Google Patents an AI That Learns to Summarize by Whether Its Output Actually Helps
Most AI summarizers are trained to sound accurate — but Google's new patent trains one to be useful, judging the summary by whether it actually helps a downstream prediction task get the right answer.
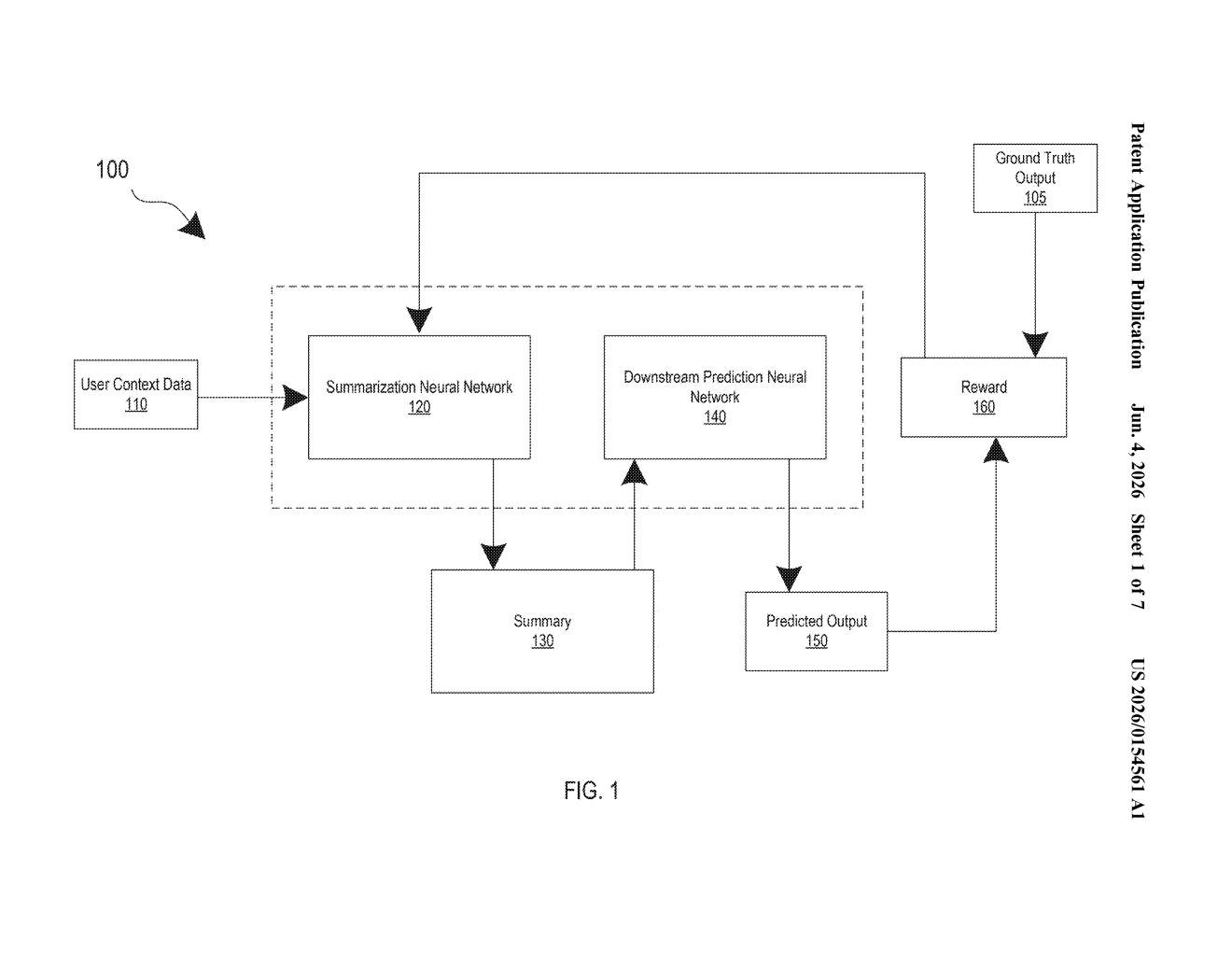
What Google's reward-driven summarizer actually does
Imagine you ask an AI to summarize a customer's purchase history, and then a separate system uses that summary to predict whether the customer will churn. The problem? The summarizer was trained to write tidy summaries — not to write summaries that are actually helpful for churn prediction. Those two goals aren't the same thing.
Google's patent tackles that gap directly. Instead of training a summarizer to match a human-written reference, it trains the model using reinforcement learning — essentially, trial and error with a scorecard. The summarizer generates a summary, a prediction system uses that summary to make a call, and then the model gets a reward based on how close that prediction was to the correct answer.
Over time, the summarizer learns to highlight the details that actually matter for the task at hand, not just the details that seem broadly important. It's like the difference between a research assistant who writes good notes and one who writes exactly what you need to win the argument.
How the RL reward loop shapes the summarizer
The patent describes a training pipeline where a summarization neural network is paired with a downstream prediction task — think of it as a two-stage system. In stage one, the summarizer compresses raw entity context data (information about a specific entity, like a user, product, or account) into a summary. In stage two, a predictor uses that summary to generate an output — say, a risk score or a category label.
The clever part is the feedback loop. The system compares the predictor's output against a ground truth label (the known correct answer) and calculates a reward signal. That reward is then fed back to train the summarizer via reinforcement learning (RL) — a technique where the model learns by maximizing cumulative rewards rather than by directly copying labeled examples.
This matters because standard supervised summarization training optimizes for surface-level text quality. RL-based training optimizes for downstream task performance, which forces the summarizer to learn what's actually signal versus noise for a given use case.
Key components in the system include:
- Entity context data — the raw input about a given entity
- Summarization neural network — the model being trained
- Downstream prediction task — the task that validates the summary's usefulness
- Reward function — derived from comparing the prediction to the ground truth
Why task-driven summarization is a bigger deal than it sounds
For Google, this kind of architecture is directly applicable to large-scale systems where AI needs to compress information before acting on it — think ad targeting, content ranking, fraud detection, or user modeling. If the summarizer is task-aware, the whole pipeline becomes more efficient: you don't need to feed raw context into every downstream model, just a lean, purpose-built summary.
For the broader AI field, this reflects a real shift: moving from "does the summary read well" to "does the summary do its job." That's a meaningful distinction as summarization gets embedded deeper into agentic and multi-step AI workflows, where each stage depends on the output quality of the last.
This is a solid, focused patent on a genuinely useful training technique. It won't generate headlines about new products, but the underlying idea — that summaries should be judged by their downstream utility, not their surface quality — is a real architectural improvement for production AI systems. Google almost certainly has internal pipelines where this approach applies immediately.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.