Google's New Patent Lets You Point at Something, Say What You Want, and Watch Your Phone Handle It
Point at something, say what you want done with it, and an AI figures out which app to open and what action to take — all triggered by one continuous gesture. That's the core idea in Google's latest patent.
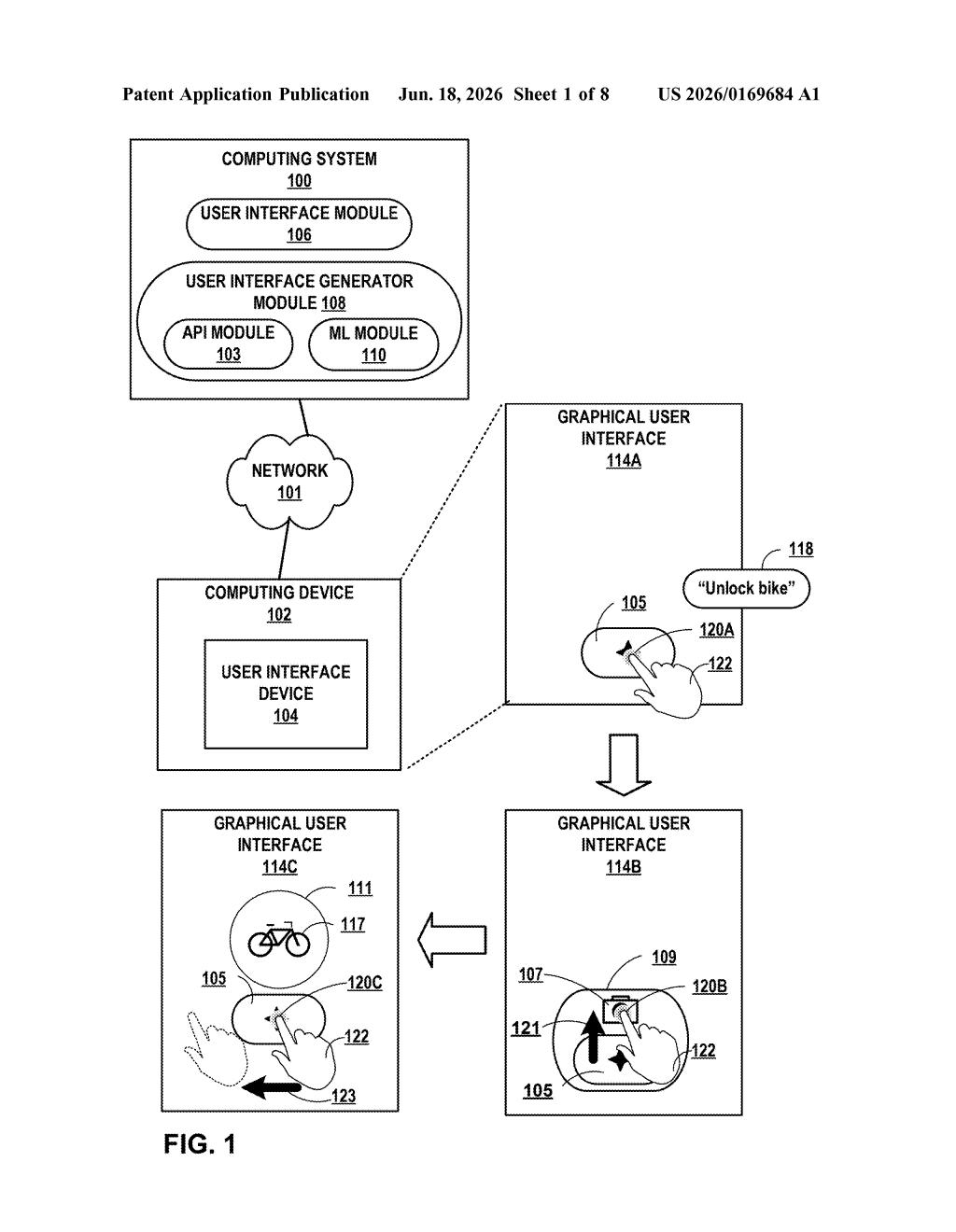
What Google's gesture-plus-voice-plus-camera combo actually does
Imagine you're holding your phone, you spot a restaurant menu on the table, and you want to know if it has anything you can eat. Right now, you'd take a photo, open an app, paste the image, type a question. Google's patent describes a much shorter path: one gesture triggers your phone to simultaneously listen to what you say and capture what you're looking at, then an AI works out which app can actually help.
The key phrase is "single, continuous gesture." You don't tap a camera button, then switch to a voice assistant, then choose an app. One movement kicks off the whole chain. The AI reads your spoken command and the image together — not separately — to decide what to do.
The result could be a pop-up card from the right app, a suggested action inside that app, or the app just launching and doing the thing automatically. Google is essentially patenting the idea of a unified input moment that replaces the tap-tap-switch-type routine most of us go through today.
How the AI matches your gesture and words to the right app
The patent describes a computing system — likely a phone or tablet — that listens for a specific gesture. Once detected, that gesture simultaneously triggers two inputs: a natural language command (what you say out loud) and an image input (what the camera captures at that moment).
Those two signals are fed together into a machine learning model (an AI trained to understand the relationship between words and visual content). The model doesn't process them one at a time; it reasons about both at once to figure out which installed app has the right capability to handle your request.
The system then generates one of three kinds of output:
- A graphical component — essentially a card or widget from the relevant app
- A suggested action — the app's best next step, surfaced without you opening it
- Full automatic execution — the app just runs the task based on what you said and showed it
The claim language specifically protects the gesture-as-trigger mechanism, meaning the whole chain — gesture, dual input, AI routing, app output — is treated as a single interaction rather than a series of manual steps.
What this means for how you'll interact with Android and Pixel
For everyday users, this is about collapsing several steps into one. The friction of switching between a camera, a voice assistant, and an app is real — and it's why most people don't bother. If Google ships something close to what this patent describes, it could make AI-assisted tasks feel immediate rather than effortful, especially on Pixel devices where Google controls both hardware and software.
Strategically, this positions Google's on-device AI as a universal interpreter — not just a search tool or a voice assistant, but something that understands the context you're physically pointing at. That's a direct challenge to the kind of ambient, context-aware computing that Apple has been chasing with its own visual intelligence features in iOS 18.
This is one of the more interesting interaction-design patents Google has filed in a while. The "single continuous gesture" framing is doing real work here — it's not just a technical detail, it's the whole UX philosophy. Whether it ships in anything recognizable is another question, but the direction is clear: Google wants AI to feel reactive to your physical moment, not something you have to deliberately invoke.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.