Nvidia Patents a System for Grading Its Own AI Output Annotators
If you're training an AI model, the quality of its training data is only as good as the people — or AI tools — labeling it. Nvidia is patenting a system that watches the watchers, automatically grading the annotators who grade AI outputs.
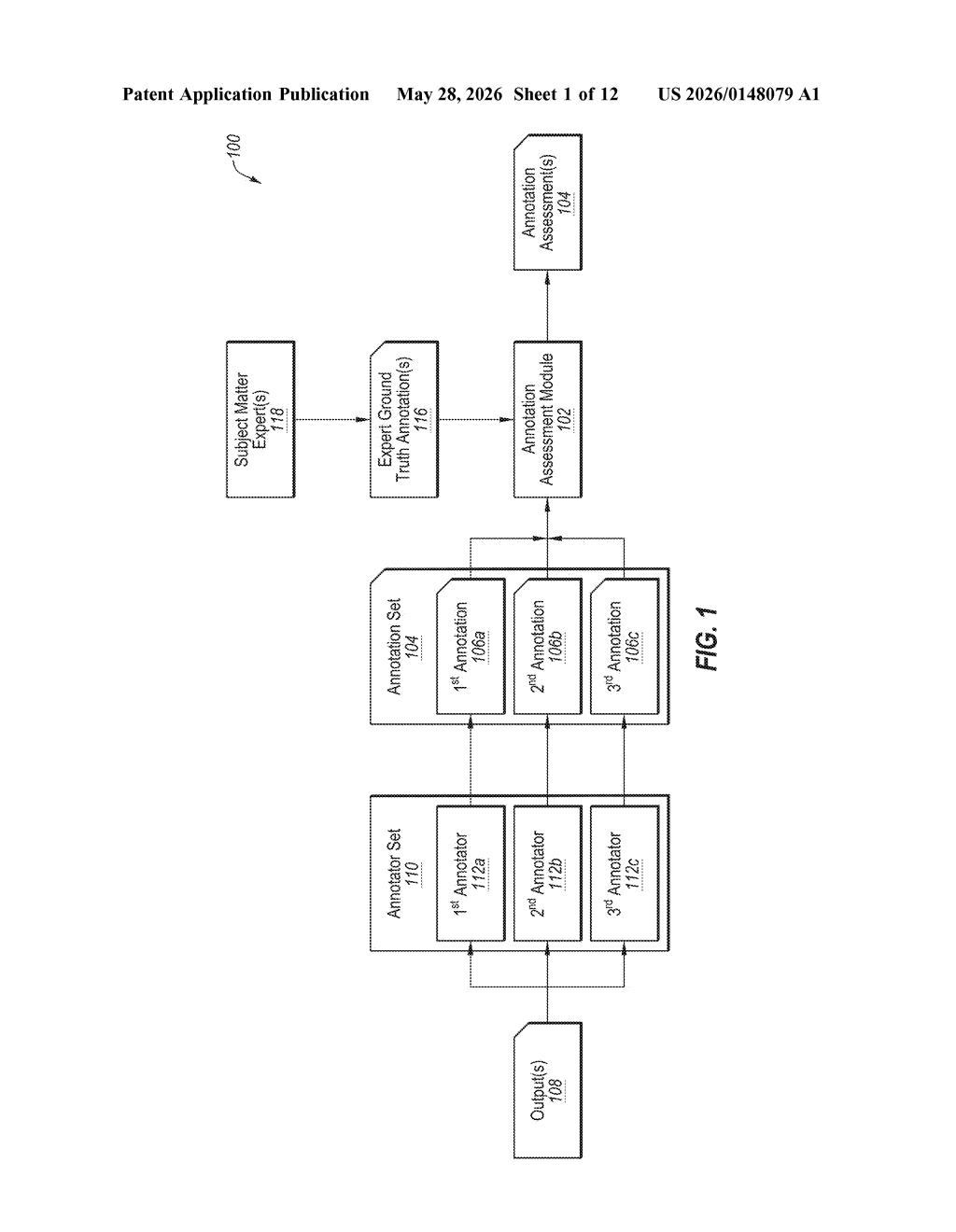
What Nvidia's annotator-grading system actually does
Imagine you're hiring a team of graders to score a standardized test. Some graders are consistent and accurate; others drift, get sloppy, or just disagree with everyone else. You'd want a way to figure out which is which — and correct for it before the scores go on anyone's permanent record.
That's exactly the problem Nvidia is tackling here, but for AI training data. When a machine learning model produces an output — say, a generated paragraph or a classification decision — human and AI annotators label whether that output is good or bad. Those labels become the training signal for improving the model. If the labels are noisy or biased, the model learns the wrong lessons.
Nvidia's patent describes a system that compares each annotator's labels against two benchmarks: a consensus ground truth (what the crowd of annotators agreed on) and an expert ground truth (what a domain specialist said). By measuring the gap, the system can score annotators and even automatically retrain or adjust AI-based annotators that are performing poorly.
How the assessment module scores each annotator
The system has three moving parts worth understanding.
First, it collects a batch of assessment annotations — individual human or AI labels applied to a machine learning model's output. Each annotation is tied to a specific annotator, so the system knows who said what.
Second, it constructs two kinds of ground truth:
- First ground truth — aggregated from the crowd of annotators (think majority vote or a weighted average).
- Second ground truth — provided by a subject matter expert (SME), someone with domain authority whose judgment is treated as the gold standard.
Third, the system computes an assessment score for each annotator by comparing their labels against one or both of those ground truths. The interesting wrinkle: if an annotator is itself an AI model (an LLM used as an auto-labeler, for instance), the system can modify that AI annotator based on its poor score — essentially retraining or re-prompting it in response to the assessment.
This creates a feedback loop: AI outputs get labeled, labels get graded, bad labelers get corrected, and the whole pipeline tightens over time. The patent covers the architecture for doing all of this at scale, including what Nvidia calls "annotator adjustment operations" — the concrete corrective actions triggered by a bad assessment.
Why annotation quality is the hidden lever in AI training
The bottleneck in modern AI development isn't usually the model architecture — it's data quality. Reinforcement learning from human feedback (RLHF) and similar techniques depend entirely on reliable preference labels. If those labels are inconsistent, the model has no stable signal to learn from. A system that audits annotators in real time — and auto-corrects AI-based labelers — could meaningfully compress the iteration cycle for model improvement.
For Nvidia, which is building out its NeMo and AI enterprise platforms, this is infrastructure work. It's not a consumer feature; it's a quality-control layer that sits inside the model development pipeline. If it works well, customers using Nvidia's tools to fine-tune models would get cleaner training loops without needing to manually audit every annotation batch.
This is unglamorous but genuinely important plumbing. The AI industry talks endlessly about model architectures and compute, but annotation quality is often the silent variable that determines whether a fine-tuned model is actually useful. Nvidia filing a patent on automated annotator evaluation signals they're serious about owning the full model-development stack, not just the GPU side.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.