Samsung Patents a Double-Check System for AI Code Training Data
Garbage in, garbage out. Samsung's new patent tries to fix AI coding tools at the source by automatically weeding out training examples where the code and its description don't actually match.
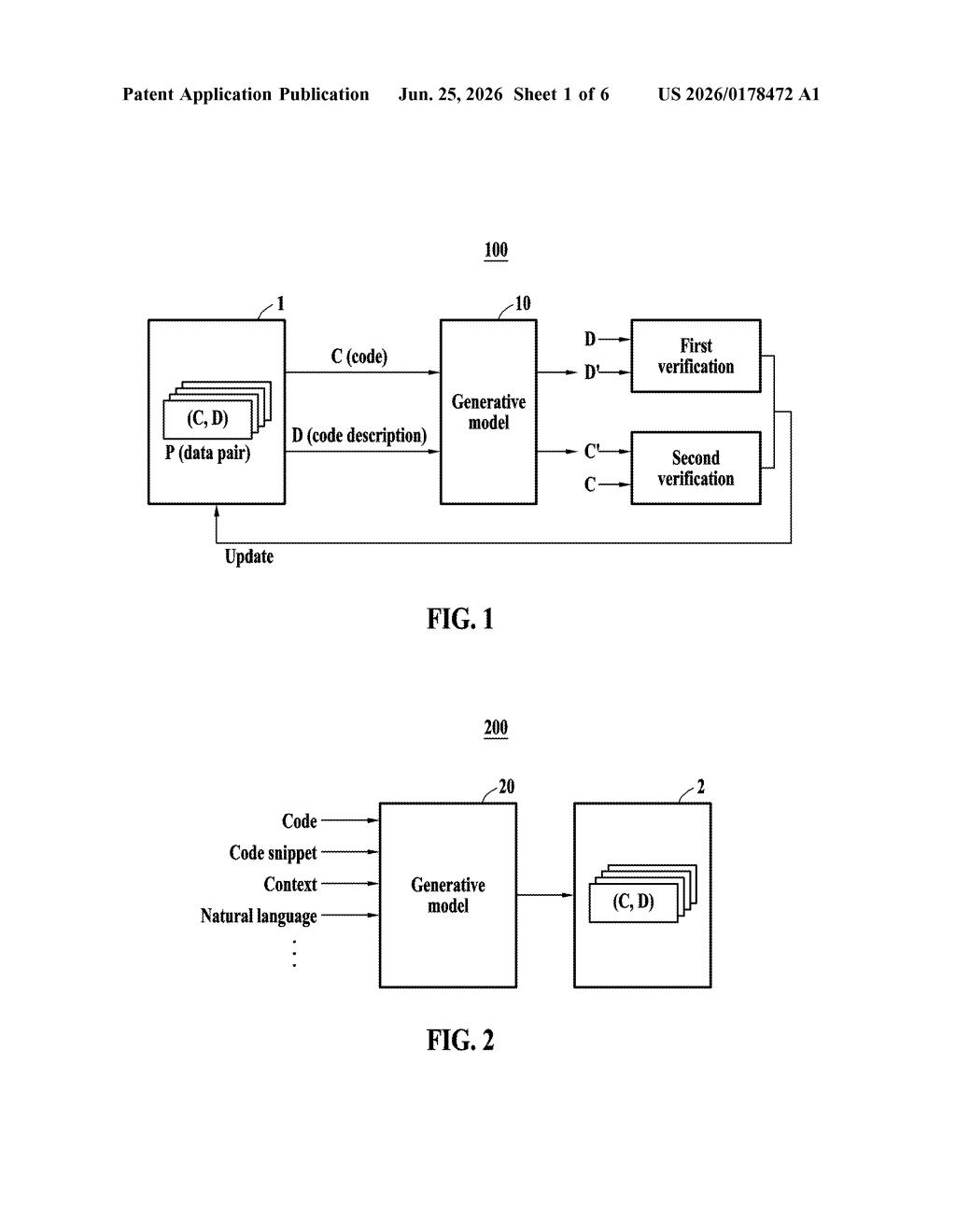
What Samsung's code-description matching system actually does
Imagine teaching someone a new language using a phrasebook where half the translations are wrong. That's roughly the problem Samsung is trying to solve for AI coding assistants.
When companies train an AI to write or understand code, they feed it thousands of examples: a snippet of code paired with a plain-language description of what that code does. If those pairs are mismatched or inaccurate, the AI learns bad habits. Samsung's patent describes a system that runs each pair through two separate tests to check whether the code and its description genuinely correspond to each other before that pair gets used in training.
Think of it as a two-way dictionary check: you look up a word to get a definition, then look up that definition to see if you get the original word back. If both directions work, the entry is probably correct. If either direction fails, the example gets flagged or removed.
How the two-pass verification loop filters bad data pairs
The patent describes a pipeline that processes a dataset of code-description pairs before they're used to train a language model.
- First verification: The system feeds a piece of code into an existing language model and asks it to generate a description of what that code does. It then compares that generated description against the human-written description already in the dataset. If they don't match closely enough, the pair is suspect.
- Second verification: The process runs in reverse. The system feeds the human-written description into the model and asks it to generate code. That generated code is then compared against the original code in the dataset. Again, a mismatch signals a problem.
- Dataset update: Based on the results of both checks, the dataset is updated, meaning bad pairs are corrected, flagged, or discarded before training begins.
The core idea is bidirectional consistency checking: a pair is only trustworthy if the relationship holds in both directions, from code to description and from description back to code. This is a data-quality step that runs before the actual model training, not during it.
What cleaner training data means for AI coding tools
AI coding assistants like GitHub Copilot or Samsung's own Gauss Code depend heavily on the quality of their training data. Low-quality code-description pairs are a known weak point in the field, and most fixes require expensive human review. A system that automates this cross-checking could let companies build cleaner training datasets at scale without proportionally increasing human labor.
For you as an end user, better training data means fewer moments where an AI coding tool confidently produces code that does something entirely different from what you described. That's a practical reliability improvement, even if the underlying mechanism is invisible to you when you're actually using the tool.
This is quiet infrastructure work, not a flashy product announcement. But data quality is one of the most persistent and underreported problems in AI development, and a scalable automated fix is genuinely useful. Samsung filing this suggests they're thinking carefully about the training pipelines behind tools like Gauss Code, which is a good sign for the reliability of whatever ships.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.