Google Patents a Multi-Layer AI System for Grading Its Own AI Outputs
Getting AI to reliably judge whether AI-generated content is any good is one of the thorniest problems in the field. Google's latest patent describes a system that tackles it by running content through a panel of specialized evaluators before a master model hands down a final verdict.
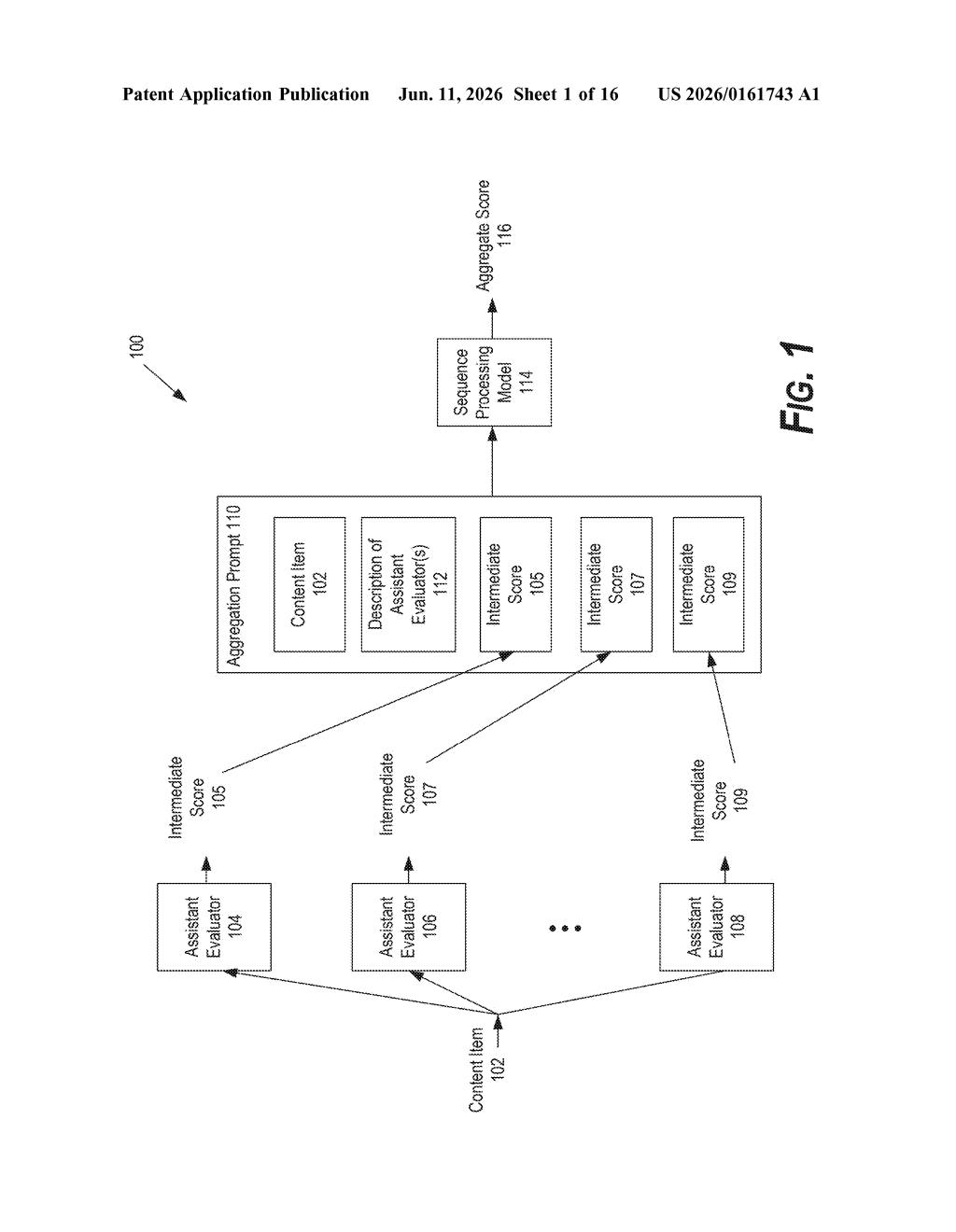
How Google's AI grades itself using a panel approach
Imagine a teacher who asks three subject-matter experts to each grade a student's essay on different criteria — grammar, accuracy, and tone — and then uses all three scores together to assign a final grade. That's essentially what this Google patent describes, but for AI-generated content.
Instead of relying on a single AI to judge whether a piece of content is good, the system sends it through several "assistant evaluators" — each one scoring the content on a specific dimension. Those individual scores then get handed off to a larger AI model, which weighs them all together and produces one aggregate score.
The practical goal is making AI quality checks more reliable and consistent — something Google almost certainly needs at massive scale, whether it's evaluating responses from its Gemini chatbot or outputs from other AI tools it builds internally.
How the assistant evaluators feed into a final LLM score
The patent describes a pipeline with three main stages:
- Content intake: A piece of content — a text response, an image caption, or some other AI output — is fed into the system for evaluation.
- Assistant evaluators: One or more specialized scoring models each assess the content independently, generating what the patent calls intermediate scores. Each evaluator has a description of what it's measuring (think: helpfulness, factual accuracy, safety, tone).
- Aggregation via a sequence processing model: A large language model (LLM) — an AI trained to process and generate text — receives an aggregation prompt that bundles together the original content, all the intermediate scores, and a description of each evaluator. The LLM synthesizes this into a single final score.
The key design choice here is transparency: by feeding the LLM a description of every evaluator alongside its score, the model can reason about why each score was assigned, not just what it was. That's more context than a simple average would provide, and it gives the LLM room to weight certain evaluators more heavily depending on the situation.
What this means for AI quality control at Google's scale
For anyone using a Google AI product — Gemini, AI Overviews in Search, or whatever comes next — the quality of responses depends heavily on whether Google can reliably detect bad outputs before they reach you. Manual human review doesn't scale; a single AI judge can be inconsistent. A structured, multi-evaluator pipeline with a final LLM arbiter is a serious engineering attempt to make that process more robust.
More broadly, AI evaluation (sometimes called "LLM-as-a-judge") is one of the hottest problems in the industry right now. Several companies are working on it, and patents in this space signal where resources are being committed. Google filing this suggests it's formalizing an evaluation architecture that may already be in use internally — or is being prepared for wider deployment.
This is unglamorous but genuinely important work. The reliability of every AI product Google ships depends on having a solid evaluation layer underneath it, and this patent describes a more principled approach than a lot of what's publicly documented. It's not a consumer feature — you'll never see an 'aggregate evaluator' button — but it's the kind of infrastructure that determines whether Gemini gives you a useful answer or a confident-sounding wrong one.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.