Adobe Patents a System for Auto-Generating Music-AI Training Data
Teaching an AI to connect music and language is only as good as the training data you feed it — and Adobe is patenting a way to manufacture that data at scale, automatically.
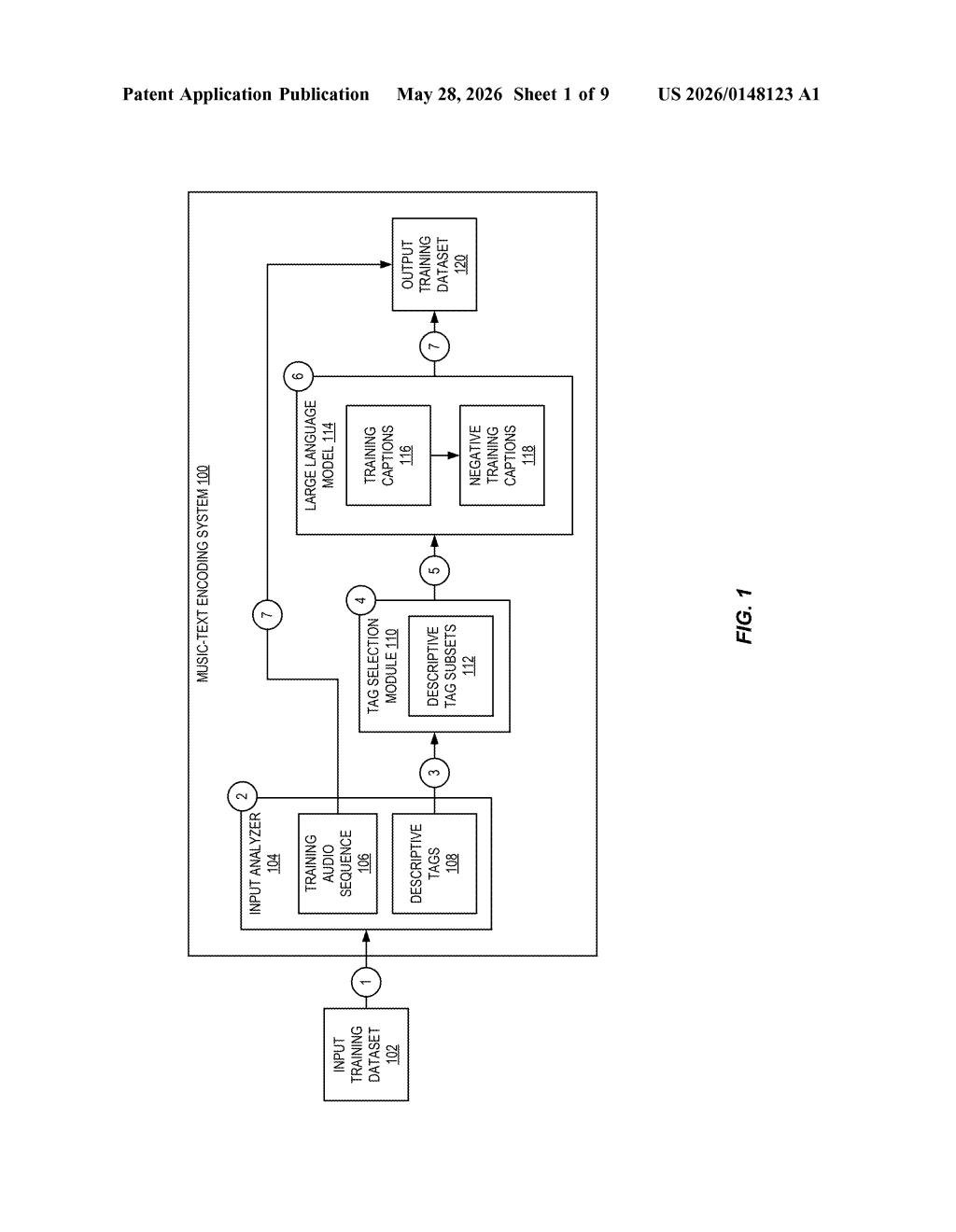
What Adobe's music-text embedding pipeline actually does
Imagine you want to build an AI that can match a piece of music to a text description, like finding a "tense, cinematic string piece" just by typing those words. To do that, you need thousands of examples pairing audio with accurate descriptions. Writing all of those by hand is expensive and slow.
Adobe's patent describes a pipeline that takes a song with a set of descriptive tags (things like "upbeat," "electric guitar," "120 BPM") and uses a large language model — like GPT — to automatically write many different natural-language captions for that same track, each one emphasizing different combinations of those tags. The result is a much richer, more varied set of training examples from a single piece of music.
The system also generates negative captions — deliberately wrong or misleading descriptions — so the AI learns not just what music does sound like, but what it doesn't sound like. That contrast is key to making the model precise and reliable.
How Adobe's LLM generates captions and negative pairs
The patent describes a training data generation pipeline for music-text embedding models — AI systems that learn to represent music and natural language descriptions in the same mathematical space so that similar concepts end up near each other.
Here's the core loop:
- Input: A training audio track plus a set of human-assigned descriptive tags (genre, tempo, mood, instrumentation, etc.).
- Tag subsets: The system randomly samples many different subsets of those tags — so one iteration might use "jazz, slow, piano" while another uses "jazz, piano, melancholic, 60s." This diversifies the angle from which each song is described.
- Caption generation: A large language model converts each tag subset into a fluent natural-language sentence or paragraph — the kind of description a human music editor might write.
- Negative caption generation: The LLM then deliberately modifies elements of those captions to produce incorrect descriptions — swapping instruments, changing tempo descriptors, flipping mood — creating hard negative examples (pairs that look plausible but are actually wrong).
The final training dataset combines positive captions (correct descriptions) and negative captions (plausible-but-wrong ones). Feeding both to a model during training — a technique related to contrastive learning — pushes the model to discriminate between genuinely matching and misleading music-text pairs, which makes it much more accurate.
What this means for Adobe's AI music tools
Adobe's creative tools — Premiere Pro, After Effects, Audition — increasingly rely on AI-assisted search and recommendation. A well-trained music-text embedding model could let editors search a stock music library by typing a mood or scene description and getting genuinely relevant results, not just keyword matches. That's a real workflow improvement for video editors.
More broadly, this patent sits in the infrastructure layer of AI development: it's about how you build the training data, not the model itself. If Adobe's approach produces better, more diverse training sets with less human labeling effort, it could give their audio AI a quality edge that's hard to replicate without the same pipeline. That's the kind of quiet competitive moat that doesn't show up in a product demo.
This is unglamorous but genuinely important work. The bottleneck in multimodal AI isn't usually the model architecture — it's data quality and diversity. Adobe is patenting a smart, systematic way to get more mileage out of a smaller set of tagged audio, and the negative-example generation step in particular reflects real sophistication about what makes contrastive training actually work.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.