Google Patents an AI That Reads Importance Scores Before Writing a Summary
Most AI summarizers treat every piece of content equally — Google's new patent describes a system that lets a numeric 'prominence' score tell the model exactly how much weight to give each item before it writes a single word.
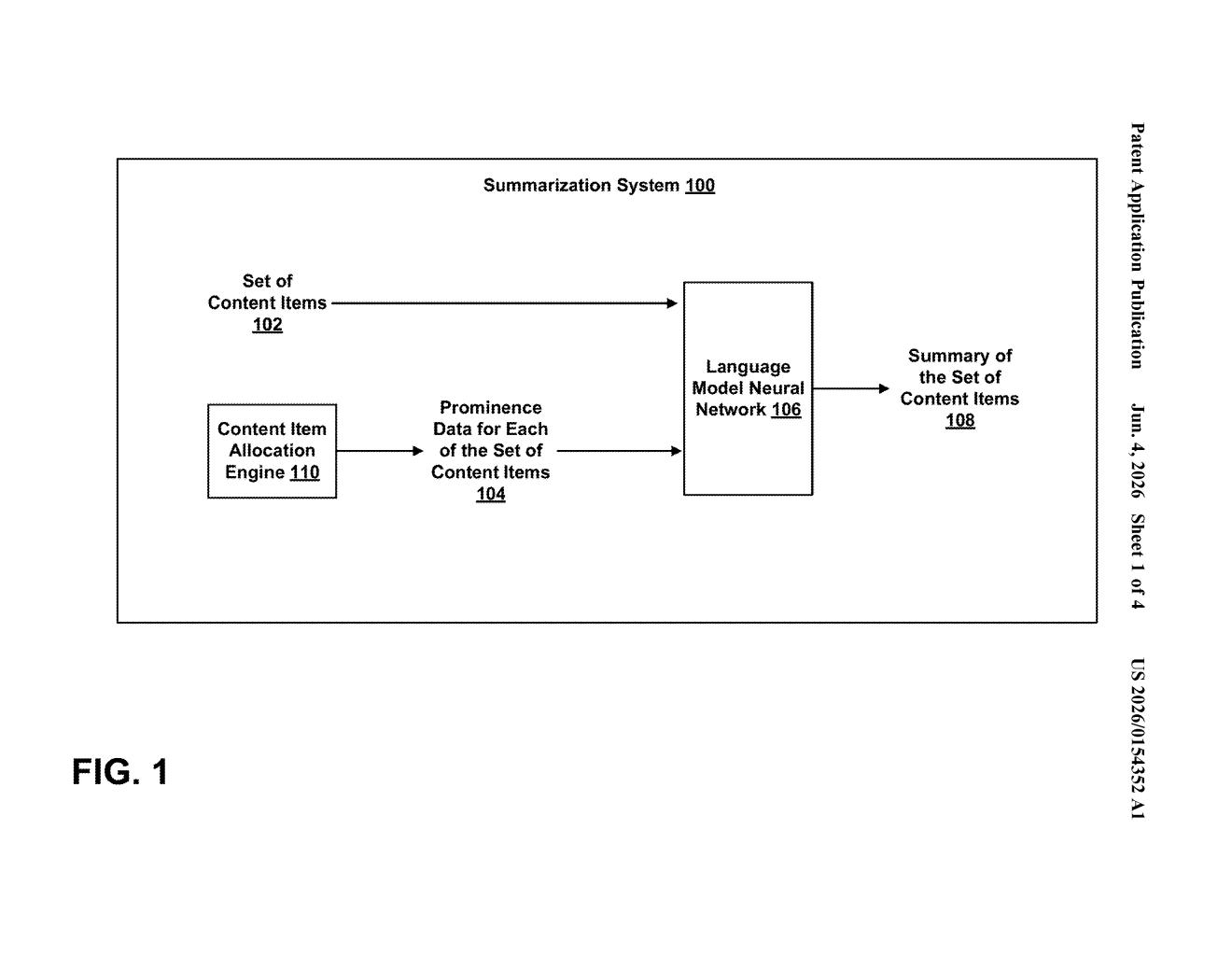
What Google's priority-weighted AI summarizer actually does
Imagine you ask an AI to summarize ten news stories, but three of them are really important and the rest are filler. A standard summarizer has no way to know that — it just blends everything together and hopes for the best.
Google's patent describes a different approach: each content item gets a prominence score attached to it before it's fed into the language model. That score tells the AI, in effect, "spend more words on this one" or "barely mention that one." The result is a summary that reflects a pre-set ranking of importance, not just whatever the model decides feels relevant.
This is especially useful when the person or system requesting the summary already knows what should matter most — say, a high-bid advertiser's product, a breaking news lead, or a user's most-read topics — and wants the AI's output to mirror that priority rather than override it.
How prominence scores steer the language model's output
The patent describes a pipeline with two key inputs fed into a language model neural network simultaneously: the content items themselves (articles, ads, product listings, etc.) and a separate prominence data vector — essentially a numerical weight assigned to each item that represents how prominently it should appear in the final summary.
By baking the prominence scores directly into the model's input (rather than post-processing the output), the system lets the LLM factor importance into how it constructs sentences and allocates space, rather than treating ranking as an afterthought.
The claim is deliberately broad about what "prominence" means — it could represent:
- Relevance scores from a retrieval system
- Advertiser bid values or campaign priorities
- Editorial importance weights
- User preference signals from past behavior
The architecture keeps the model flexible: the same LLM can produce very different summaries from the same content set just by changing the prominence inputs, without retraining. That's a meaningful efficiency win if you need personalized or context-specific summaries at scale.
What this means for Google's ad and content products
For Google, the most obvious application is in ad-adjacent summarization — think AI Overviews, Shopping summaries, or news digests where certain results need more surface area than others for commercial or editorial reasons. This patent gives Google a technical framework to defend that kind of weighted output as an intentional, controllable feature rather than an emergent model bias.
For everyday users, the implication cuts both ways. A prominence-weighted summarizer could make your Google Feed or search results genuinely more personalized to what you care about. But the same mechanism could also quietly amplify paid or promoted content inside summaries that look organic — and that's the part worth watching.
This is a quietly strategic patent. Google is essentially filing a claim on the idea of programmatic prominence control inside LLM summarization — which maps almost perfectly onto its existing ads and content ranking infrastructure. It's not a flashy AI capability, but it's the kind of plumbing that lets a search-and-ads business plug commercial intent directly into generative outputs without it looking like a hack.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.