Google Patents a Way to Make AI Chatbot Answers Appear Faster
Nobody likes staring at a spinning cursor waiting for an AI to respond. Google's latest patent describes a way to start showing you an answer before the system has even finished thinking through the whole thing.
Why Google's AI reply feels instant before it's done
Imagine asking a friend a question and they say, 'Give me a second' — then say nothing for five full seconds before finally responding. That's what today's AI assistants can feel like. Google's patent targets exactly that gap.
Instead of making one big request to an AI and waiting for the full answer to come back, this system breaks the job into pieces. The AI starts generating the opening part of a response right away, and your screen starts showing it while the system is still working on the rest.
Think of it like a restaurant that brings out your salad while your entrée is still cooking, rather than making you wait until everything is plated. You still get the full meal — you just don't sit there staring at an empty table. The result is that the time between when you finish asking and when something useful appears on screen gets noticeably shorter.
How Google's split-prompt pipeline cuts wait time
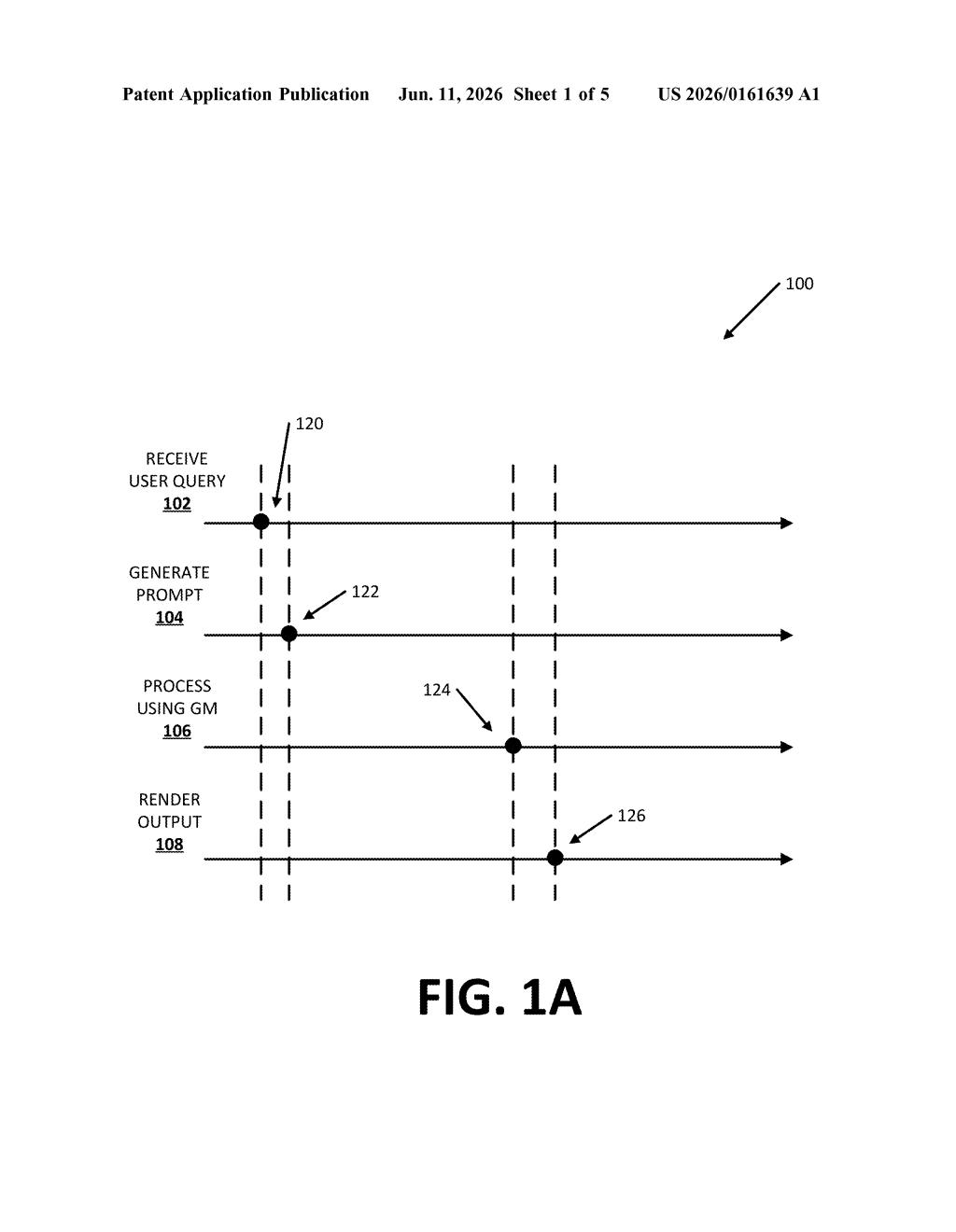
The patent describes a pipeline that runs two (or more) AI prompts in coordinated sequence rather than bundling everything into a single large request.
Here's the basic flow:
- When you submit a question, the system immediately fires off an initial prompt — a request to the AI to generate the opening portion of a response.
- Before that first answer chunk is even displayed, the system prepares an additional prompt asking the AI to generate the follow-on content.
- The first chunk gets rendered to your screen as soon as it's ready, and the second chunk follows right after — appearing seamlessly as one continuous reply.
The key insight is timing: the second prompt is kicked off before the first result is shown to you, so both generation jobs overlap in time. This is sometimes called pipelined execution — the same idea factories use when they start assembling the next car before the current one rolls off the line.
The patent allows either the same AI model or a different one to handle each prompt, which gives the system flexibility to route simpler or more complex sub-tasks appropriately. The prompts themselves are natural-language instructions, not hard-coded code commands, so the approach works across different generative model backends.
What faster AI replies mean for Google's assistant products
The gap between submitting a query and seeing a response — called time-to-first-token in AI engineering — is one of the biggest friction points in AI assistants today. Users perceive fast responses as more intelligent and trustworthy, so shaving even a second off that wait has real product impact. For Google, which is competing directly with ChatGPT and Microsoft's Copilot on assistant quality, this kind of perceived-speed improvement matters commercially, not just technically.
For you as a user, the upside is straightforward: conversations with Google's AI tools could feel more like talking to a person and less like submitting a form and waiting for a response email. This patent covers the back-end orchestration logic, so it could apply to Gemini, Google Assistant, or any other product Google builds on top of its generative AI stack.
This is a solid, practical engineering patent — not a moonshot. The split-prompt pipelining idea is conceptually simple, but the fact that Google is patenting the specific orchestration logic (including the timing of when each prompt fires relative to rendering) suggests it's heading toward real implementation. It's worth watching for Gemini users specifically, since perceived response speed is one of the clearest ways Google can differentiate from OpenAI's ChatGPT in everyday use.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.