Adobe Patents an Entity-Aware Video Reframing System for Smarter Cropping
Every time you crop a landscape video into a vertical TikTok or Instagram Reel, someone — or something — has to figure out what to keep in frame. Adobe's latest patent wants to make that process smarter by tracking subjects consistently across multiple frames before deciding how to reframe.
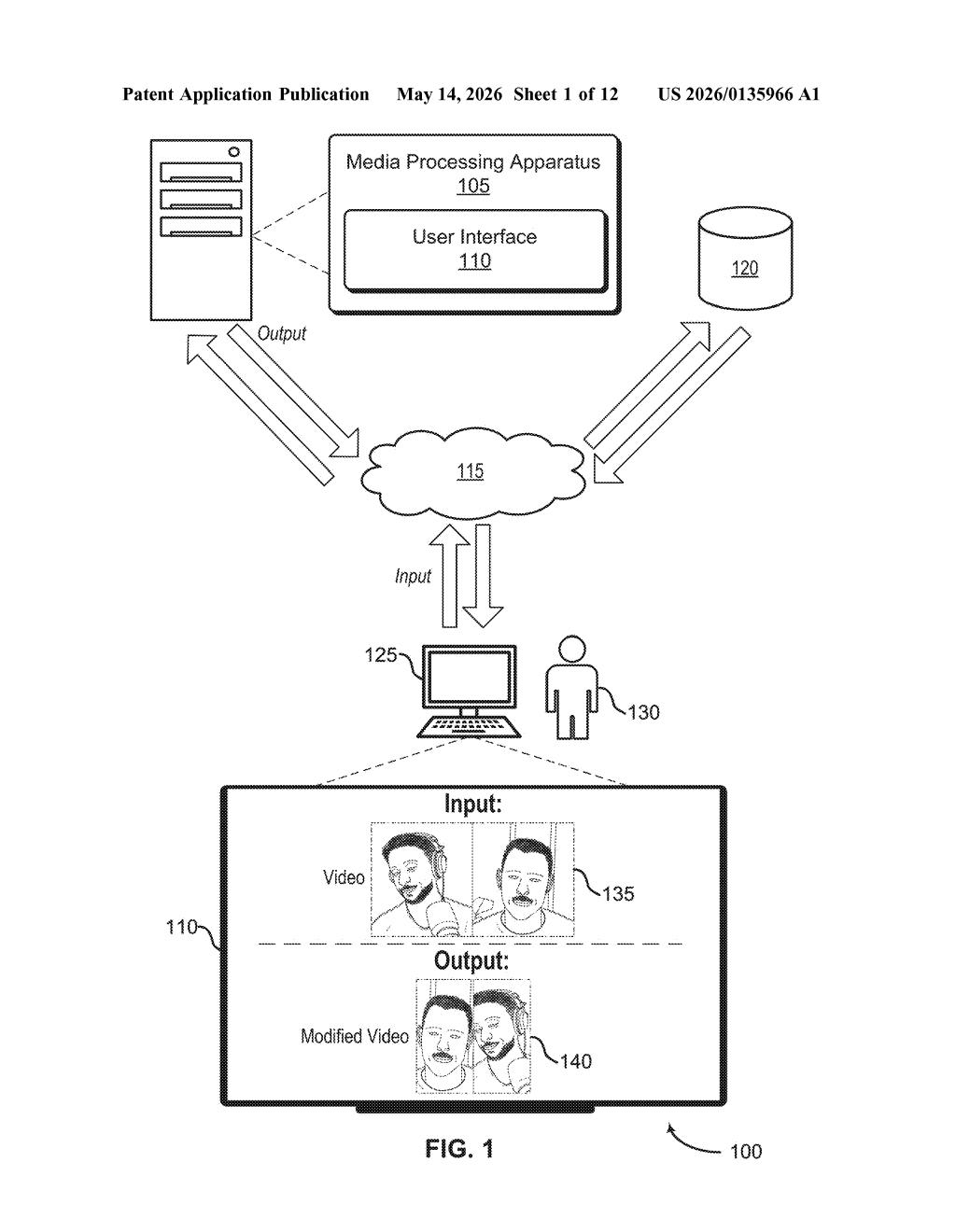
What Adobe's entity-aware video reframing actually does
Imagine you've shot a wide 16:9 interview video and now need to repurpose it as a vertical 9:16 clip for Instagram. If you just crop the center, you might cut off the speaker mid-gesture. Simple auto-crop tools often jump around awkwardly because they reframe each moment independently.
Adobe's patent describes a system that looks at a subject — a person, an object, anything it identifies as the key entity — across multiple frames at once before deciding where to place the crop window. By computing a single "combined bounding box" that accounts for where the subject appears across different moments in the video, the system can produce a crop that stays stable and intentional rather than jittery.
The result is a modified video in a new aspect ratio that keeps your subject properly framed throughout — without you having to manually keyframe the crop position. Think of it as auto-reframe that actually thinks ahead.
How Adobe's combined bounding box tracks subjects across frames
The patent describes a media processing method built around computing a combined bounding box — essentially a unified rectangular region that encompasses where a detected entity (a person, face, or object) appears across two or more video frames.
Here's the core pipeline:
- Entity detection: The system identifies a subject in individual frames of a source video that has a given aspect ratio (say, 16:9).
- Bounding box computation: Rather than computing a separate crop region per frame, the system merges positional data from multiple frames into one combined bounding box. This acts as a consensus region that balances where the subject is at different moments.
- Modified video generation: The output video is cropped and/or scaled to a different aspect ratio (say, 9:16 or 1:1) using that combined bounding box as the framing anchor.
The key technical insight is the multi-frame aggregation step. By looking at subject position across frames before committing to a crop region, the system avoids the erratic reframing behavior that plagues single-frame-at-a-time approaches. The patent is broad enough to cover still images referenced alongside video frames, and refers to a user interface component suggesting this is designed for interactive editing tools.
What this means for creators reformatting video content
For anyone producing content across multiple platforms — YouTube to TikTok, broadcast to mobile — reformatting footage is a constant, tedious chore. Tools like Adobe Premiere's existing Auto Reframe already attempt this, but the patent suggests Adobe is iterating on the underlying algorithm to produce smoother, more subject-aware results by pooling information across frames rather than acting moment-to-moment.
If this lands in Premiere Pro or Adobe Express, it could meaningfully reduce the manual cleanup work that creators currently do after running auto-reframe on talking-head videos, action shots, or interview footage. It's not a dramatic leap forward in AI video editing, but it's a targeted fix for a real and recurring pain point.
This is a focused, incremental improvement to a workflow problem that genuinely frustrates video creators every day. It's not a splashy AI feature — it's the kind of careful algorithmic refinement that makes existing tools noticeably less annoying. Adobe filing this suggests they're serious about shoring up the Auto Reframe experience, which has always been promising but inconsistent.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.