Amazon Patents a System That Lets AI Remember and Reuse Previous Answers
Every time an AI chatbot answers a question it's already answered before, it's burning computing power needlessly. Amazon's new patent describes a way to make large language models remember — and reuse — answers they've already generated.
How Amazon's AI answer cache saves time and money
Imagine asking a customer service chatbot, "What's your return policy?" Thousands of people ask the same question every day. Right now, many AI systems think through that question fresh each time — which takes real computing time and money. Amazon's patent describes a smarter approach: store the answer the first time, and hand it back instantly to anyone who asks something equivalent.
The system works by turning your question and its surrounding context into a kind of fingerprint. If that fingerprint matches something already in the cache (think of it like a lookup table of previous answers), the stored response goes straight back to you — no AI processing required.
There's also a fallback plan for when the AI does have to think. If it can't finish within a set time limit, Amazon's system gives it a little extra time, then saves whatever answer it produces — complete or partial — so the next person asking the same thing gets a faster reply.
How the signal hashing model generates and matches cache keys
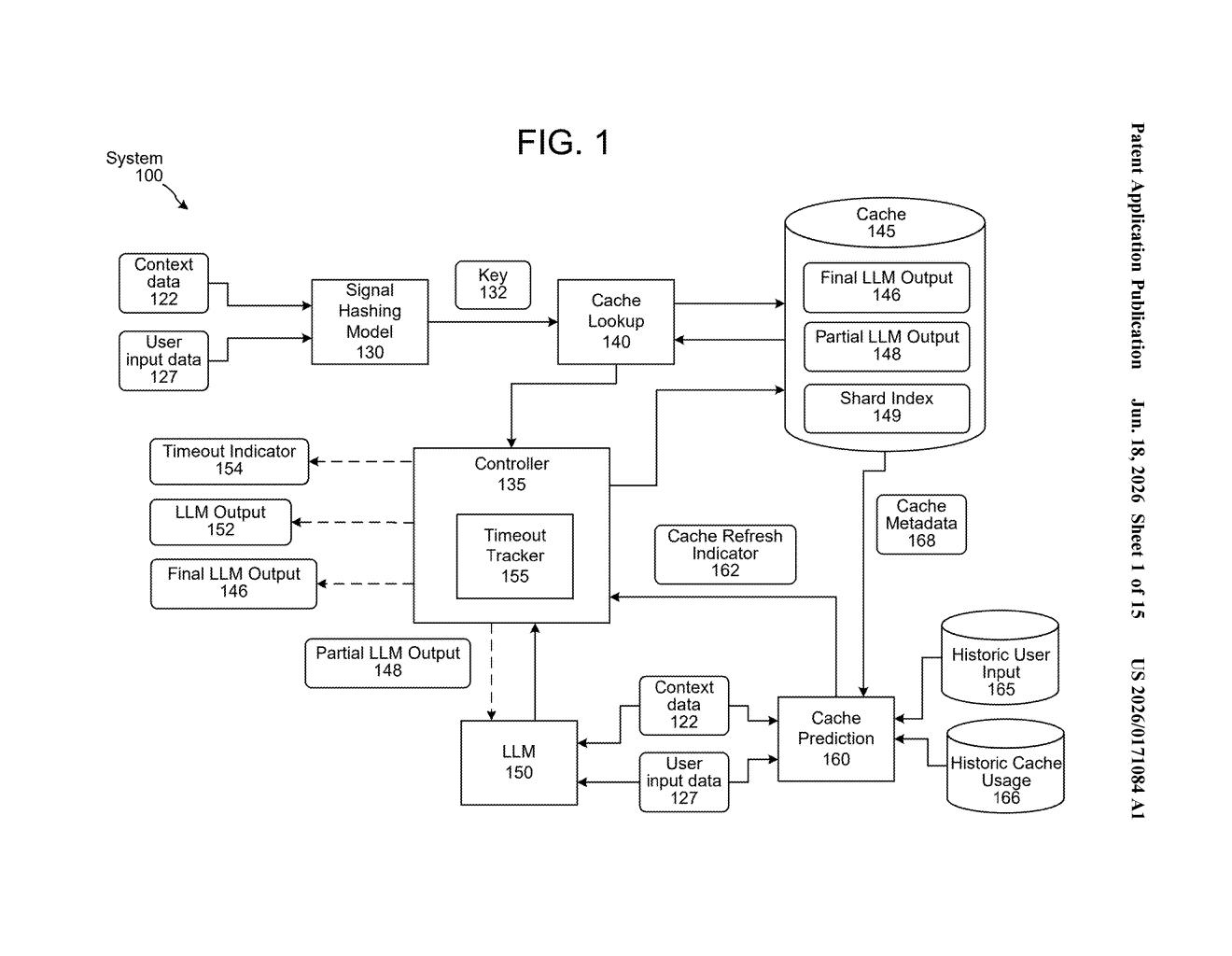
The patent describes a multi-layer system for reducing redundant work in large language model (LLM) inference — the compute-heavy process of generating a response.
At the core is a "signal hashing model" — a small machine learning model that converts a user's input and its surrounding context (prior conversation turns, system prompts, etc.) into a compact key, essentially a unique fingerprint for that conversational situation. That key is used to look up stored responses in a cache.
The flow works like this:
- A user sends a message. The system generates a key for that message and its context.
- If the key is found in the cache (cache hit), the stored output is returned immediately — no LLM needed.
- If the key is not found (cache miss), the LLM processes the request normally within a first timeout window.
- If the LLM can't finish in time, a second, longer timeout kicks in. Whatever the LLM produces — full or partial — is then stored in the cache for future use.
The timeout-and-store mechanism is notable because it turns slow responses into future fast ones. Even an incomplete answer gets cached, so the system gradually improves its hit rate over time without any manual curation.
What this means for the cost of running AI at Amazon's scale
Running large language models at scale is expensive — each inference call consumes GPU time and energy. For a company like Amazon, which operates AI services through AWS and powers Alexa and other products, even a modest reduction in redundant inference calls translates into significant cost savings. A caching layer that intercepts frequently repeated queries before they reach the model is one of the more direct ways to cut that bill.
For end users, the practical effect is faster responses on common questions. If your query fingerprint matches something already in the cache, you get an answer in milliseconds rather than the seconds it takes a model to generate one fresh. This matters most in high-volume, repetitive-query environments like customer support bots, document Q&A systems, and enterprise assistants built on AWS Bedrock.
This is unglamorous infrastructure work, but it's the kind of patent that actually ships and actually saves money. Caching AI responses isn't a new idea in principle, but the specific combination of a learned hashing model, two-tier timeouts, and automatic storage of partial outputs is a real engineering contribution. Amazon's AI services business is competitive enough that these efficiency wins matter.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.