Salesforce Patents an LLM System That Tests and Trains Its Own AI Agents
Building AI agents is one challenge — figuring out whether they work correctly is a whole other problem. Salesforce is patenting a system where an LLM handles both sides: generating the test cases and producing the training data, then validating the results.
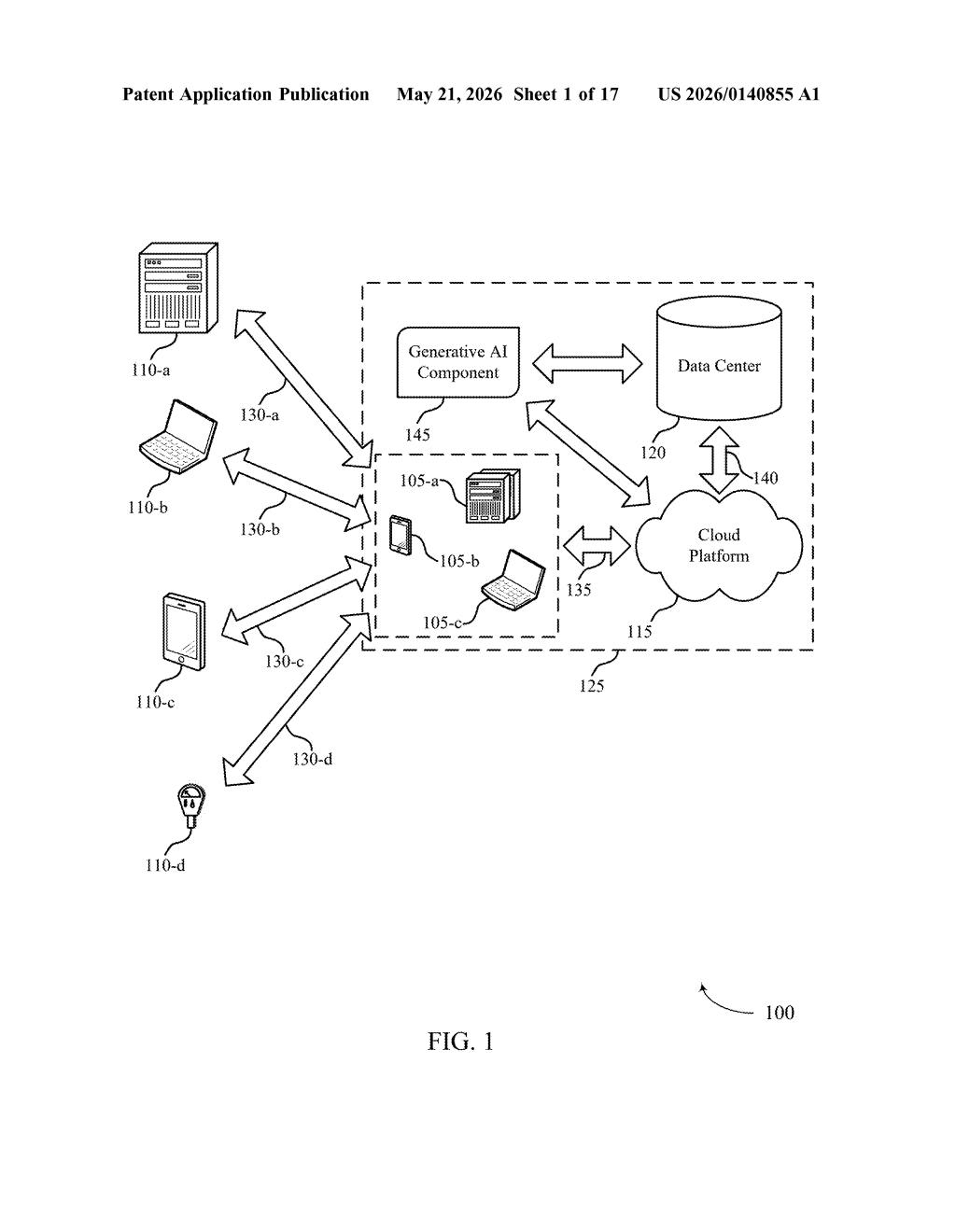
How Salesforce's self-testing AI agents actually work
Imagine you've just hired a team of AI assistants to handle customer service tasks — things like processing refunds, answering product questions, or updating account records. Before you let them loose, you need to test them. But writing hundreds of realistic test scenarios by hand takes forever.
Salesforce's patent describes a system that short-circuits that process. You pick which AI agents you want to test, describe what they're supposed to do, and an LLM automatically generates a whole library of test scenarios — then uses those scenarios to create the actual training data those agents learn from. It's the AI writing its own homework and its own pop quiz.
The system also handles evaluation: feeding data tables through an LLM to check quality, and running prompt templates (the instruction scripts that tell agents how to behave) through a grader that scores how well they performed. The goal is to get AI agents production-ready faster, with less manual work from your engineering team.
How the LLM generates scenarios, then trains from them
The patent describes a pipeline with three main phases: scenario generation, training data generation, and evaluation.
First, a user selects one or more agents from a pool — each agent is tied to a set of parameters defining what actions it can take via underlying AI/ML models. The system feeds those parameters into an LLM, which generates a plurality of scenarios (think: edge cases, common requests, failure modes) relevant to the task the agent needs to perform.
Second, the LLM uses those generated scenarios as raw material to produce a set of training data. Rather than engineers manually curating examples, the LLM synthesizes them from the scenario descriptions and agent parameters — then that data is used to train the underlying AI/ML models.
The patent also covers two evaluation sub-systems:
- Data table evaluation: the system receives instructions, runs a dataset through the LLM, and scores the output — useful for checking whether structured data meets quality thresholds.
- Prompt template evaluation: a prompt template (the scripted instruction set for an agent) is executed via the LLM, and the LLM itself grades how well the template performed.
The result is a largely closed-loop system where an LLM acts as both the content generator and the quality judge — reducing the human-in-the-loop burden for teams deploying agents at scale.
What this means for enterprise AI agent deployment
For enterprise software teams, testing AI agents is one of the biggest friction points in deployment. Writing realistic test cases manually doesn't scale — especially when agents handle open-ended natural language tasks across thousands of possible inputs. A system that auto-generates both test scenarios and training data from agent parameters could dramatically cut the time between building an agent and shipping it.
This fits squarely into Salesforce's Agentforce product line, which lets businesses deploy AI agents inside their CRM workflows. If Salesforce can bake this testing and evaluation loop directly into the platform, it lowers the bar for customers to trust — and actually deploy — those agents in production environments. That's a real competitive moat in the enterprise AI space.
This is foundational plumbing for the AI agent era, and Salesforce is smart to lock it down. The genuinely interesting part isn't the testing itself — it's using the LLM as both test-case author and grader, which creates a feedback loop that's hard to replicate without a capable foundation model sitting underneath it. For Agentforce customers, this kind of automated QA infrastructure is exactly what separates a demo from something you'd trust in a real sales pipeline.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.