Adobe Patents an Embedding-Driven Retrieval System for Generative AI Content
Adobe has patented a retrieval-augmented generation (RAG) pipeline that converts a user's query into a mathematical embedding, hunts for similar data embeddings in a high-dimensional space, and then feeds that matched data into a generative AI model to produce contextual content.
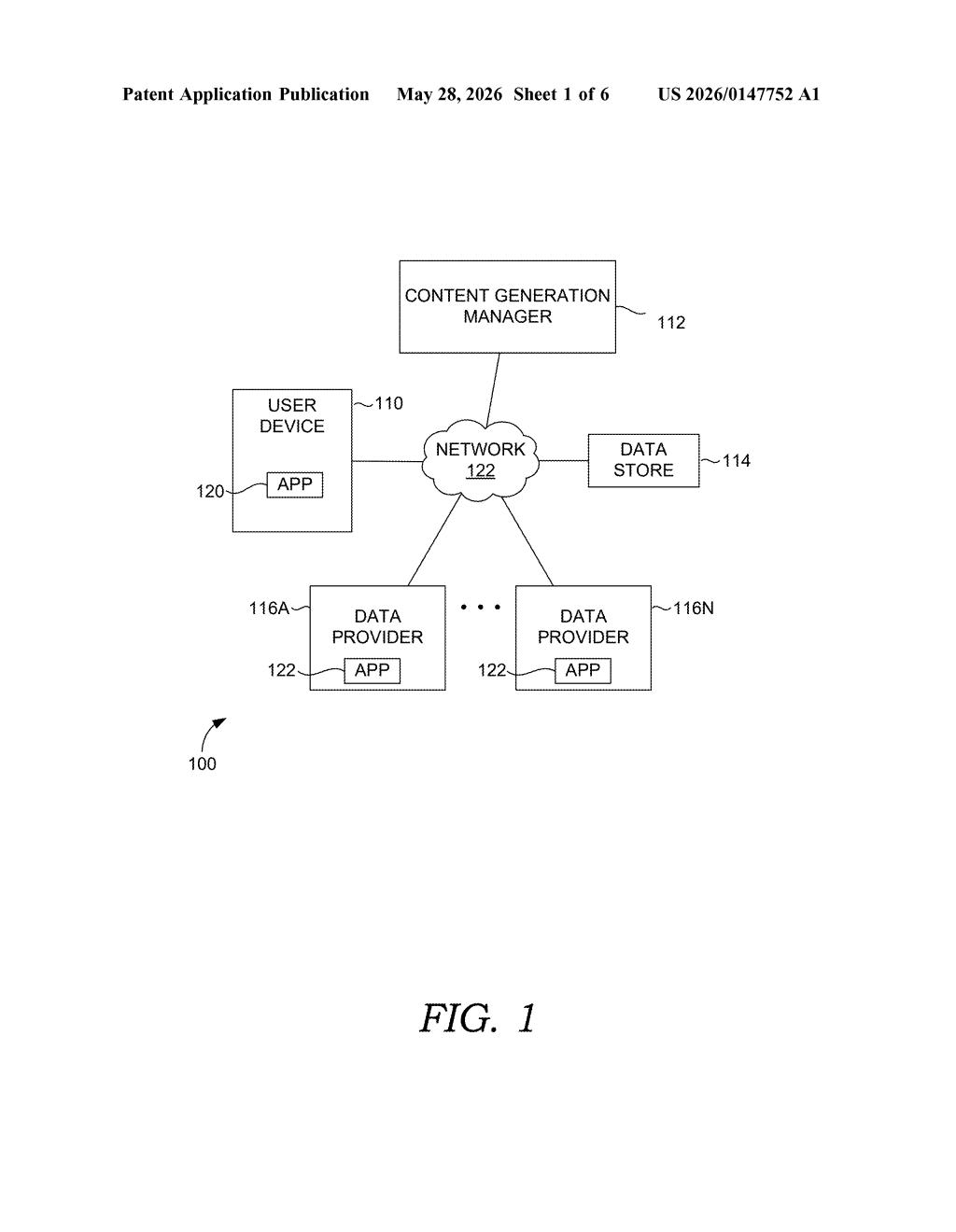
What Adobe's embedding-based AI lookup actually does
Imagine you type a question into an AI tool — say, 'show me campaign assets that performed well with millennial audiences.' Instead of doing a keyword search, the system translates your question into a kind of mathematical fingerprint, then scans a library of data that's also been turned into fingerprints. The ones that look most similar get pulled forward.
That matched data is then handed to a generative AI model alongside your original question. The model uses both to write a response, build a visualization, or surface content — whatever the tool is designed to do. The result shows up in a graphical interface.
This is essentially retrieval-augmented generation (RAG) — a well-established pattern for making AI answers more accurate and grounded in real data rather than just what the model memorized during training. Adobe is describing their own implementation of it.
How query embeddings map to relevant data in hyperspace
The patent describes a classic retrieval-augmented generation (RAG) architecture with a few moving parts:
- Query embedding generation: When a user submits a query, the system encodes it into a vector — a list of numbers representing the semantic meaning of the query in a high-dimensional mathematical space (called a "hyperspace" in the patent).
- Similarity search: The system then compares that query vector against a collection of pre-computed data embeddings — other pieces of data that have been encoded the same way. Items whose vectors sit geometrically close to the query vector are considered semantically similar.
- Relevant data retrieval: The closest-matching data is flagged as relevant to the query and retrieved.
- Generative AI content production: The retrieved data, combined with the original query, is passed into one or more generative AI models to produce output content. That content is then displayed in a GUI.
The hyperspace similarity step is what makes this more powerful than keyword matching — two things can be conceptually related even if they share no words in common, because their embeddings will still cluster near each other in vector space.
What this means for Adobe's generative AI tools
For Adobe's product suite — which includes tools like Firefly, Sensei, and Creative Cloud — this kind of retrieval layer is what separates a generic AI model from one that actually knows about your assets, campaigns, or data. Without something like this, generative AI gives you plausible-sounding output that has no connection to what's actually in your system. RAG fixes that by anchoring the model to real, relevant context before it generates anything.
That said, this is well-trodden technical territory. RAG has been a dominant pattern in enterprise AI since 2020, and vector similarity search is offered by dozens of vendors (Pinecone, Weaviate, pgvector, etc.). Adobe's patent is staking a claim on a specific implementation rather than the concept itself.
This is a competent but unremarkable filing. RAG is the industry's default approach for grounding generative AI in real data, and Adobe is essentially patenting their specific instantiation of it. It's worth knowing Adobe is formalizing this infrastructure — it signals that embedding-based retrieval is baked into their AI stack — but don't expect this to be a competitive moat.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.