Google Patents an AI That Rewrites Its Own False Answers Before You See Them
Google has filed a patent for a pipeline that doesn't just flag when an AI makes something up — it automatically rewrites the bad output before it ever reaches you.
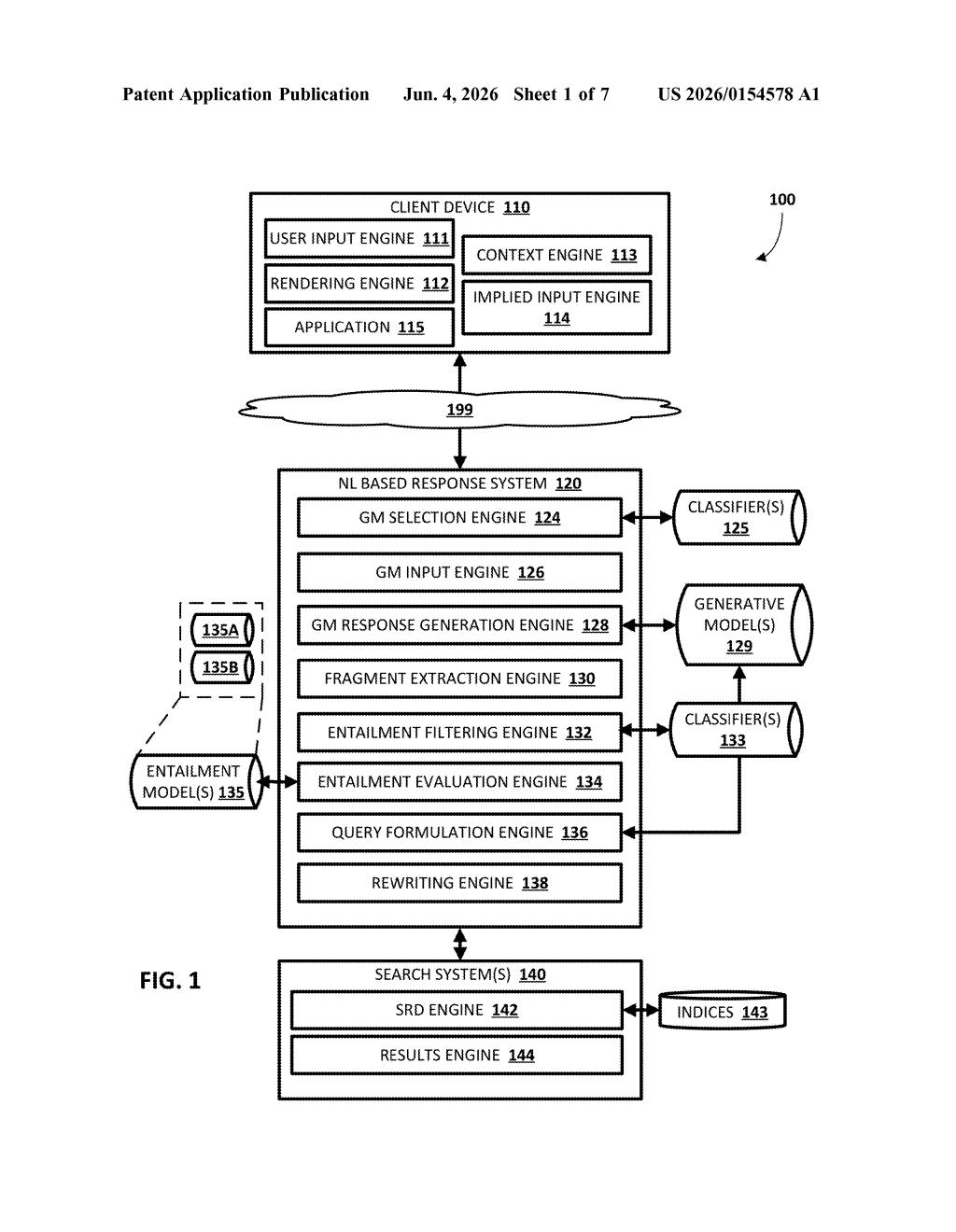
How Google's hallucination-catcher actually works
Imagine asking an AI assistant a factual question and getting a confident-sounding answer that's completely wrong. That's an AI hallucination — the model generates plausible-sounding text that isn't grounded in reality. It's one of the biggest trust problems in AI right now.
Google's patent describes a system designed to catch these errors while they're happening. After an AI generates a response to your query, the system breaks that response into individual factual claims, runs a live web search against each claim, and uses a second AI model to decide whether the search results actually back up what the first AI said — or contradict it.
If the system finds a contradiction, it doesn't just flag the problem — it marks that part of the response for automatic rewriting. The goal is to silently correct bad information before it ever shows up on your screen, making AI answers more reliable without requiring you to do any fact-checking yourself.
How the entailment models check and rewrite LLM output
The patent describes a multi-stage pipeline layered on top of a standard large language model (LLM) response. Here's how the stages break down:
- Fragment extraction: Once the LLM generates a response, the system splits it into discrete textual fragments — essentially individual factual claims or sentences.
- Suitability classification: Not every fragment is worth checking. Opinions, questions, and non-verifiable statements are filtered out. Only claims that could plausibly be fact-checked are forwarded to the next stage.
- Textual entailment analysis: For each eligible fragment, the system formulates a search query, retrieves relevant documents from the web, and then feeds both the fragment and those documents into a specialized entailment ML model — a model trained to determine whether a piece of text is supported (entailed), contradicted, or neutral with respect to a reference document. Think of it as a dedicated lie-detector for individual sentences.
- Rewrite triggering: If the entailment model determines a fragment is contradicted by the retrieved evidence, that portion of the response is flagged for rewriting rather than just marked with a warning.
The key architectural insight is that the entailment model is separate from the generative model — it's a purpose-built verifier, not the same LLM being asked to double-check itself.
What this means for trusting AI-generated answers
For users of AI search products like Google's AI Overviews, this kind of system is directly relevant to one of the most-reported failure modes: AI answers that sound authoritative but are factually wrong. A real-time correction layer that silently rewrites bad output before display could meaningfully reduce those embarrassing and sometimes harmful errors without adding visible latency or friction to the experience.
For the broader AI industry, this patent signals that post-generation verification — rather than just better training — is becoming a serious engineering investment. Relying solely on a model's internal knowledge to be accurate is clearly insufficient; building a runtime fact-checking layer on top is a pragmatic hedge. If this ships into production, it would put Google's AI answers on structurally firmer ground than systems that rely on the LLM alone.
This is one of the more substantive AI reliability patents to come out of Google in recent memory — it's solving a concrete, well-documented problem with a specific architectural approach rather than vaguely claiming 'better AI.' The separation of verifier from generator is the right instinct, and the automatic rewrite trigger (not just a flag) suggests Google is aiming for something that works invisibly in production, not just in a research demo.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.