Samsung Patents a System That Makes AI Grade Its Own Homework
Samsung is patenting a method where an AI model acts as its own quality inspector — reading image-question pairs and deciding which ones are actually worth learning from.
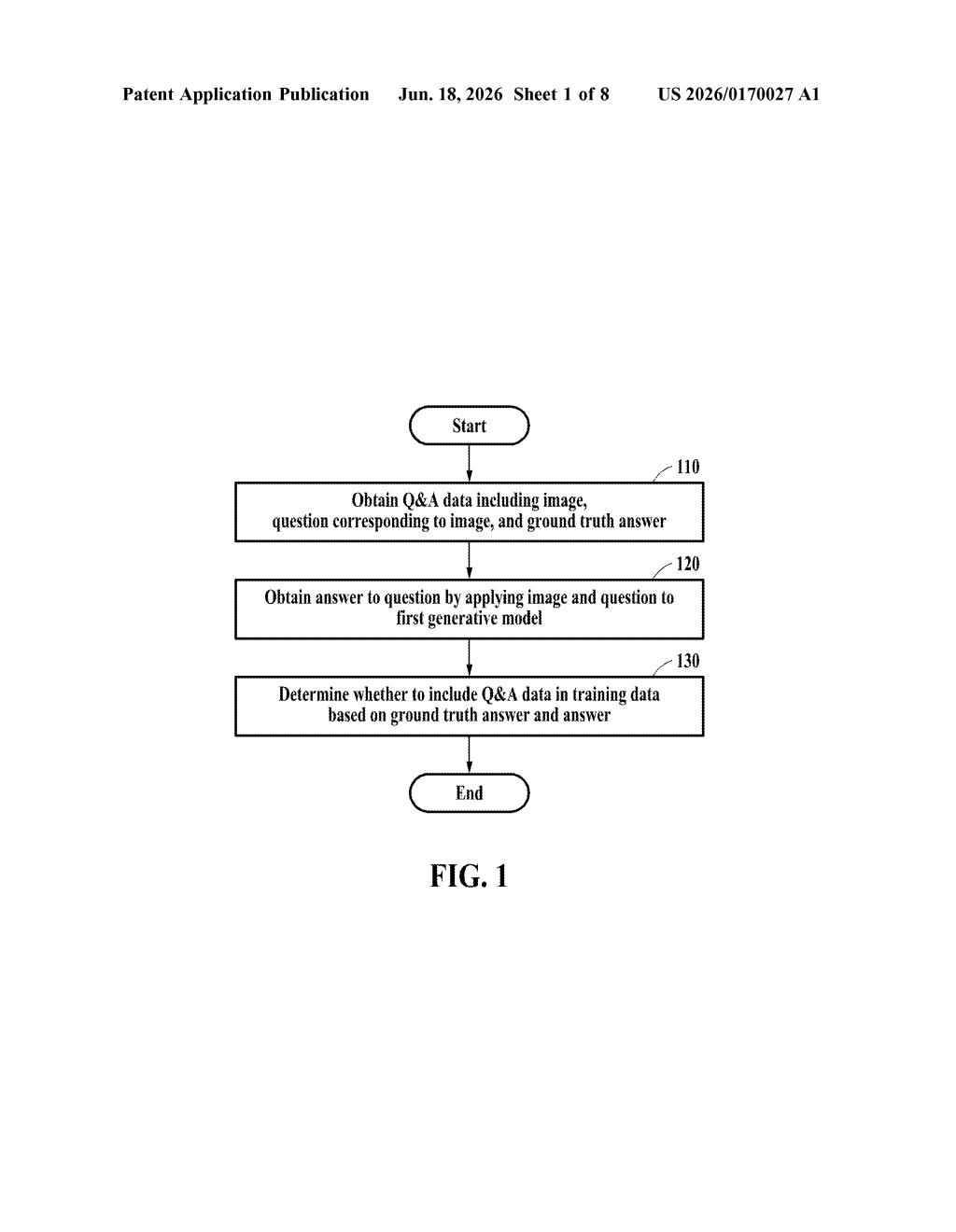
How Samsung's AI filters its own training images
Imagine you're studying for a test using a pile of practice questions, but half of them have wrong answers printed in the answer key. You'd pick up bad habits fast. AI models have the same problem: if you train them on low-quality or mislabeled examples, they learn the wrong things.
Samsung's patent describes a way to fix this automatically. Before a batch of image-and-question data gets used for training, a generative AI model looks at each image, reads the question, and produces its own answer. If that answer doesn't match the intended correct answer closely enough, the example gets cut from the training set.
The idea is to let the AI itself act as a filter — catching bad data before it ever shapes the model's behavior. It's a form of quality control that runs at machine speed, without a human having to review every example.
How the generative model scores each Q&A pair
The patent describes a three-step pipeline applied to multimodal Q&A data — datasets that pair an image with a question and a correct answer (called a ground truth answer).
- Obtain: The system pulls a Q&A record containing an image, a question about that image, and the known-correct answer.
- Generate: A first generative model — an existing AI, likely a vision-language model capable of understanding both images and text — receives the image and question and produces its own answer.
- Judge: The system compares the model's answer against the ground truth. If they don't align well enough, the Q&A pair is excluded from the training dataset.
The core insight is using one AI model as a gatekeeper for the data that will train another (or possibly itself in a later iteration). This is related to a broader technique sometimes called data curation via model feedback — using model output quality as a proxy for data quality.
The patent sits under USPC class 704/9, which covers natural language processing, confirming the focus is on text-and-image understanding models rather than, say, computer vision alone.
What self-filtering training data means for AI quality
Training data quality is one of the biggest hidden levers in AI performance. A model trained on clean, well-labeled examples consistently outperforms one trained on more but messier data. Right now, cleaning that data is expensive — it often requires human reviewers or elaborate rule-based scripts.
If Samsung can automate the filtering step with a generative model, it could cut the cost and time of preparing training data for its on-device AI features — the kinds of capabilities increasingly appearing in Galaxy phones and tablets. Better training data pipelines also make it easier to retrain or fine-tune models quickly when new product lines launch, which matters in a fast-moving market.
This is backend infrastructure work, not a consumer feature — but it's the kind of patent that pays off quietly in every AI product Samsung ships. Automated data filtering is a real bottleneck in model development, and having a defensible method for it is worth something. Not flashy, but genuinely useful.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.