Google Patents a Multi-Stage AI Pipeline for Real-Time Image Restoration
Google has patented a clever iterative training method that progressively teaches smaller, faster AI models to restore degraded photos — with the end goal of running that enhancement engine on your smartphone in real time.
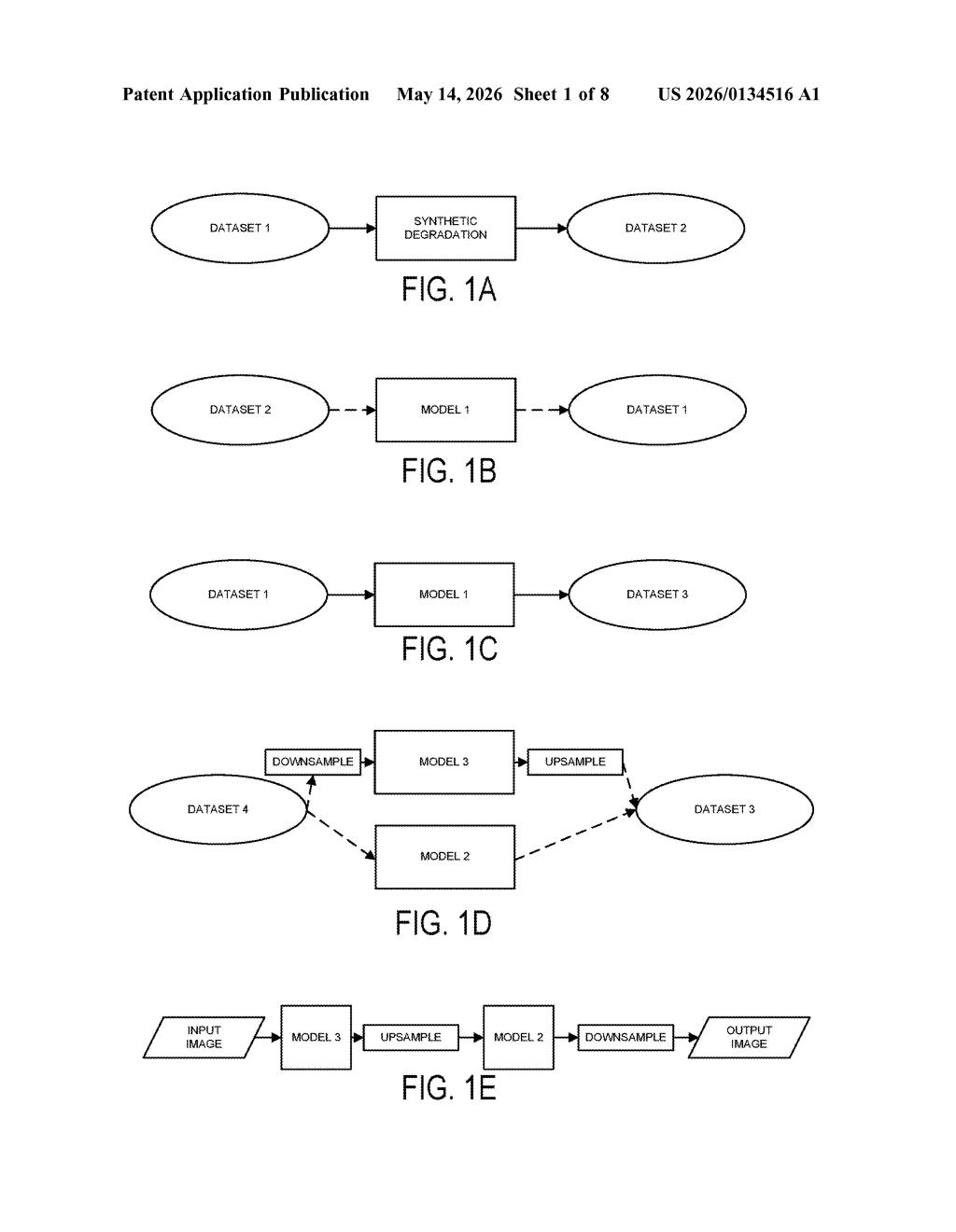
How Google's AI teaches itself to fix blurry photos
Imagine you snap a selfie in bad lighting and the result looks grainy and soft. Your phone's camera software tries to clean it up, but the AI doing that work has to be small enough to run quickly on device — which usually means it cuts corners.
Google's patent describes a smarter way to train those small, efficient AI models. Instead of just showing an AI examples of bad photos and good photos, Google builds a chain of progressively better AI teachers. Each teacher in the chain produces cleaner, sharper images that the next teacher learns from. By the end of the chain, you have a compact student model that has absorbed the knowledge of all its teachers — and can run on a phone.
The system specifically calls out front-facing smartphone cameras as a target, which makes sense: selfie cameras are typically lower quality than rear cameras, and improving them with on-device AI is a real competitive battleground right now.
Inside Google's cascading model training pipeline
The patent describes a multi-stage training pipeline built around synthetic degradation — the practice of taking pristine images and deliberately corrupting them (adding blur, noise, compression artifacts) so a model can learn to reverse the damage.
Here's how the stages stack up:
- Stage 1: Train a first model on high-resolution images that have been synthetically degraded. It learns to predict the clean original from the corrupted version.
- Stage 2: Run clean images through that first model to generate a new, "enhanced" dataset — images that are arguably even cleaner than the originals.
- Stages 3 & 4: Train two more models on this enhanced dataset — one at full resolution, one at a lower resolution — so the pipeline can handle different output sizes.
- Stage 5 (student distillation): Use the full pipeline's output to train a compact student model (think knowledge distillation — the small model mimics the big pipeline's results) that runs efficiently on-device.
The key insight is bootstrapping: each generation of model creates slightly better training data for the next, compounding quality gains without needing ever-larger datasets of real-world clean/degraded pairs, which are expensive to collect.
What this means for front-camera photo quality on Android
Front-facing camera quality is a huge differentiator in the mid-to-high-end Android market, and computational photography is increasingly where those gains come from. If Google can distill a high-quality multi-teacher restoration pipeline down to a model that runs at real-time speeds on a Pixel or partner device, that's a tangible user-facing improvement — sharper video calls, better selfies, cleaner low-light shots.
More broadly, the iterative self-improvement training strategy here sidesteps one of the hardest problems in image restoration: getting enough paired clean/degraded real-world data. Synthetic degradation has known limitations, but using each model's output to bootstrap the next stage is a pragmatic engineering answer to that problem.
This is solid, practical ML engineering — not flashy frontier research, but exactly the kind of methodical pipeline work that ends up shipping in a camera app update. The student-distillation step is the most commercially meaningful piece: it's the bridge between a powerful server-side model and something that actually runs on your phone without draining the battery. Worth tracking if you care about computational photography.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.