Amazon Patents a Method That Cuts AI Training Time Across Multiple Servers
Training a massive AI model requires thousands of computers to constantly share data — and the way you route that data between machines can make or break how fast the whole job finishes. Amazon's latest patent tackles exactly that bottleneck.
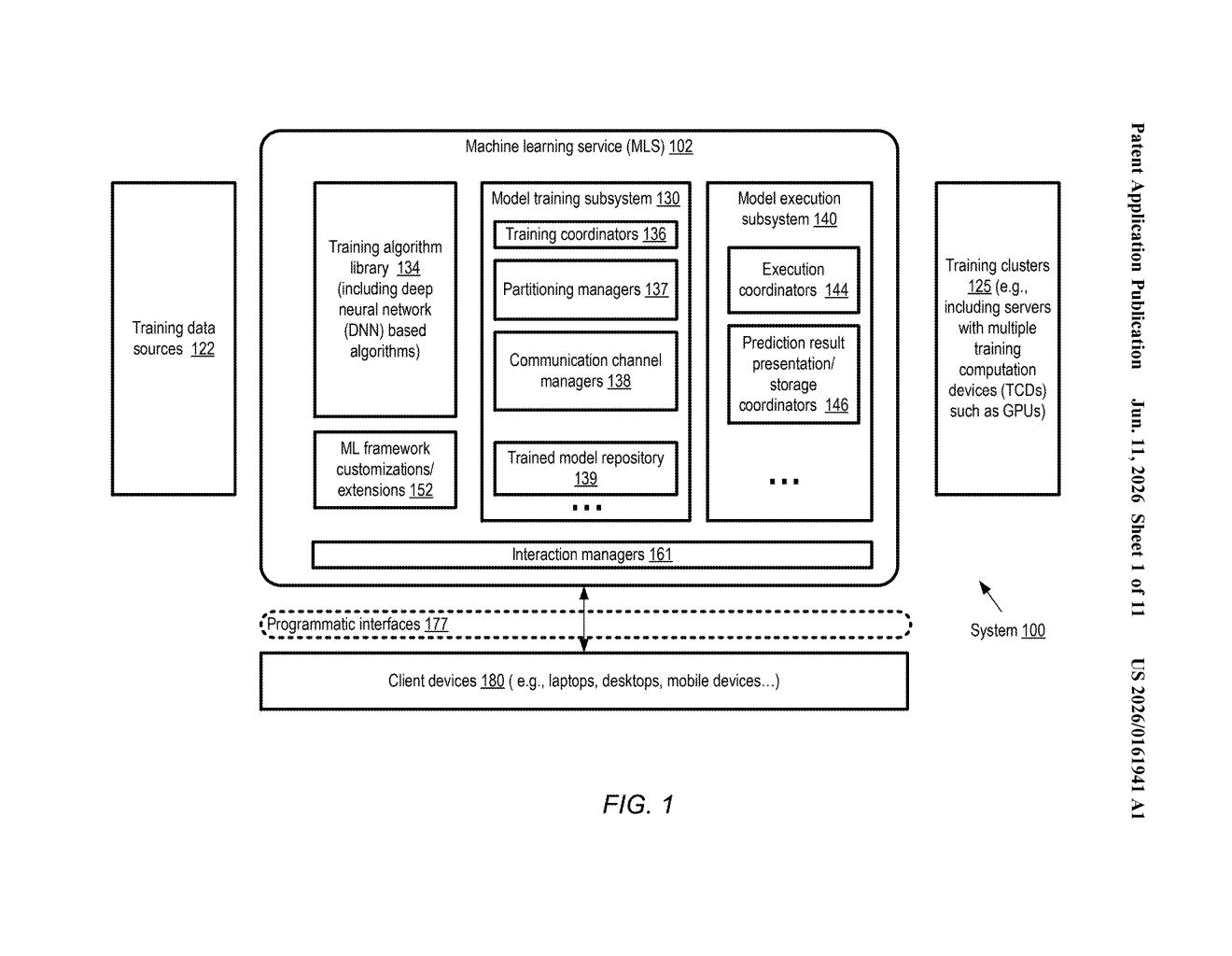
How Amazon's server-cluster training trick actually works
Imagine a relay race where some runners are on the same track (fast handoffs) and others are in different stadiums (slow handoffs). Training a big AI model across hundreds of servers has the same problem: computers inside the same physical server can swap data almost instantly, but sending that data to a computer in a different server across a data center is much slower.
Amazon's patent describes a system that splits a pool of servers into tightly-knit groups, where each group holds a complete copy of the model being trained. Within each group, the system uses a two-step communication strategy — first passing data between servers the slow way when necessary, then finishing the job the fast way between chips inside the same box.
The result is that the system avoids drowning the slow network links in unnecessary traffic. Each group trains on its own slice of data, syncs up its learning internally, and only talks to other groups when it absolutely has to. It's infrastructure plumbing, but the kind that determines whether training a model takes days or weeks.
How the multi-stage gather and gradient sync operate
The patent describes a distributed training architecture built for large-scale AI model training on Amazon's cloud infrastructure.
At its core, the system takes a large pool of servers and divides them into partition groups. Each partition group holds enough combined memory to store a full copy of the model's training state (the weights, optimizer data, and gradients the model needs to learn from each batch of data). This is an approach known as data parallelism with sharded state — rather than one machine holding the whole model, many machines each hold a piece, and together a group holds it all.
Training involves a multi-stage gathering process:
- Inter-server stage: Data sub-units are transferred across the slower network links connecting different physical servers.
- Intra-server stage: Those sub-units are then passed between chips within the same server using the much faster internal bus, without touching the slower external network again.
On top of that, the system runs multi-level gradient synchronization — a way of averaging out what each replica of the model learned from its slice of training data. The first level syncs gradients only within a partition group. The second level then syncs across groups. This two-phase approach reduces how much traffic has to cross the slow inter-server links, which is typically the biggest bottleneck in large training runs.
What this means for Amazon's AI cloud infrastructure
For Amazon Web Services, which sells AI training capacity as a core cloud product, squeezing more efficiency out of existing hardware directly translates to cost savings and faster turnaround for customers training frontier models. The patent essentially describes how to make a heterogeneous cluster — where not all network connections are equal — behave more like a well-organized pipeline.
For you as an AWS customer, better cluster utilization means potentially cheaper or faster training jobs. More broadly, this kind of infrastructure work is what determines whether the next generation of large AI models gets trained in two weeks or two months — and Amazon clearly wants to be the place where that happens.
This is deep infrastructure work — not a flashy consumer feature — but it's exactly the kind of patent that matters in the AI race. AWS's ability to train models more efficiently than competitors is a genuine competitive moat, and this patent shows Amazon thinking carefully about the physics of data center networking. Worth tracking if you follow cloud AI infrastructure.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.