity than approaches like DreamBooth or IP-Adapter in practice is the real question, and patents don't answer that. Still, this is clearly aimed at Salesforce's bread-and-butter enterprise marketing customers, and that specificity makes it more credible than a generic AI imaging claim.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.