Nvidia Patents a Self-Routing AI Inference System That Skips the Traffic Cop
Every time an AI model needs to answer a question, there's usually a central coordinator bouncing the request back and forth between servers. Nvidia's latest patent describes a way to bake the entire routing plan into the request itself — so the data can travel its own path without checking back in.
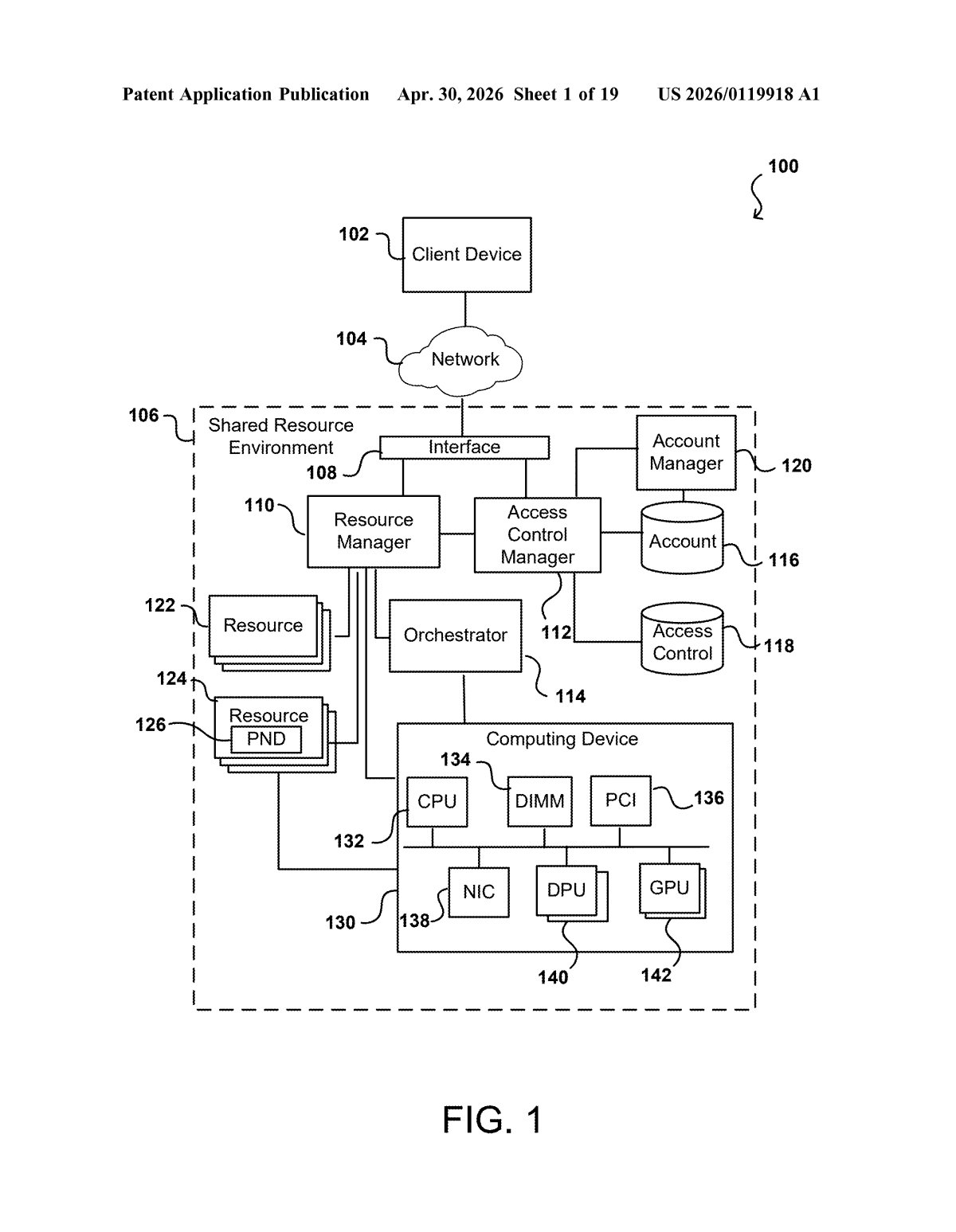
How Nvidia's inference pipeline routes itself
Imagine you're sending a package that has to stop at three warehouses before reaching its destination. Normally, a dispatcher at headquarters tells each warehouse where to send it next. That means a lot of back-and-forth calls to the dispatcher, slowing everything down.
Nvidia's patent describes a smarter approach: the dispatcher plans the entire route upfront and prints it directly on the package. Each warehouse reads the label, does its job, and ships it to the next stop — no phone call needed. In AI terms, that package is your inference request (say, a question to a chatbot), and the warehouses are specialized servers that fetch context or run the model.
The result is that AI requests move through a chain of nodes faster, because they don't have to ping a central orchestrator at every hop. The orchestrator still plans the route at the start and reads the final answer at the end — it just stays out of the middle.
How the metadata-embedded routing sequence works
When an AI system handles a request — like a retrieval-augmented generation (RAG) query, where a model needs to look up documents before answering — the work is usually split across multiple specialized servers. There are context nodes (servers that fetch relevant data) and inference nodes (servers that run the actual AI model). Traditionally, a central orchestrator (a coordinator process) forwards the request to each node and waits for it to report back before sending it to the next one. That round-tripping adds latency.
Nvidia's patent changes that by having the orchestrator do all the planning upfront. It determines the full ordered sequence of nodes needed, then appends metadata to the request itself — essentially a routing manifest embedded in the packet — before sending it on its way.
The key ingredient is what the patent calls a network programmable device (think: a SmartNIC or data processing unit, like Nvidia's own BlueField DPU, that can make forwarding decisions in hardware). Each node reads the manifest, completes its task, and forwards the request to the next node in the list — all without calling home to the orchestrator.
- Orchestrator plans the route once and encodes it as metadata
- Request hops autonomously from context node to inference node
- Orchestrator only re-engages to package and return the final result
The orchestrator also classifies the type of inferencing needed upfront, which determines which nodes get included in the sequence.
What self-routing inference means for AI infrastructure
For large-scale AI inference deployments — think cloud APIs serving millions of requests — every millisecond of orchestrator round-trip latency compounds fast. By moving routing logic into the network layer (via SmartNICs or DPUs), Nvidia is essentially arguing that the network itself should be a first-class participant in AI infrastructure, not just a dumb pipe. That plays directly into Nvidia's strategy of selling full-stack AI infrastructure, where its GPUs, DPUs, and networking chips all work together.
For you as a developer or enterprise buyer, this kind of architecture could mean lower tail latency on AI API calls and better throughput at scale — particularly for multi-step pipelines like RAG systems, where fetching context before inference is already a two-hop problem. It also hints at how Nvidia is thinking about the software stack that runs on top of its hardware.
This is a solid, focused infrastructure patent that solves a real problem in multi-node AI inference pipelines. It's not glamorous, but the idea of embedding routing intent into request metadata — rather than relying on a chatty central coordinator — is exactly the kind of systems-level thinking that separates fast production AI from slow production AI. The fact that it leans on programmable network devices is also a clear signal that Nvidia sees its DPU/SmartNIC product line as deeply integrated with AI serving, not just networking.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.