Nvidia Patents a Smarter Batching Method for Graph Neural Network Training
Training graph neural networks is notoriously wasteful — most batching methods ignore the graph's own structure, so each training step spends half its time chasing connections that aren't even in the batch. Nvidia's new patent tries to fix that from the ground up.
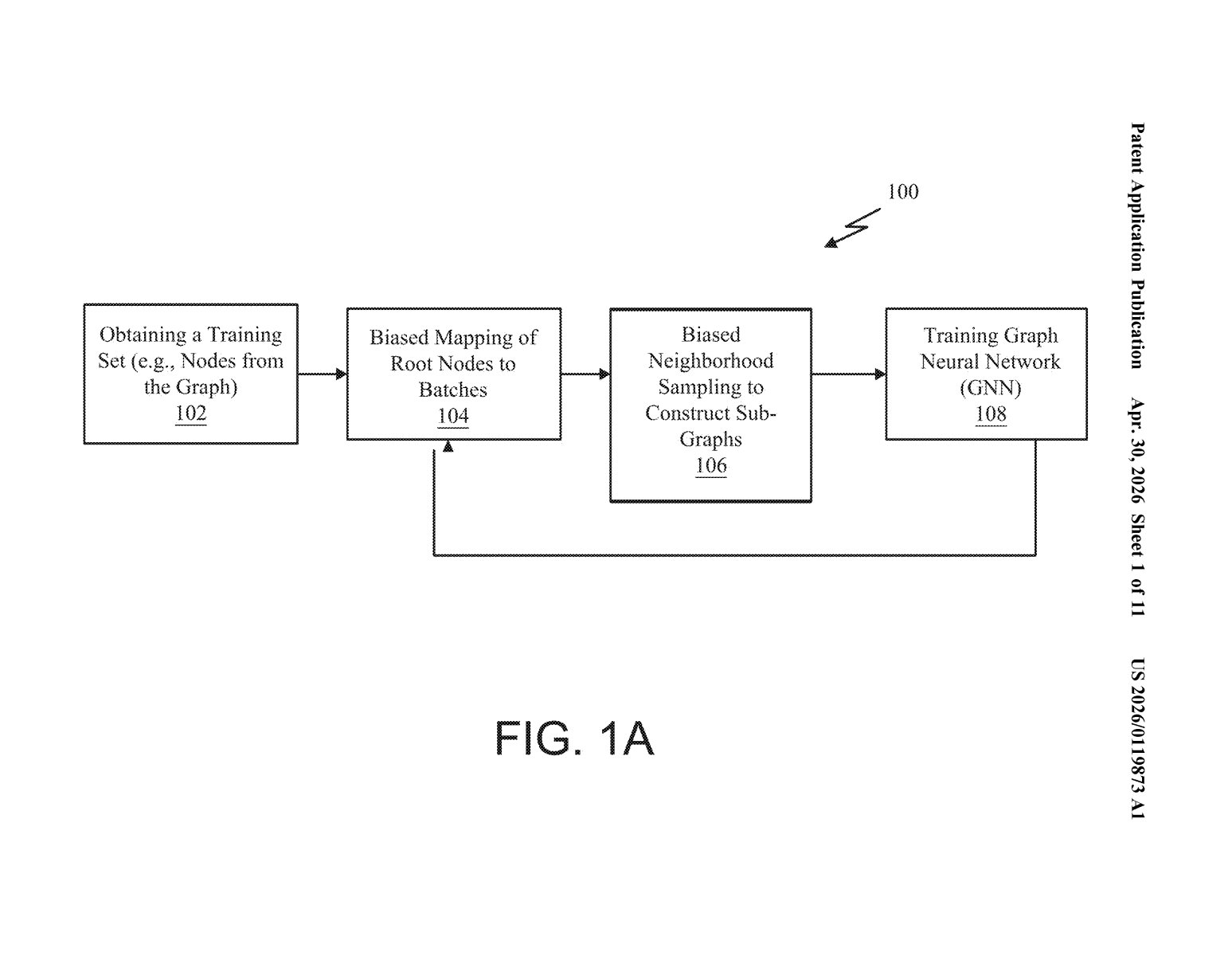
How Nvidia's community-aware GNN batching actually works
Imagine you're studying a massive social network — millions of people, each connected to dozens of others. If you want to train an AI on that graph, you can't feed the whole thing in at once, so you break it into small chunks called mini-batches. The problem is that most methods chop the graph up randomly, so each chunk is full of people whose friends are scattered across other chunks. The AI wastes a huge amount of effort trying to learn relationships it can barely see.
Nvidia's approach is more like sorting a class roster by friend group before handing out study packets. It first identifies communities — clusters of nodes that are densely connected to each other — then builds mini-batches from within those communities. It still shuffles things around to keep training from getting stale, but the shuffle happens within the community structure rather than ignoring it entirely.
The result is that each mini-batch contains nodes whose neighbors are mostly also in the batch, so the model sees more complete, meaningful context with every training step. That means less wasted compute and potentially faster, more accurate training on large graphs.
How the shuffle-and-bias system builds better mini-batches
The patent describes a pipeline with four main steps:
- Community detection: The graph's nodes are grouped into communities — think clusters where most of the edges (connections) are internal rather than crossing to other clusters. This reflects the real structure of the data rather than ignoring it.
- Structure-aware shuffling: The system then shuffles both the order of communities and the order of nodes within each community. This randomization preserves the statistical properties training needs (no order bias) while keeping structurally related nodes near each other in the batch queue.
- Mini-batch construction: Consecutive nodes from the shuffled list are grouped into mini-batches. Because related nodes were grouped first, each batch is naturally denser with intra-community connections.
- Biased neighborhood sampling: When building the subgraph (the local neighborhood of context) for each mini-batch, a sampling bias steers the sampler to prefer intra-community edges over inter-community ones. This is the key technical lever — it means the model sees denser, more informative local structure per batch rather than sparse cross-graph noise.
The bias parameter is tunable, so engineers can dial between purely structure-aware sampling and purely random sampling depending on the graph type and task.
What this means for large-scale GNN training efficiency
Graph neural networks are the backbone of some of the most computationally intense workloads in modern AI — recommendation systems (think how Netflix or Amazon figures out what to suggest), fraud detection, drug discovery, and chip design. At scale, inefficient batching isn't just slow; it's expensive in terms of both GPU time and energy. If Nvidia's method meaningfully reduces the number of training steps needed to reach the same accuracy, the savings compound fast across large clusters.
This also fits squarely into Nvidia's broader strategy of owning not just the GPU hardware but the entire software stack around AI training — from CUDA kernels up through libraries like cuGraph. A patented batching method baked into that stack would give their platform a built-in efficiency advantage for GNN workloads that competitors running commodity frameworks might not easily replicate.
This is a solid, focused infrastructure patent — not flashy, but the kind of thing that quietly saves millions of dollars in compute costs at Nvidia's customer scale. The core insight (respect the graph's own structure when you batch it) is intuitive once you hear it, which usually means it's genuinely useful. Worth watching if you follow GNN tooling or Nvidia's cuGraph ecosystem.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.