Intel Patents a Way to Send Pre-Compiled Commands Directly to GPU Hardware
Every time your GPU runs a task, the graphics driver spends time translating instructions into hardware commands. Intel's patent describes a way to skip that translation step entirely by pre-compiling those commands once and dispatching them directly.
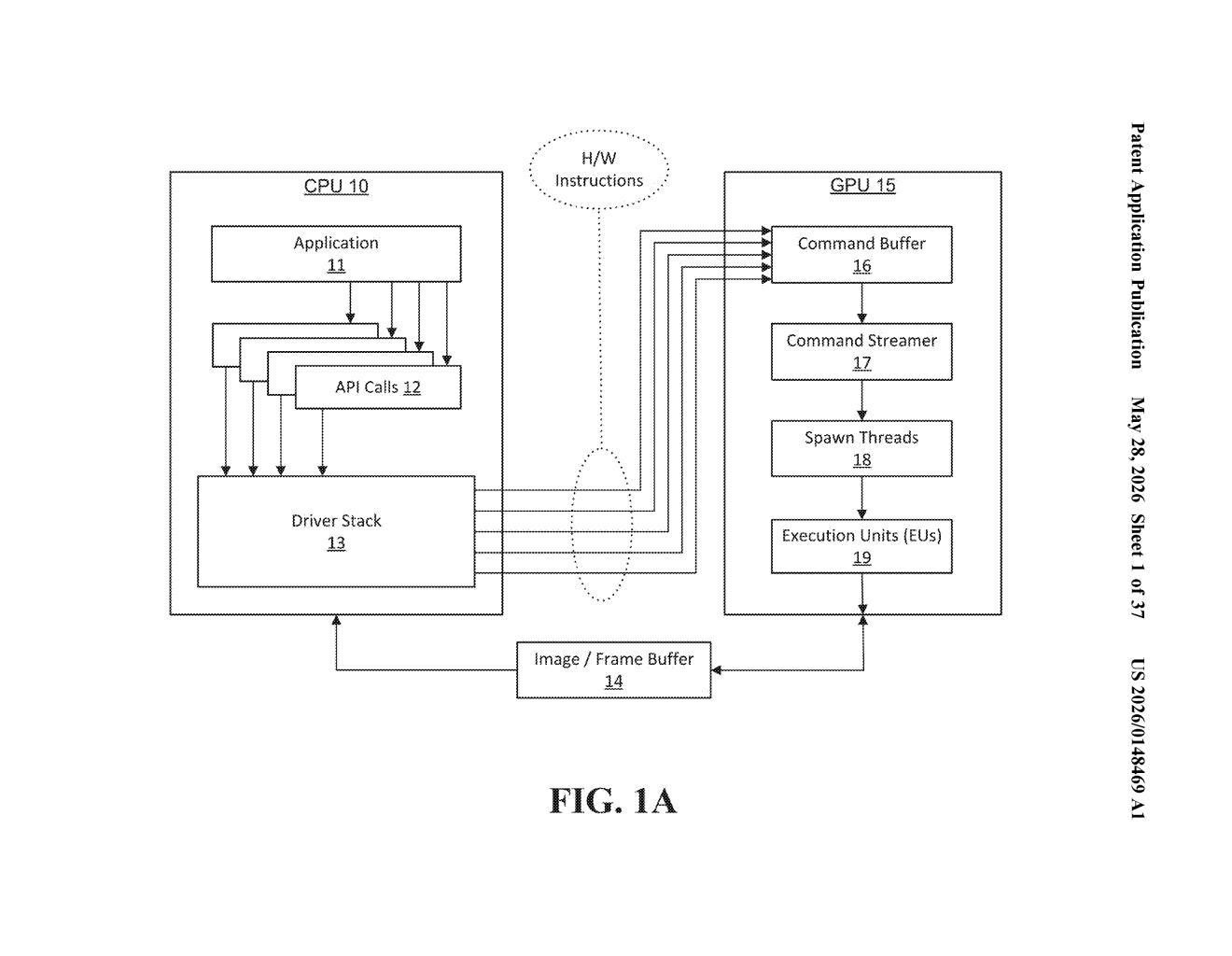
What Intel's mutable GPU command lists actually do
Imagine a chef who has to translate a recipe from English to French every single time they cook a dish — even if it's the same dish they made yesterday. That's roughly what a graphics driver does each time your GPU runs a workload: it takes instructions from an app and re-encodes them into hardware-specific commands. It works, but it's not free.
Intel's patent describes a system where you compile those GPU instructions ahead of time into a "command list" — a pre-built set of hardware-ready commands. When your application needs to run something on the GPU, it just sends that pre-compiled list directly, and the driver skips the encoding step entirely.
The trick is that these command lists are also mutable — they can include loops, conditional branches, and jump instructions. So they're not just static scripts; they can make decisions at runtime without needing to re-involve the CPU or driver in every step.
How Intel's command buffer bypasses driver encoding
The patent describes a compilation pipeline where a source file — written with function calls tied to specific GPU hardware blocks — gets compiled into a command list. That command list contains hardware-executable commands already formatted for the target GPU, meaning they don't need re-encoding later.
When an application wants to run a GPU workload, it makes an API call (a standard software interface call, like OpenCL) to the graphics driver. Normally, the driver would generate and encode GPU commands at this point. Under Intel's approach, the driver recognizes that the command list is already compiled and bypasses both steps — no command generation, no re-encoding.
The command lists also support control flow constructs directly at the GPU level:
- Executable loop commands — repeat a sequence without CPU involvement
- Executable conditional branch commands — take different paths depending on runtime state
- Executable jump commands — skip to arbitrary points in the command sequence
This is a continuation of an earlier Intel patent (No. 12,469,199, filed 2021), suggesting Intel has been building toward this approach for several years. The classification under both GPU graphics (G06T) and general processor execution (G06F) groups indicates the technique is meant to cover both graphics and compute workloads.
What this means for GPU compute and graphics workloads
The driver encoding step is a known bottleneck in GPU compute pipelines — it adds latency and CPU overhead every time a workload is dispatched. By front-loading that work into a one-time compilation phase, Intel's approach could meaningfully reduce per-dispatch costs in workloads that run the same GPU operations repeatedly, like AI inference, simulation, or rendering loops.
The mutable command list angle is the more interesting piece. Static pre-compiled command buffers already exist in some form across modern graphics APIs. Adding branching, looping, and jump logic at the GPU level means you can encode complex conditional workloads once and let the GPU handle the decision-making autonomously — without the CPU acting as traffic cop on every iteration.
This is unglamorous but genuinely useful GPU plumbing work. Reducing driver overhead in hot dispatch paths is exactly the kind of optimization that shows up in benchmark results and real-world compute throughput, even if it never gets a product announcement. The fact that this is a continuation of a 2021 filing suggests Intel has been iterating on this approach long enough to have a clear implementation strategy.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.