Google Patents an AI That Reads Your Question Before Deciding Which Part of the Video to Search
Instead of feeding your entire video into one AI model and hoping for the best, Google's new patent describes a smarter dispatch system — one model figures out *what* you're asking and *which part of the video* matters, then hands off to a specialist to actually answer.
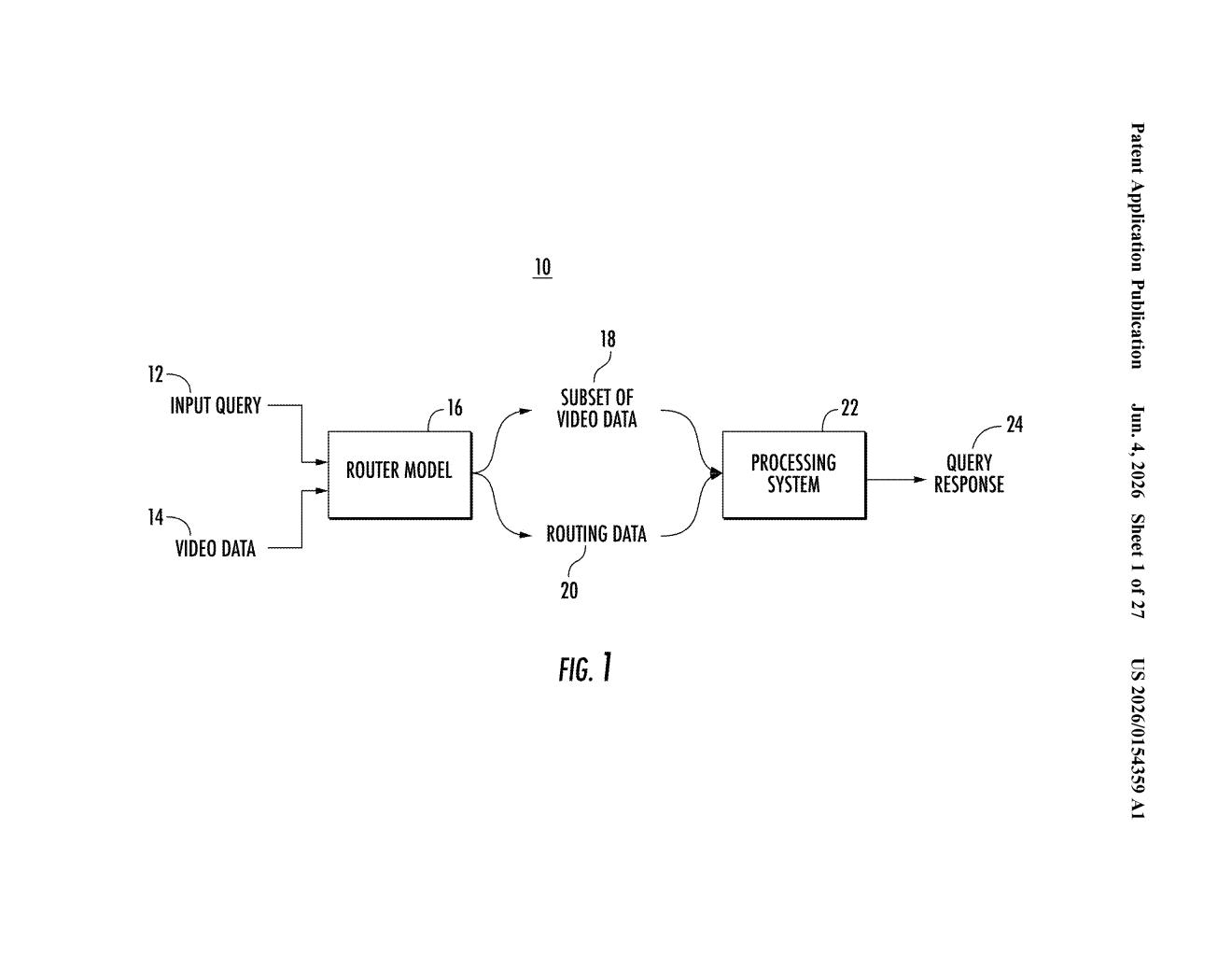
What Google's video question-routing system actually does
Imagine you're watching a two-hour cooking video and you pause at minute 47 to ask, "What temperature did she use for the oven?" A dumb system would scan the whole video. Google's patented approach is more like a smart triage nurse: it reads your question, notices when you asked it, and immediately clips out just the relevant segment — say, the five minutes before and after your pause — before handing that clip to the right tool.
The key insight is that context matters twice: what you asked and when you asked it, relative to what was on screen. That combo helps the system understand intent — are you asking about a visual detail, a spoken number, a name that appeared on screen? Each type of question gets routed to a different specialist model.
The final answer is then assembled by a language model that stitches everything together into a human-readable response, displayed right alongside the video.
How the router model segments video and picks a specialist
The patent describes a pipeline built around a router model — a machine-learned model whose sole job is orchestration, not answering. When you submit a query tied to a video, the router does four things simultaneously:
- Context detection: It logs which frames were on screen when you typed your question, establishing a temporal anchor in the video.
- Intent classification: It infers what type of data you want — visual info, audio detail, named entities, transcript text, or metadata.
- Clip segmentation: Based on your question and that temporal context, it carves out only the relevant portion of the video (frames, a spatial region, audio, or a transcript chunk).
- Model routing: It selects the best specialist model from a pool of options — different models presumably optimized for vision, speech, text, or entity recognition.
That specialist model then processes just the clip and returns structured feature outputs. A generative NLP model (think: a large language model) takes those outputs and writes a natural-language answer, which is rendered alongside the video in the UI.
The isolation of routing logic from answer generation is the architectural novelty here — it's a mixture-of-experts pattern (routing different inputs to different specialized models) applied specifically to the messy, multimodal problem of video QA.
What this means for AI assistants built around video
Video is now a primary information format — YouTube tutorials, recorded meetings, sports replays, surveillance footage — and the ability to ask natural-language questions about specific moments is genuinely useful. The bottleneck today is that most video AI systems either process the whole video (slow, expensive) or rely on transcripts alone (misses visual and audio cues).
Google's router approach trades brute-force for precision. By classifying intent first, the system can avoid sending a "what color is the shirt?" question to a speech model, and avoid burning compute on irrelevant video segments. For Google's products — YouTube, Google Meet, Google Search with video — this kind of efficient video QA infrastructure is a plausible near-term integration, especially as on-device and edge compute constraints make efficiency more pressing.
This is a solid systems patent for something Google clearly needs to build at scale. The routing architecture is genuinely sensible — applying mixture-of-experts logic to video QA is a practical engineering choice, not just a paper idea. Whether the patent itself is novel enough to hold up is a separate question, but the problem it's solving (efficient, context-aware video Q&A) is real and the approach is well-specified.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.