Microsoft Patents a Weight-Rotating Trick to Keep GPUs Busy During AI Training
Training large AI models on very long sequences of text is brutally expensive — partly because GPUs end up waiting around with nothing to do. Microsoft's new patent tries to fix that by pipelining the heavy math with the data transfers so the two happen at the same time.
How Microsoft keeps GPUs from sitting idle during AI training
Imagine a restaurant kitchen where the chef has to stop cooking every few minutes to walk to the pantry and grab the next ingredient. All that walking is wasted time. Microsoft's patent is basically a system that sends ingredients to the chef while they're already cooking, so the stove is never idle.
In AI training, models learn by doing enormous amounts of matrix multiplication — essentially multiplying huge grids of numbers together, over and over. When models deal with very long inputs (think: a 100,000-word document), those grids become massive and have to be split across dozens or hundreds of GPUs. The problem is that each GPU has to wait while data is shuffled around the network before it can do its next calculation.
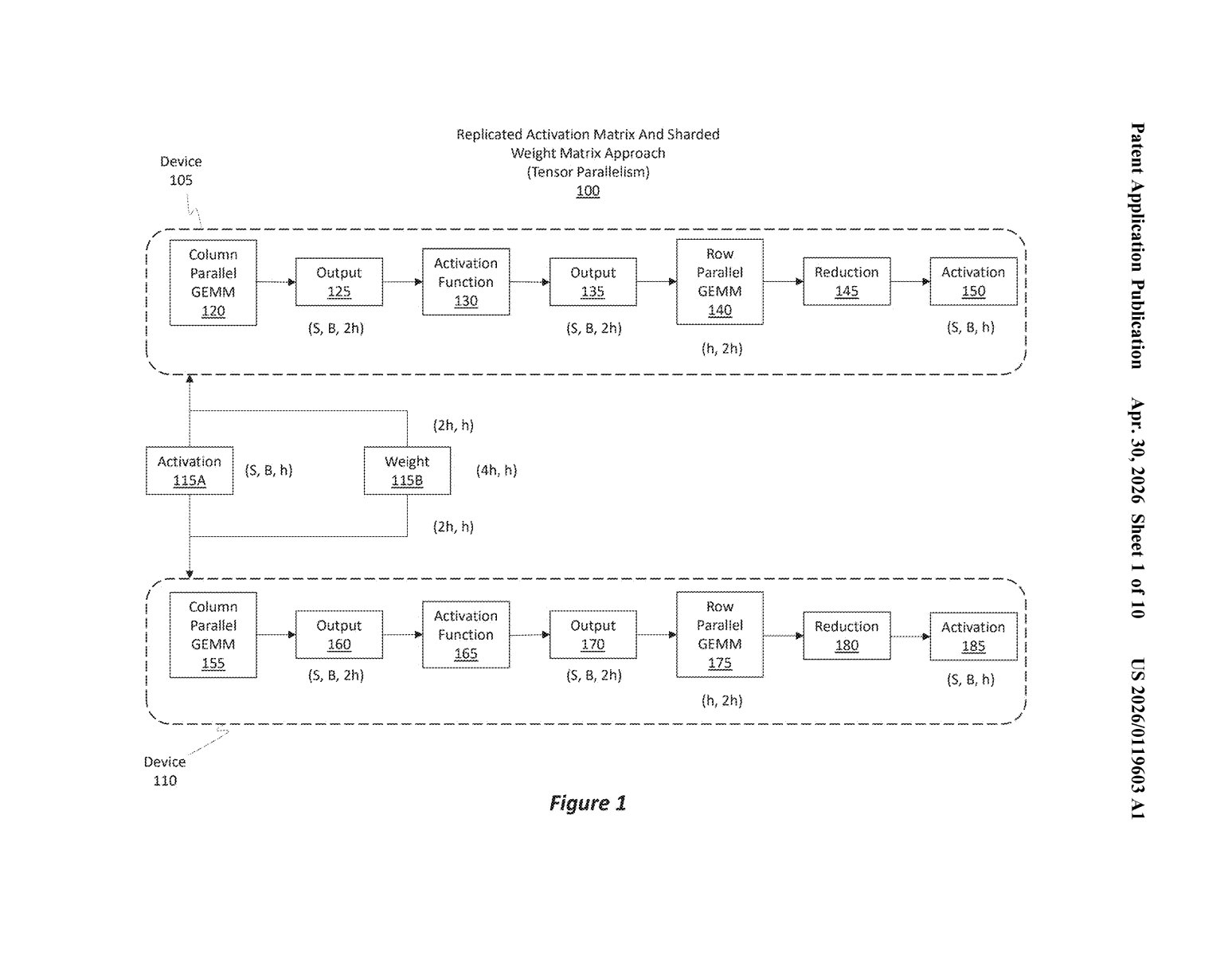
Microsoft's approach keeps the activation data (the input representation) stationary on each machine, and rotates the weight data (what the model has learned) around like a conveyor belt — transmitting each chunk to the next machine at the exact same moment the current chunk is being multiplied. The GPUs stay busy; the network transfers happen in the background.
How weight chunks rotate while matrix math runs in parallel
The patent describes a distributed training technique called Sharded Activation and Weight (or SAWD, based on the diagram label). It targets the matrix multiplication steps inside a transformer model — the architecture behind essentially every modern large language model.
Here's the core mechanical idea:
- Activation matrix chunks (the intermediate representations of your input data) are split along one dimension and pinned to individual machines. They don't move.
- Weight matrix chunks (the learned parameters) are also split and distributed, but these do move — they rotate from machine to machine in a ring pattern.
- Each machine performs a GEMM (General Matrix Multiply — the core numerical operation in neural net training) using its local activation chunk and whichever weight chunk it currently holds.
- Concurrently with that multiplication, the machine ships the weight chunk it just used to its neighbor and receives the next weight chunk from the other neighbor.
- Results are accumulated into an output tensor across multiple rounds until the full matrix product is assembled.
The key insight is overlapping compute with communication. Normally, a GPU finishes its math, then waits while data moves over the network. Here, those two steps happen in parallel, hiding the network latency behind useful work. This is especially valuable for long-context transformers, where the matrices are enormous and the communication overhead is proportionally higher.
What this means for training massive-context AI models cheaply
Long-context AI — models that can process tens or hundreds of thousands of tokens at once — is one of the most computationally demanding frontiers in AI right now. The bottleneck isn't just raw compute; it's how efficiently you can move data between GPUs without wasting their cycles. Any technique that meaningfully reduces idle time translates directly into either faster training or lower cost for the same workload.
For Microsoft, which operates one of the largest AI infrastructure footprints in the world (powering Azure AI and its OpenAI partnership), even modest efficiency gains at this scale compound into significant savings. If you're training or running inference on a model that handles long documents — legal contracts, codebases, scientific papers — this kind of parallelism optimization is the unsexy engineering work that actually makes it economically viable.
This is a solid, specific systems engineering patent — not a flashy AI capability claim, but the kind of low-level infrastructure work that separates efficient AI clusters from wasteful ones. The overlap-compute-with-communication idea isn't new in principle (it's a well-known HPC technique), but Microsoft's specific sharding scheme for transformer activations and weights is a concrete implementation worth watching, especially as long-context models become standard.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.