Amazon Patents a Way to Shrink AI Tensor Data Before It Hits Memory
Every time a neural network passes data between layers, it has to write that data to memory — and memory bandwidth is one of the biggest bottlenecks in AI inference. Amazon's new patent tries to squeeze that data down using math that runs directly on the chip's existing arithmetic circuits.
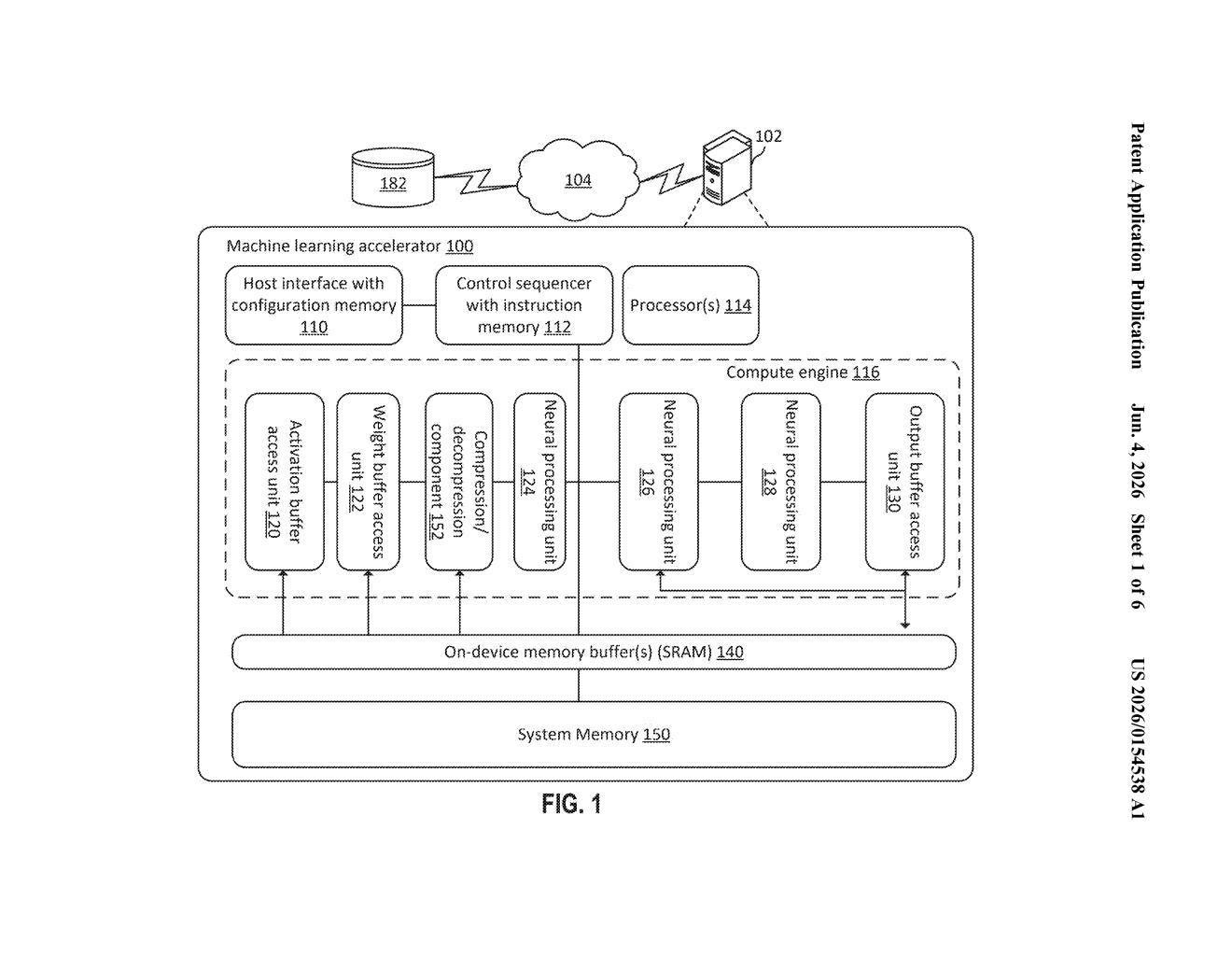
What Amazon's on-chip tensor compression actually does
Imagine a neural network as an assembly line where each station hands a tray of numbers to the next. The trays can get enormous, and there's only so much conveyor-belt space (memory bandwidth) to move them around. When a tray is too big, everything slows down.
Amazon's patent describes a way to compress those trays of numbers before they get stored, using a special mathematical formula that fits neatly on the chip's existing math hardware. The trick is that it's a nonlinear compression — meaning it doesn't squish all numbers equally. Values that are unusually large (called outlier activations) get handled differently than typical values, which helps preserve accuracy.
When the next layer of the network needs the data, a matching decompression formula reconstructs it — all without ever leaving the chip's fast on-chip memory (SRAM). The goal is fewer trips to slower, off-chip memory, which translates directly into faster and more efficient AI processing.
How the polynomial compression handles outlier activations
The patent targets a specific, well-known problem in running large neural networks on custom hardware: activation tensors (the big grids of numbers that flow between network layers) are often too large to all fit in fast on-chip SRAM, so they spill into slower DRAM, creating latency.
The system works like this:
- After a neural network layer finishes computing, its output tensor — including any outlier activation values (numbers far outside the normal range that standard linear quantization handles badly) — is fed into a nonlinear polynomial compression function.
- Crucially, that polynomial runs on the chip's existing vector addition and vector multiplication circuits, so no extra specialized hardware is needed.
- The compressed tensor is stored in SRAM. When the next layer needs it, a matching polynomial decompression function — also running on the same vector circuits — reconstructs the data before the matrix multiply happens.
The nonlinear approach is the key differentiator here. Standard compression in AI hardware often uses linear quantization (mapping floats to lower-bit integers), which can badly distort outlier values. A polynomial function can be shaped to handle those extremes more gracefully, trading a small amount of compute for meaningfully better numerical fidelity and higher compression ratios.
What this means for Amazon's AI inference hardware
Memory bandwidth is the silent tax on every AI inference job. If Amazon can compress activations aggressively without hurting model accuracy — and do it using circuits already present on their Trainium and Inferentia chips — they reduce DRAM traffic and potentially fit larger models (or larger batch sizes) into the same hardware envelope. That has direct cost implications for AWS customers running inference at scale.
It also signals that Amazon is investing in compression-aware compute at the hardware level, not just in software quantization tooling. That's a deeper, harder-to-replicate moat than library-level tricks that any cloud provider can copy.
This is genuinely useful chip-level engineering, not a defensive patent filing. Outlier activations are a real, documented pain point in quantizing large language models, and baking a nonlinear fix into the silicon's existing arithmetic units is an elegant solution. It's worth watching whether this shows up as a capability in future Trainium or Inferentia hardware specs.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.